1. KNN学习
K近邻(K-Nearest Neighbor,KNN)学习是一种常用的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k 个训练样本,然后基于这k 个" 邻居"的信息来进行预测。通常, 在分类任务中可使用"投票法", 即选择这k 个样本中出现最多的类别标记作为预测结果。一句话可以概括为“近朱者赤,近墨者黑”。
KNN没有显式的训练过程,它在训练阶段仅仅是把样本保存起来,在此阶段基本上不会耗费时间。在收到样本后再进行处理,具体处理方式后面会讲到。KNN中最重要的一个参数就是K的取值,K取不同的值,结果可能会有所区别。
接下来,看一看KNN“投票法”的具体使用,如图所示,当K=1时,分类器将测试样本判别为正例;当K=3时,分类器将测试样本判别为负例;当K=5时,分类器又将其判别为正例。由此可见,KNN的选取是非常重要的。

2. KNN算法的数学表达
2.1 输入与输出
输入:假设训练数据集D现在有m个样本,每个样本对应一个类别y,且每个样本有n个特征,则训练数据集D可以表示为:
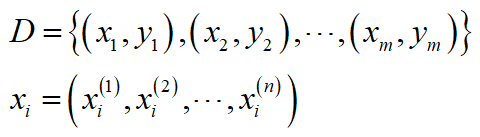
式中,
为样本的特征向量,
为样本所对应的类别。
输出:样本x所属的类别y
2.2 距离度量
前面我们说过,KNN是基于某种距离度量找出训练集中与测试集样本最靠近的k 个训练样本,然后再通过找出的这K个训练样本利用“投票法”来判断测试样本的类别。那么这个距离度量我们一般选择用
距离作为其距离度量,其计算公式如下:
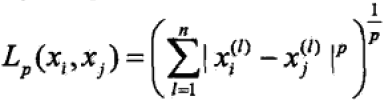
式中,
=(
,
,……,
),
=(
,
,……,
),
>=1。
当
=1时,此时的
距离被称为曼哈顿距离(Manhattan distance),其计算公式如下:
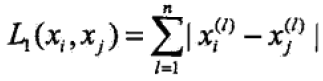
当
=2时,此时的
距离被称为欧氏距离(Euclidean distance),其计算公式如下:
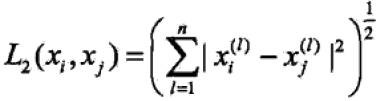
综上所述,当p值不同时,那么紧邻点的选取可能存在一定的差别,分析问题时,要具体问题具体分析,根据数据集进行多次试验,选取合适的距离公式。
2.3 K值的选取
K值的选择会对KNN算法的辨识结果产生非常大的影响。K值较小时,可能会使整体的模型变的复杂,容易发生过拟合;但是选取的K值较大时,可能会使整体的模型变的简单,容易发生欠拟合。因此,在实际应用中,一般会选取比较小的值,通过实验验证其最优的K值。
3. KNN分类的工作原理总结
(1)假设有一个带有类别的的训练样本集D,每个样本包 n 个特征;该样本集中包含每个样本和其所属类别的对应关系,详情参考本文第一个公式。
(2)输入一个类别未知的新样本(测试样本),将新样本的每个特征与训练样本集中样本对应的特征进行比较,其具体过程如下:
1.选取
距离(一般默认欧氏距离),计算测试样本与训练样本集中每个样本的欧氏距离。
2.对第一步所求得的欧氏距离进行从小到大的排序,越小表示越相似。
3.选取前K个距离最近的样本数据所对应的类别标签
(3)求解K个分类标签中出现次数最多的类别标签作为测试样本的类别。
4. KNN分类的优缺点
优点:模型简单易懂,精度较高,对异常值不敏感,无需训练,无需估计参数。
缺点:计算量大,耗费时间长,每次分类都需要重新计算;无法处理数据集分类不平衡的问题。