������Ŀ��A Global Geometric Framework for Nonlinear Dimensionality Reduction
������Դ:Science 290, 2319 (2000);
A Global Geometric Framework for Nonlinear Dimensionality Reduction
�����Խ�ά��ȫ�ּ��ο��
Joshua B. Tenenbaum,1* Vin de Silva,2 John C. Langford3
Scientists working with large volumes of high-dimensional data, such as global climate patterns, stellar spectra, or human gene distributions, regularly confront the problem of dimensionality reduction: ?nding meaningful low-dimensional structures hidden in their high-dimensional observations. The human brain confronts the same problem in everyday perception, extracting from its high-dimensional sensory inputs��30,000 auditory nerve ?bers or 106 optic nerve ?bers��a manageably small number of perceptually relevant features. Here we describe an approach to solving dimensionality reduction problems that uses easily measured local metric information to learn the underlying global geometry of a data set. Unlike classical techniques such as principal component analysis (PCA) and multidimensional scaling (MDS), our approach is capable of discovering the nonlinear degrees of freedom that underlie complex natural observations,such as human handwriting or images of a face under different viewing conditions. In contrast to previous algorithms for nonlinear dimensionality reduction,our sef?ciently computes a globally optimal solution, and, for an important class of data manifolds, is guaranteed to converge asymptotically to the true structure.
��ѧ�����ڴ���������ά����ʱ����ȫ������ģʽ�����ǹ����������ֲ��ȣ�����������ά�Ƚ��͵����⣺�ڸ�ά�۲�����У��������������е�������ĵ�ά�ṹ���������ճ���֪��Ҳ����ͬ�������⣬�Ӹ�ά�й���������ȡ��30,000��������Ԫ��106��������ά�������������ٵĸ�֪������������������������һ�ֽ��ά�Ƚ�������ķ������÷���ʹ�����ڲ����ľֲ�������Ϣ��ѧϰ���ݼ��ĵײ�ȫ�ּ��Σ������ɷַ���(PCA)�Ͷ�ά������(MDS)�Ⱦ��似����ͬ�����ǵķ����ܹ����ָ��ӵ���Ȼ�۲������̺��ķ��������ɶȣ����粻ͬ�۲������µ�����ʼ�������ͼ���������ķ�����ά�Ƚ����㷨��ȣ����ǵķ����ܹ������һ��ȫ�����ŵĽ⣬���Ҷ���һ����Ҫ�����ݱ�������֤��������������ʵ�ṹ��
A canonical problem in dimensionality reduction from the domain of visual perception is illustrated in Fig. 1A. The input consists of many images of a person��s face observed under different pose and lighting conditions, in no particular order. These images can be thought of as points in a high-dimensional vector space, with each input dimension corresponding to the brightness of one pixel in the image or the firing rate of one retinal ganglion cell. Although the input dimensionality may be quite high (e.g., 4096 for these 64 pixel by 64 pixel images), the perceptually meaningful structure of these images has many fewer independent degrees of freedom. Within the 4096-dimensional input space, all of the images lie on an intrinsically three dimensional manifold, or constraint surface, that can be parameterized by two pose variables plus an azimuthal lighting angle. Our goal is to discover, given only the unordered high-dimensional inputs, low-dimensional representations such as Fig. 1A with coordinates that capture the intrinsic degrees of freedom of a data set. This problem is of central importance not only in studies of vision (1�C5), but also in speech (6, 7), motor control (8, 9), and a range of other physical and biological sciences (10�C12).
ͼ1��A���Ӿ���֪�����һ�����͵�ά�Ƚ������⡣��������ڲ�ͬ���ƺ������������ض�˳��۲쵽����������ͼ����Щͼ����Ա���Ϊ�Ǹ�ά�����ռ��еĵ㣬ÿ������ά�ȶ�Ӧͼ����һ�����ص����Ȼ�һ������Ĥ��ϸ���ķŵ��ʡ���Ȼ����ά�ȿ����൱�ߣ����磬������Щ64x64���ص�ͼ����˵��Ϊ4096������Щͼ��ĸ�֪����ṹ���н��ٵĶ������ɶȡ���4096ά������ռ��ڣ����е�ͼ��λ��һ�������ϵ���ά�棬����˵Լ���棬���������������Ʊ�������һ����λ���սǽ��в����������ǵ�Ŀ���ǣ�ֻ��������ĸ�ά���룬������ͼ1�е�A�����ĵ�ά��ʾ����������Բ����ݼ��Ĺ������ɶȡ�������ⲻ�����Ӿ�(1-5)���о��о��к�����Ҫ�ԣ�����������(6��7)���˶�����(8��9)�Լ�һϵ�����������������ѧ(10-12)��Ҳ���к�����Ҫ�ԡ�
======================================================================================================


Fig. 1. (A) A canonical dimensionality reduction problem from visual perception.The input consists of a sequence of 4096-dimensional vectors, representing the brightness values of 64 pixel by 64 pixel images of a face rendered with different poses and lighting directions. Applied to N =698 raw images,Isomap(K=6) learns a three-dimension al embedding of the data��s intrinsic geometric structure. A two-dimensional projection is shown, with a sample of the original input images (red circles) superimposed on all the data points (blue) and horizontal sliders (under the images) representing the third dimension. Each coordinate axis of the embedding correlates highly with one degree of freedom underlying the original data: leftright pose (x axis, R =0.99), up-down pose (y axis, R =0.90), and lighting direction (slider position, R =0.92). The input-space distances dx(i,j) given to Isomap were Euclidean distances between the 4096-dimensional image vectors. (B) Isomap applied to N =1000 handwritten ��2��s from the MNIST database (40). The two most signi?cant dimensions in the Isomap embedding, shown here, articulate the major features of the ��2��: bottom loop (x axis) and top arch (y axis). Input-space distances dx(i,j) were measured by tangent distance,a metric designed to capture the invariances relevant in handwriting recognition (41). Here we used e-Isomap (with ��=4.2) because we did not expect a constant dimensionality to hold over the whole data set; consistent with this, Isomap ?nds several tendrils projecting from the higher dimensional mass of data and representing successive exaggerations of an extra stroke or ornament in the digit.
ͼ1.(A) һ�����Ӿ���֪�����Ĺ淶ά�Ƚ�������.������4096��ά�ȵ������������,�����Բ�ͬ���ƺ��շ�����Ⱦ���沿��64���س�64����ͼ�������ֵ��Ӧ����N=698��ԭʼͼ��Isomap(K=6)����ѧϰ�������ڼ��νṹ����άǶ�롣ͼ����ʾ��һ����άͶӰ��ԭʼ����ͼ�������������ɫԲȦ�������������ݵ㣬����ɫ���ϣ�ˮƽ���飨ͼ���·�����������ά��Ƕ���ÿ����������ԭʼ���ݻ�����һ�����ɶȸ߶���أ����ҵ����ƣ�x�ᣬR=0.99�����������ƣ�y�ᣬR=0.90�����Լ�����������λ�ã�R=0.92��������Isomap������ռ����dx(i,j)��4096άͼ������֮���ŷ�Ͼ��롣(B) IsomapӦ����MNIST���ݿ�(40)�е�N =1000����д ��2������IsomapǶ���е�������������ά�ȣ�������ʾ�������� "2 "����Ҫ�������ײ�����x�ᣩ�Ͷ������Σ�y�ᣩ������ռ�ľ���dx(i,j)�����߾��������һ��ּ�ڲ���дʶ������صIJ������Ķ���(41)�����������ʹ��e-Isomap����=4.2������Ϊ���Dz����������������ݼ��ϱ���һ���㶨��ά�ȣ����һ�£�Isomap�����˼����ӽϸ�ά�ȵ�����������Ͷ������ľ��룬������������һ������ʻ������ε��������š�
=======================================================================================================
The classical techniques for dimensionality reduction, PCA and MDS, are simple to implement, efficiently computable, and guaranteed to discover the true structure of data lying on or near a linear subspace of the high-dimensional input space (13). PCA finds a low-dimensional embedding of the data points that best preserves their variance as measured in the high-dimensional input space. Classical MDS finds an embedding that preserves the interpoint distances, equivalent to PCA when those distances are Euclidean. However, many data sets contain essential nonlinear structures that are invisible to PCA and MDS (4, 5, 11, 14). For example, both methods fail to detect the true degrees of freedom of the face data set (Fig. 1A), or even its intrinsic three-dimensionality (Fig. 2A).
����Ľ�ά����PCA��MDS��ʵ�ּ�����Ч�ʸߣ�����֤�������ڸ�ά����ռ�������ӿռ��ϻ������ݵ���ʵ�ṹ��13����PCA������һ����ά���ݵ��Ƕ�룬������õر������ݵ��ڸ�ά����ռ��еķ������MDS�ҵ�һ���ܱ���������Ƕ�룬����Щ������ŷ�����ʱ���൱��PCA��Ȼ�����������ݼ�������Ҫ�ķ����Խṹ������Щ�ṹ��PCA��MDS���������ģ�4��5��11��14�������磬�����ַ����������������ݼ�����ʵ���ɶȣ�ͼ1A����������������е���ά�ԣ�ͼ2A����
Here we describe an approach that combines the major algorithmic features of PCA and MDS��computational efficiency, global optimality, and asymptotic convergence guarantees��with the flexibility to learn a broad class of nonlinear manifolds. Figure 3 A illustrates the challenge of nonlinearity with data lying on a two-dimensional ��Swiss roll��: points far apart on the underlying manifold, as measured by their geodesic, or shortest path, distances, may appear deceptively close in the high-dimensional input space, as measured by their straight-line Euclidean distance. Only the geodesic distances reflect the true low-dimensional geometry of the manifold, but PCA and MDS effectively see just the Euclidean structure; thus, they fail to detect the intrinsic twodimensionality (Fig. 2B).
���������������һ�ַ������������PCA��MDS����Ҫ�㷨����������Ч�ʡ�ȫ���Ż��ͽ���������֤���Լ�ѧϰ�㷺�ķ��������ε�����ԡ�ͼ3��A˵�����ڶ�ά "��ʿ�� "�ϵķ��������������ٵ���ս���ڵײ������������Զ�ĵ㣬�������ǵIJ�������·���ľ������������ڸ�ά����ռ��У��������ǵ�ŷ��ֱ�߾��������������ܻ��Ե÷dz��ӽ���ֻ�в�ؾ���ŷ�ӳ�������ĵ�ά����ѧ����PCA��MDSʵ����ֻ������ŷ�Ͻṹ����ˣ�������������ڵĶ�ά�ԣ�ͼ2B����
Our approach builds on classical MDS but seeks to preserve the intrinsic geometry of the data, as captured in the geodesic manifold distances between all pairs of data points. The crux is estimating the geodesic distance between faraway points, given only input-space distances. For neighboring points, inputspace distance provides a good approximation to geodesic distance. For faraway points, geodesic distance can be approximated by adding up a sequence of ��short hops�� between neighboring points. These approximations are computed efficiently by finding shortest paths in a graph with edges connecting neighboring data points.
���ǵķ��������ھ���MDS�Ļ����ϣ������������ݵ����ڼ�����״�������������ݵ�֮��IJ�������ξ��������ֵ��������ؼ�����ֻ��������ռ���������£�����Զ����֮��IJ���߾��롣�������ڵ㣬����ռ������Ժܺõؽ��Ʋ�ؾ��롣����Զ���ĵ㣬��ؾ������ͨ�����ڵ�֮��� "���� "������������ơ���Щ����ֵ����ͨ��Ѱ��ͼ�������������ݵ�ıߵ����·������Ч���㡣
The complete isometric feature mapping, or Isomap, algorithm has three steps, which are detailed in Table 1. The first step determines which points are neighbors on the manifold M, based on the distances dX(i,j) between pairs of points i,j in the input space X. Two simple methods are to connect each point to all points within some fixed radius e, or to all of its K nearest neighbors (15). These neighborhood relations are represented as a weighted graph G over the data points, with edges of weight dX(i,j) between neighboring points (Fig. 3B).
In its second step, Isomap estimates the geodesic distances dM(i,j) between all pairs of points on the manifold M by computing their shortest path distances dG(i,j) in the graph G. One simple algorithm (16) for finding shortest paths is given in Table 1.
The final step applies classical MDS to the matrix of graph distances DG = {dG(i,j)}, constructing an embedding of the data in a d-dimensional Euclidean space Y that best preserves the manifold��s estimated intrinsic geometry (Fig. 3C). The coordinate vectors yi for points in Y are chosen to minimize the cost function (1) where DY denotes the matrix of Euclidean distances {{dY(i,j) = ||yi -yj||} and the L2 matrix norm . The �� operator converts distances to inner products (17), which uniquely characterize the geometry of the data in a form that supports efficient optimization. The global minimum of Eq. 1 is achieved by setting the coordinates yi to the top d eigenvectors of the matrix ��(DG)(13).
As with PCA or MDS, the true dimensionality of the data can be estimated from the decrease in error as the dimensionality of Y is increased. For the Swiss roll, where classical methods fail, the residual variance of Isomap correctly bottoms out at d =2 (Fig. 2B).
�����ĵȾ�����ͼ�ף���Isomap�㷨���������裬�����1����һ����������ռ�X�еĵ�i,j��֮��ľ���dX(i,j)��ȷ����Щ��������M�ϵ��ڽӵ㣬���ּķ����ǽ�ÿ�������ӵ�ij���̶��뾶e�ڵ����е㣬�������ӵ���������K��������ڽӵ㣨15������Щ�ڽӹ�ϵ��ʾΪ���ݵ��ϵļ�ȨͼG�����ڵ�֮���Ȩ��ΪdX(i,j)�ı�(ͼ3B)��
�ڵڶ����У�Isomapͨ������ͼG�����е��֮������·������dG(i,j)����������M�����е��֮��IJ�ؾ���dM(i,j)����1�и�����һ��Ѱ�����·���ļ��㷨(16)��
���һ��������MDSӦ����ͼ�������DG= {dG(i,j)}����dάŷ�Ͽռ�Y�й������ݵ�Ƕ�룬�ÿռ�����õر������ι��Ƶ����ڼ��νṹ��ͼ3C����Y�и������������yi��ѡ����Ϊ����С���ɱ����� (1) ����DY��ʾŷ�Ͼ������{dY(i,j) = ||yi - yj||}�� ��L2����淶 ��t���ӽ�����ת��Ϊ�ڻ�(17)���ڻ���һ��֧�ָ�Ч�Ż�����ʽ���ص����������ݵļ���������������yi��Ϊ�����(DG)(13)��ǰd����������������ʵ��ʽ1��ȫ����Сֵ��
��PCA��MDSһ�������ݵ���ʵά�ȿ���ͨ������Y��ά�����Ӷ����ٵ���������ơ����ھ��䷽��ʧЧ����ʿ����Isomap�IJв����ȷ����d =2���ﵽ�˵ײ���ͼ2B����
=======================================================================================================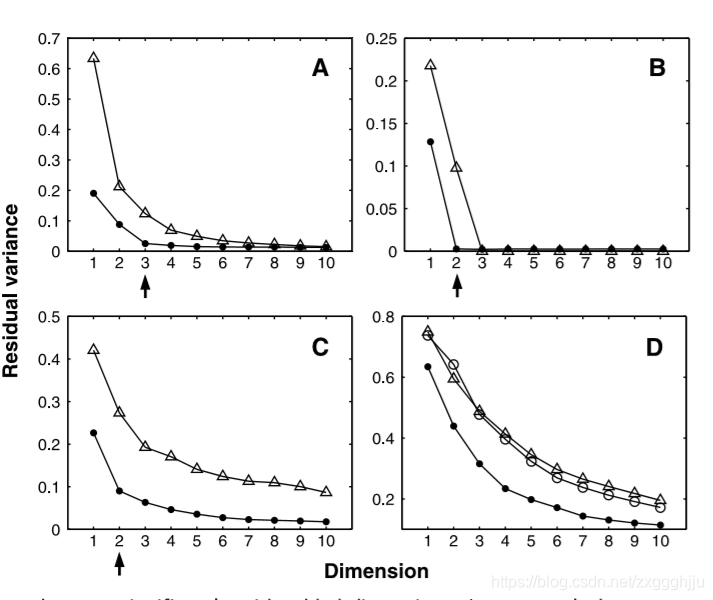
Fig. 2. The residual variance of PCA (open triangles), MDS [open triangles in (A) through ?; open circles in (D)], and Isomap (?lled circles) on four data sets (42). (A) Face images varying in pose and illumination (Fig. 1A). (B) Swiss roll data (Fig. 3). ? Hand images varying in ?nger extension and wrist rotation (20). (D) Handwritten ��2��s (Fig.1B). In all cases,residual variance decreases as the dimensionality d is increased. The intrinsic dimensionality of the data can be estimated by looking for the ��elbow�� at which this curve ceases to decrease signi?cantly with added dimensions. Arrows mark the true or approximate dimensionality, when known. Note the tendency of PCA and MDS to overestimate the dimensionality, in contrast to Isomap.
ͼ2.PCA(����������)��MDS����(A)�� ( C) �еĿ��������Ρ�(D)�еĿ���Բ��Isomaʵ��Բ���ĸ����ݼ���42���IJв(A)�����ƺ��������ϱ仯������ͼ��ͼ1 A����(B)��ʿ�����ݣ�ͼ3����( C)�ֲ�ͼ������ָ�����������ת��20���仯��(D)��д "2 "��Fig.1B��������������£��в�����ά��d�����Ӷ���С�����ݵ�����ά�ȿ���ͨ��Ѱ�� "�ⲿ "�����ƣ������ "�ⲿ "��������ά�ȵ����ӣ����߲��������½��� ��֪ʱ����ͷ�����ʵ����Ƴߴ硣��ע�⣬��Isomap��ȣ�PCA��MDS�����ڸ߹��ߴ硣
=======================================================================================================
Just as PCA and MDS are guaranteed, given sufficient data, to recover the true structure of linear manifolds, Isomap is guaranteed asymptotically to recover the true dimensionality and geometric structure of a strictly larger class of nonlinear manifolds. Like the Swiss roll, these are manifolds whose intrinsic geometry is that of a convex region of Euclidean space, but whose ambient geometry in the high-dimensional input space may be highly folded, twisted, or curved. For non-Euclidean manifolds, such as a hemisphere or the surface of a doughnut, Isomap still produces a globally optimal lowdimensional Euclidean representation, as measured by Eq. 1.
These guarantees of asymptotic convergence rest on a proof that as the number of data points increases, the graph distances dG(i,j) provide increasingly better approximations to the intrinsic geodesic distances dM(i,j), becoming arbitrarily accurate in the limit of infinite data (18, 19). How quickly dG(i,j) converges to dM(i,j) depends on certain parameters of the manifold as it lies within the high-dimensional space (radius of curvature and branch separation) and on the density of points. To the extent that a data set presents extreme values of these parameters or deviates from a uniform density, asymptotic convergence still holds in general, but the sample size required to estimate geodesic distance accurately may be impractically large.
����PCA��MDS�ڸ����㹻���ݵ�����£����Ա�֤�ָ��������ε���ʵ�ṹһ����Isomap���Խ����ر�֤�ָ�һ���ϸ������ϸ���ķ��������ε���ʵά�Ⱥͼ��νṹ��������ʿ��һ������Щ���ε����ڼ��νṹ��ŷ�Ͽռ���������ά����ռ�Ļ������νṹ�����Ǹ߶��۵���Ť���������ġ����ڷ�ŷ����ñ���������λ�����Ȧ�ı��棬Isomap���ܲ���ȫ�����ŵĵ�άŷ����ñ����ɹ�ʽ1��á�
��Щ���������ı�֤��������֤�������������ݵ����������ӣ�ͼ�ξ���dG(i,j)�Թ��в�ؾ���dM(i,j)�ṩ��Խ��Խ�õĽ���ֵ�����������ݵ������±�����⾫ȷ(18, 19)��dG(i,j)������dM(i,j)���ٶ�ȡ�������ε�ijЩ��������Ϊ��λ�ڸ�ά�ռ���(���ʰ뾶�ͷ�֧����)����ȡ���ڵ���ܶȡ����һ�����ݼ����ֳ���Щ�����ļ���ֵ��ƫ���˾��ȵ��ܶȣ�����������һ���������Ȼ��������ȷ���Ʋ�ؾ�����������������ܲ���ʵ�ʵش�
=======================================================================================================
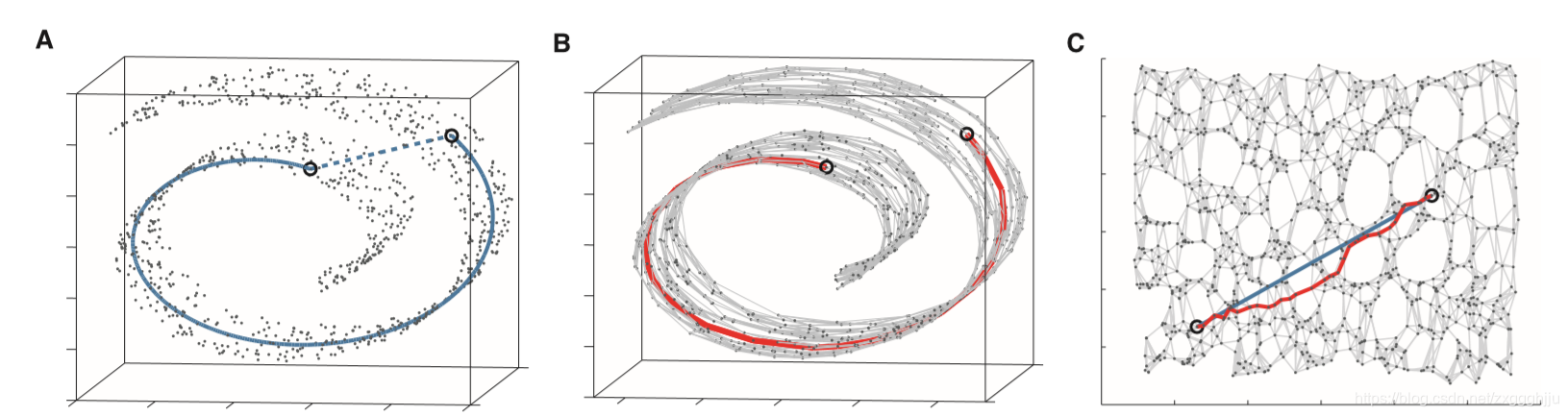
Fig.3.The��Swissroll�� dataset,illustrating how Isomap exploits geodesic paths for nonlinear dimensionality reduction.(A) For two arbitrary points (circled) on a nonlinear manifold, their Euclidean distance in the highdimensional input space (length of dashed line) may not accurately re?ect their intrinsic similarity, as measured by geodesic distance along the low-dimensional manifold (length of solid curve). (B) The neighborhood graph G constructed in step one of Isomap (with K=7 and N =1000 data points) allows an approximation (red segments) to the true geodesic path to be computed ef?ciently in step two, as the shortest path in G.( C) The two-dimensional embedding recovered by Isomap in step three, which best preserves the shortest path distances in the neighborhood graph (overlaid). Straight lines in the embedding (blue) now represent simpler and cleaner approximations to the true geodesic paths than do the corresponding graph paths (red).
ͼ3. "��ʿ��"���ݼ���˵��Isomap��������ò��·�������ͷ�����ά�ȵġ� (A) ���ڷ����������ϵ����������ԲȦ�ĵ㣬�����ڸ�ά����ռ��е�ŷ�Ͼ��룬�����ߵij��ȿ�����ȷ���������ǵ����������ԣ�����ͨ���ص�ά���εIJ�ؾ��룬��ʵ���ߵij��Ȳ�õġ�(B)Isomap��һ������������ͼG����K =7��N=1000�����ݵ㣬�����ڵڶ�������Ч�ؼ���������IJ��·���Ľ���ֵ����ɫ�Σ���ΪG����̵�·����( C)Isomap�ڵ������лָ��Ķ�άǶ�룬����õı�������ͼ����̵�·������(����)��Ƕ���е���ɫֱ�����ڱ���Ӧ�ĺ�ɫͼ·���������ɾ��ش��������IJ��·���Ľ��ơ�
=======================================================================================================
Isomap��s global coordinates provide a simple way to analyze and manipulate highdimensional observations in terms of their intrinsic nonlinear degrees of freedom. For a set of synthetic face images, known to have three degrees of freedom, Isomap correctly detects the dimensionality (Fig. 2A) and separates out the true underlying factors (Fig. 1A). The algorithm also recovers the known low-dimensional structure of a set of noisy real images, generated by a human hand varying in finger extension and wrist rotation (Fig. 2C) (20). Given a more complex data set of handwritten digits, which does not have a clear manifold geometry, Isomap still finds globally meaningful coordinates (Fig. 1B) and nonlinear structure that PCA or MDS do not detect (Fig. 2D). For all three data sets, the natural appearance of linear interpolations between distant points in the low-dimensional coordinate space confirms that Isomap has captured the data��s perceptually relevant structure (Fig. 4).
Isomap��ȫ�������ṩ��һ�ּķ������������ڵķ��������ɶȳ������������Ͳ�����ά�ȵĹ۲����ݡ�����һ����֪�����������ɶȵĺϳ�����ͼ��Isomap��ȷ�ؼ����ߴ磨ͼ2 A����������������ĵײ����أ�ͼ1 A�������㷨���ָ�����֪��һ����������ʵͼ��ĵ�ά�ṹ����ͼ������һֻ����ָ��չ��������ת�б仯�������ֲ����ģ�ͼ2 C����20��������һ�������ӵ���д�������ݼ�����û����ȷ�����μ��Σ�Isomap��Ȼ�����ҵ�ȫ������������꣨ͼ1 B���ͷ����Խṹ����PCA��MDSû�м������Խṹ��ͼ2D�����������������ݣ��ڵ�ά����ռ��У�Զ���ĵ�֮����Ȼ�������Բ�ֵ��֤ʵ��Isomap�Ѿ����������ݵĸ�����ؽṹ��ͼ4����
=======================================================================================================
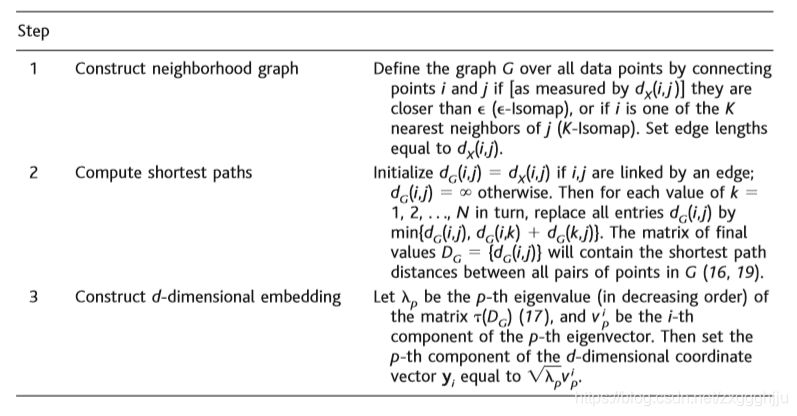
Table1.The Isomap algorithm takes as input the distances dX(i,j) between all pairs i,j from N datapoints in the high-dimensional input space X, measured either in the standard Euclidean metric (as in Fig. 1A) or in some domain-speci?c metric (as in Fig. 1B). The algorithm outputs coordinate vectors yi in a d-dimensional Euclidean space Y that (according to Eq. 1) best represent the intrinsic geometry of the data. The only free parameter (�� or K) appears in Step 1.
��1.Isomap�㷨����ά����ռ�X��N�����ݵ�����ж�i,j֮��ľ���dX(i,j)��Ϊ���룬�ñ�ŷ�϶���������ͼ1A����ij�����ض�����������ͼ1B�����㷨��dάŷ�Ͽռ�Y�������������yi�����ݹ�ʽ1�����ܴ������ݵ����ڼ�����״��Ψһ�����ɲ����Ż�K�����ڲ���1�С�
=======================================================================================================
���裺
1.�����ڽ�ͼ ���[����dX(i,j)������i��j�Ȧż���-Isomap�������������i��j��K��������ھ�֮һ����ͨ�����ӵ�i��j���������ݵ��϶���ͼG�����ñ߳�����dX(i,j)��
2.�������·�� ���i,j���������ʼ��dG(i,j) =dX(i,j)������ʼ��dG(i,j) =�� ��Ȼ�����ζ�k��ÿ��ֵ1��N����min{dG(i,j)��dG(i,k) +dG(k,j)}����������ĿdG(i,j)������ֵ����dG = {dG(i,j)}������G�����е��֮������·������(16��19)��
3.����dάǶ�� ���pΪ����t(DG)(17)�ĵ�p������ֵ(���εݼ�)��
Ϊp�����������ĵ�i����������ô��dά����ʸ��yi�ĵ�p����������

Fig. 4. Interpolations along straight lines in the Isomap coordinate space (analogous to the blue line in Fig. 3C) implement perceptually natural but highly nonlinear ��morphs�� of the corresponding high-dimensional observations (43) by transforming them approximately along geodesic paths (analogous to the solid curve in Fig. 3A). (A) Interpolations in a three-dimensional embedding of face images (Fig. 1A). (B) Interpolations in a fourdimensional embedding of hand images (20) appear as natural hand movements when viewed in quick succession, even though no such motions occurred in the observed data. ? Interpolations in a six-dimensional embedding of handwritten��2��s(Fig.1B) preserve continuity not only in the visual features of loop and arch articulation, but also in the implied pen trajectories, which are the true degrees of freedom underlying those appearances.
ͼ4.����Isomap����ռ��е�ֱ�߽��в�ֵ��������ͼ3C�е����ߣ�������ͨ���ز���߽��Ƶر任��Ӧ�ĸ�ά�۲�ֵ��43������ʵ���˸�֪����Ȼ���߶ȷ����Ե� �����Ρ���������ͼ3A�е�ʵ�ߡ�(A) ����ͼ����άǶ���еIJ�ֵ��ͼ1A����(B)���������ۿ�ʱ���ֲ�ͼ��20������άǶ���е��ڲ���ʾΪ��Ȼ���ֲ��˶�����ʹ�ڹ۲쵽��������û�з����������˶���?��д "2 "��ͼ1B����άǶ���еIJ�ֵ�����ڻ��κ����νӵ��Ӿ������ϱ����������ԣ������������ıʵĹ켣��Ҳ�����������ԣ��������Щ������������ɶȡ�
=======================================================================================================
Previous attempts to extend PCA and MDS to nonlinear data sets fall into two broad classes, each of which suffers from limitations overcome by our approach. Local linear techniques (21�C23) are not designed to represent the global structure of a data set within a single coordinate system, as we do in Fig. 1. Nonlinear techniques based on greedy optimization procedures (24�C30) attempt to discover global structure, but lack the crucial algorithmic features that Isomap inherits from PCA and MDS: a noniterative, polynomial time procedure with a guarantee of global optimality; for intrinsically Euclidean manifolds, a guarantee of asymptotic convergence to the true structure; and the ability to discover manifolds of arbitrary dimensionality, rather than requiring a fixed d initialized from the beginning or computational resources that increase exponentially in d.
Here we have demonstrated Isomap��s performance on data sets chosen for their visually compelling structures, but the technique may be applied wherever nonlinear geometry complicates the use of PCA or MDS. Isomap complements, and may be combined with, linear extensions of PCA based on higher order statistics, such as independent component analysis (31, 32). It may also lead to a better understanding of how the brain comes to represent the dynamic appearance of objects, where psychophysical studies of apparent motion (33, 34) suggest a central role for geodesic transformations on nonlinear manifolds (35) much like those studied here.
��ǰ���Խ�PCA��MDS��չ�����������ݼ��ķ�����Ϊ�����࣬ÿ��ܵ����Ƿ����˷��ľ����Ե����š�����������ͼ1����������,�ֲ����Լ���(21-23)������Ϊ���ڵ�һ����ϵ�ڱ�ʾ���ݼ���ȫ�ֽṹ����Ƶġ�����̰���Ż�����(24-30)�ķ����Լ�����ͼ����ȫ�ֽṹ����ȱ��Isomap��PCA��MDS�м̳еĹؼ��㷨������һ���ǵ����ġ�����ʽʱ��ij�����֤ȫ�������ԣ��������ڵ�ŷ��������Σ���֤�˵���ʵ�ṹ�Ľ����������Լ���������ά�����ε�������������Ҫ�ӿ�ʼ�ͳ�ʼ���Ĺ̶�d����d�г�ָ�������ļ�����Դ��
����������Ѿ�չʾ��Isomap��Ϊ���Ӿ�������עĿ�Ľṹѡ������ݼ��ϵ����ܣ����ü�������Ӧ�����κη����Լ�����״���ӵ�PCA��MDS��ʹ�á�Isomap�ǶԻ��ڸ߽�ͳ��ѧ��PCA������չ�IJ��䣬Ҳ������֮��ϣ�������ɷַ���(31, 32)����Ҳ���ܵ������Ǹ��õ���������������ʾ����Ķ�̬��ۣ��������˶�����������ѧ�о���33��34������˷����������ϵIJ���߱任��35�����������ã�������Щ�������о���
=======================================================================================================
References and Notes
- M. P. Young, S. Yamane, Science 256, 1327 (1992).
- R. N. Shepard, Science 210, 390 (1980).
- M. Turk, A. Pentland, J. Cogn. Neurosci. 3, 71 (1991).
- H. Murase, S. K. Nayar, Int. J. Comp. Vision 14,5 (1995).
- J. W. McClurkin, L. M. Optican, B. J. Richmond, T. J. Gawne, Science 253, 675 (1991).
- J. L. Elman, D. Zipser, J. Acoust. Soc. Am. 83, 1615 (1988).
- W. Klein, R. Plomp, L. C. W. Pols, J. Acoust. Soc. Am. 48, 999 (1970).
- E.Bizzi,F.A.Mussa-Ivaldi,S.Giszter,Science253,287 (1991).
- T. D. Sanger, Adv. Neural Info. Proc. Syst. 7, 1023 (1995).
- J. W. Hurrell, Science 269, 676 (1995).
- C. A. L. Bailer-Jones, M. Irwin, T. von Hippel, Mon. Not. R. Astron. Soc. 298, 361 (1997).
- P. Menozzi, A. Piazza, L. Cavalli-Sforza, Science 201, 786 (1978).
- K. V. Mardia, J. T. Kent, J. M. Bibby, Multivariate Analysis, (Academic Press, London, 1979).
- A. H. Monahan, J. Clim., in press.
- The scale-invariant K parameter is typically easier to set than ��, but may yield misleading results when thlocal dimensionality varies across the data set. When available, additional constraints such as the temporal ordering of observations may also help to determine neighbors. In earlier work (36) we explored a more complex method (37), which required an order of magnitude more data and did not support the theoretical performance guarantees we provide here for ��- and K-Isomap.
- This procedure, known as Floyd��s algorithm, requires O(N3) operations. More ef?cient algorithms exploiting the sparse structure of the neighborhood graph can be found in (38).
- The operator t is de?ned by �� (D)= -HSH/2, where S is the matrix of squared distances , and H is the ��centering matrix�� {Hij = ��ij -1/N}(13).
- Our proof works by showing that for a suf?ciently highdensity( ��) of data points,we can always choose a neighborhood size (�� or K) large enough that the graph will (with high probability) have a path not much longer than the true geodesic, but small enough to prevent edges that ��short circuit�� the true geometry of the manifold. More precisely, given arbitrarily small values of ��1,��2, and ��, we can guarantee that with probability at least 1- ��, estimates of the form
will hold uniformly over all pairs of data points i,j.For ��-Isomap, we require
�� <s0,
where r0 is the minimal radius of curvature of the manifold M as embedded in the input space X, s0 is the minimal branch separation of M in X, V is the (d-dimensional)volume of M,and (ignoringboundary effects) ��d is the volume of the unit ball in Euclidean d-space. For K-Isomap, we let �� be as above and ?x the ratio (K +1)/��=��d(��/2)d/2. We then require
The exact content of these conditions��but not their general form��depends on the particular technical assumptions we adopt. For details and extensions to nonuniform densities, intrinsic curvature, and boundary effects, see http://isomap.stanford.edu. - In practice, for ?nite data sets, dG(i,j) may fail to approximate dM(i,j) for a small fraction of points that are disconnected from the giant component of the neighborhood graph G. These outliers are easily detected as having in?nite graph distances from the majority of other points and can be deleted from further analysis.
- The Isomap embedding of the hand images is available at Science Online at www.sciencemag.org/cgi/content/full/290/5500/2319/DC1. For additional material and computer code, see http://isomap. stanford.edu.
- R. Basri, D. Roth, D. Jacobs, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (1998), pp. 414�C420.
- C. Bregler, S. M. Omohundro, Adv. Neural Info. Proc. Syst. 7, 973 (1995).
- G. E. Hinton, M. Revow, P. Dayan, Adv. Neural Info. Proc. Syst. 7, 1015 (1995).
- R. Durbin, D. Willshaw, Nature 326, 689 (1987).
- T. Kohonen, Self-Organisation and Associative Memory (Springer-Verlag, Berlin, ed. 2, 1988), pp. 119�C 157.
- T. Hastie, W. Stuetzle, J. Am. Stat. Assoc. 84, 502 (1989).
- M. A. Kramer, AIChE J. 37, 233 (1991).
- D. DeMers, G. Cottrell, Adv. Neural Info. Proc. Syst. 5, 580 (1993).
- R. Hecht-Nielsen, Science 269, 1860 (1995).
- C. M. Bishop, M. Svens?en, C. K. I. Williams, Neural Comp. 10, 215 (1998).
- P. Comon, Signal Proc. 36, 287 (1994).
- A. J. Bell, T. J. Sejnowski, Neural Comp. 7, 1129 (1995).
- R. N. Shepard, S. A. Judd, Science 191, 952 (1976).
- M. Shiffrar, J. J. Freyd, Psychol. Science 1, 257 (1990).
- R. N. Shepard, Psychon. Bull. Rev. 1, 2 (1994).
- J. B. Tenenbaum, Adv. Neural Info. Proc. Syst. 10, 682 (1998).
- T.Martinetz,K.Schulten,NeuralNetw.7,507(1994).
- V. Kumar, A. Grama, A. Gupta, G. Karypis, Introduction to Parallel Computing: Design and Analysis of Algorithms (Benjamin / Cummings, Redwood City, CA, 1994), pp. 257�C297.
- D. Beymer, T. Poggio, Science 272, 1905 (1996).
- Available at www.research.att.com/;yann/ocr/mnist.
- P. Y. Simard, Y. LeCun, J. Denker, Adv. Neural Info. Proc. Syst. 5, 50 (1993).
- In order to evaluate the ?ts of PCA, MDS, and Isomap on comparable grounds, we use the residual variance
1�CR2(D M, DY). DY is the matrix of Euclidean distances in the low-dimensional embedding recovered by each algorithm. D M is each algorithm��s best estimate of the intrinsic manifold distances: for Isomap, this is the graph distance matrix DG; for PCA and MDS, it is the Euclidean input-space distance matrix DX (except with the handwritten ��2��s, where MDS uses the tangent distance). R is the standard linear correlation coef?cient, taken over all entries of D M and DY. - In each sequence shown, the three intermediate images are those closest to the points 1/4, 1/2, and 3/4 of the way between the given endpoints.We can also synthesize an explicit mapping from input space X to the low-dimensional embedding Y, or vice versa, using the coordinates of corresponding points {xi, yi} in both spaces provided by Isomap together with standard supervised learning techniques (39).
- Supported by the Mitsubishi Electric Research Laboratories, the Schlumberger Foundation, the NSF (DBS-9021648), and the DARPA Human ID program. We thank Y. LeCun for making available the MNIST database and S.RoweisandL.Saulforsharingrelated unpublished work. For many helpful discussions, we thank G. Carlsson, H. Farid, W. Freeman, T. Grif?ths, R. Lehrer, S. Mahajan, D. Reich, W. Richards, J. M. Tenenbaum, Y. Weiss, and especially M. Bernstein.
10 August 2000; accepted 21 November 2000