参考代码:openpose
1. 概述
导读:这篇文章提出了一种bottom-up的2D图像多人关键点(躯干/手脚/面部,使用掩膜控制训练整合数据集)检测算法,这样使得整体网络的运算时间并不与图像中人数呈现显著相关的关系。在这篇文章中提出了PAFs(Part Affinity Fileds)(用于去编码关键点的位置与方向信息),用于去建模每个部位之间的相互关系,并且文章发现同时去优化PAFs和人体的部位并不是最优的选择,先去优化PAFs而不是同时去优化它们两个能带来更好的性能表现。这篇文章的方法也是涵盖了人体大致的关键点检测问题,还是很具有意义和借鉴价值的,值得细读(在1080 Ti上能跑到22FPS,VGG19)。
2D图像人体姿态估计面临的问题:
- 1)输入图像中的人数,呈现的姿态与大小都是不固定的;
- 2)人与人之间是存在接触遮挡等情况的,这就导致较为复杂的空间关系;
- 3)图像中人数的增加会使得整个算法的运算时间也增加;
现有的人体关键点的检测方法分类:
- 1)top-down:这类方法是首先运行一个人检测器,之后在每个人的基础上计算得到人体姿态,这样好处是能够很好使用现有的一些检测技术,并且效果也不错。但是由于人与人之间复杂的空间关系使得检测器是也很难准确框出每一个人,而且随着人数的增加对应的整体算法运行时间也会成比例增加;
- 2)bottom-up:这类方法是首先检测整幅图中所有人的关键点信息,之后将这些关键点组合起来从而得到一个人的关键点,这样就使得整体关键点检测与人数解耦,这样可以加快整体的速度;
而文章的方法是通过bottom-up的方式进行关键点检测的,下图中上半部分是在2D图像中多人关键点检测的结果,下半部分是文章使用PAFs得到的关键点之间的联系关系图,用于将不同位置的关键点连接起来。

2. 方法设计
文章的整体算法流程见图2所示:

对于一张输入的图像
,首先会在其基础上预测出关键点的特征图
,分别代表不同的关键点部位。之后会预测出关键点之间关系的向量
,对应的就是图中b,c部分。最后在PAFs的基础上使用贪心算法得到人体关键点的连接关系。
2.1 网络结构
文章的提出的关键网络结构部分见下图所示:

这里使用迭代的形式
递归优化关键点间关系预测与关键点定位(在相同条件下文章的实验结果表明将关系预测放在定位之前能带来更好的性能,反过来则不能带来结论就不成立),并且在对应的部分都有设置损失函数进行监督,从而级连优化回归的目标。而且文章还将之前论文中的
的卷积替换成为了类似DenseNet的3个
卷积的形式,从而使得在网络的精度和速度上均有所改善。

2.2 优化关键点定位于关联性
这篇文章使用VGG-19作为其backbone,其产哼的特征图为
,之后送入关键点关联性预测得到
,对应的上角标代表的是不同的迭代优化轮数。之后的关键点关联性采用迭代优化的形式进行:
而关键点的定位也是跟关键点关联性预测类似的过程,完成最后的关联性预测之后于之前的特征整合就可以用来预测关键点:
那么对于后续阶段关键点定位的预测迭代形式为:
文章回归用的损失函数是
损失函数,并且由于文章是联合多个数据集进行训练的,因而会存在一些关键点不存在的问题,为此提出了一个二值掩膜
,其在没有标注的地方将其值设置为
。因而文章的关键点相关性与关键点位置的损失函数可以定义为:
那么总的损失函数就是两者的和:
3. 标注生成
3.1 关键点的标注
这篇文章中关键点的标注是使用高斯函数进行的,那么对于关键点坐标为
其对应的回归目标为
,则其计算表达为:
那么存在相邻关键点重叠的时候怎么办呢?文章中是使用最大值优先原则:
使用最大值优先原则而不是平均值,这样可以使得相邻的关键点区分度得到保留,见下图所示:

3.2 关键点间相关性描述
对于关键点间关系的描述文章参考了一些策略,并得出一种切实可行的方案,见下图所示:

在图a中呈现了很多的关键点,那么怎么才能将这些关键点与单独的人关联起来,并且建模关键点之间的联系?一个简单的思路就是在关键点之间选择一个中间锚点,如图b所示。但是这种方法在人较为密集的时候就会存在关联错误的情况,导致关联错误的原因有:
- 1)只编码了关键点的位置信息,但是却没有编码关键点间的方向信息;
- 2)将关键点的依赖范围从肢体区域收缩到了一个点上,并没有考虑更大范围的信息;
对于这样的问题文章提出了图c中的策略,就是去建模关键点的位置与方向信息,也就是文章所说的PAFs。考虑下图中的人体肢体:

图中有两个关键点
和
,若是其中在肢体上存在一个点
起对应的标注值为
,它是一个从点
到
的单位向量(用于表示关键点之间的方向信息),而其它的位置值就是0了。
那么对于在肢体上的点
其对应生成的标注信息可以描述为:
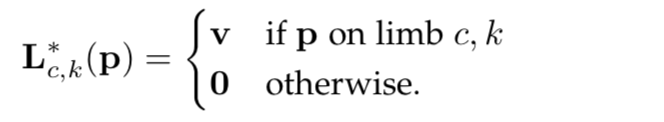
其中,
是一个单位向量,但是对于这样的标注点其也是有一个范围限定的,文章中将其限定为:
其中,
代表的是像素的距离,
是肢体的长度,
代表的是不同的人。那么对应的关键点相关性信息标注(回归目标)就可以描述为(归一化):
在进行infer的时候文章是通过预测出来的PAFs和关键点计算关键点之间的度量,因而对于两个预测出来的关键点
,它们之间的度量可以描述为:
其中,
,两个点插值得到的结果。
3.3 在PAFs基础上推理结果
在得到一堆关键点之后,可以通过上述内容中的计算公式得到任意两个关键点之间的相关度信息,但是怎么在这么多关键点之间寻找合适的组合分配仍然是一个很难的问题,见下图6(a)所示:

在文中用
表示两个关键点是否连接,那么对于整个检测出来的关键点其需要优化的模型为:

但是直接去解决上面的问题是NP难的,为此文章将这个问题使用两个简化的问题并使用贪心的策略去解决它。文中将原问题做了如下的简化:
- 1)从原有的匹配图里面选择最小数量的变从而获取spanning tree skeletion,从而避免考虑整个图,减少复杂度;
- 2)再在上面的基础上对其进行分解得到两两配对的子图;
之后文中提到是使用贪心的算法进行关键点的连接,并且还做了一些关键点过滤的操作。
4. 实验结果
COCO test-dev上的性能表现:
