
CVPR-2020
����Ŀ¼
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 4.1 Instance Initialization
- 4.2 Feature Extraction Network
- 4.3 Deforming Network
- 4.4 Polygon Transforming Loss
- 5 Experiments
- 5.1 Datasets
- 5.2 Instance Segmentation
- 6 Conclusion��own��
1 Background and Motivation
ʵ���ָ����Ŀ����ʶ�������пɼ�����Ŀ�꣬��Ϊÿ��Ŀ������һ�� mask��
����ʵ���ָ���ǿ��Ը��õ����ⳡ��������ܹ���ɸ��Ӳ�������Ļ�����ϵͳ���Ľ��Զ���ʻ�����ĸ�֪ϵͳ��
Ŀ��� wide variability in the scale and appearance �Լ��ڵ����˶�ģ����ʵ���ָ���������˼������ս
Ŀǰ������������ǻ��� two-stage process ����ʵ���ָ�ģ�Ҳ����Ŀ���⣨������Ĵ�ŷ�Χ����Ȼ���ڼ��Ŀ���ڽ��зָ�������Σ�����������ܺܺõĴ�������Ŀ�걻�ڵ������⣬ȱ������������ܻ� over-smoothed failing to capture fine-grained details��Ҳ���Ƿָ�������Բ��û����ǣ����ܺܺ���������߽磬����Ҫ�ָ�����ǣ����Ԥ����������������Χ������Բ�Σ�
����һ��˼·�ǣ����� interactive annotation��polygon-based methods�� �ķ�������עͼƬ�� annotation �ķ���������������ö���������õز�Ŀ��ļ�����״�������ǰ�ʵ���ָ�� pixel-wise labeling task���˷������ɻ�ø�Ϊ��ȷ�� mask���Լ������ٵ� annotation ���̣���Ϊ������Ԥ�����ζ����ƫ�ƣ������� mask��ȱ���ǣ�����������ڵ����²���ͨ��Ŀ��ʱ����Ч������
�����ں������������ȡ�����̣������ PolyTransform ʵ���ָ��
2 Related Work
- Proposal-based Instance Segmentation
- Proposal-free Instance Segmentation
- Interactive Annotation
3 Advantages / Contributions
ranks 1st on the Cityscapes test-set leaderboard
4 Method
������ָ�����Ļ����ϣ����ʼ mask �� bbox�������֧�� mask ������������һ�����ȡ����� CoordConv ����ʽ���뵽 bbox ���� FPN ��ȡ��������ͼ�У������֧������� STN �� self-attention Ԥ��������ÿ�������ƫ����

deforming network��Ԥ������ÿ�������λ��
4.1 Instance Initialization

���÷ָ����ȡ mask������ mask��һ����ü��� resize ���οָ��Ҫ��Ԥ����˿���÷ָ��Ԥ��Ŀ���ͼ���¼�ͷ��resize �� 512x512������һ�������� opencv �е� findcontour �������� mask ����ȡ��������ͼ���Ҽ�ͷ��
findcontour �����ο� ��ȡ������ԭ���ʹ���ʵ�����������ġ�Topological structural analysis of digitized binary images by border following��
������ȡ������������ÿ��10�� pixel ��ʼ��һ�����㣬�γ� polygon init

4.2 Feature Extraction Network
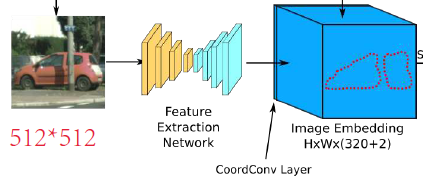
��ͼ�м�����ṹ���֣�Ŀ���� learn strong object boundary features�����������ṹ����ͼ��ʾ

�� FPN �ṹ���ο� ��FPN����Feature Pyramid Networks for Object Detection���������Ѹ��� level �Ľ�� concatenate ������
4.3 Deforming Network
1��Vertex embedding

�� CoordConv ������������������channel �� 320 ����� 322��CoordConv ����ϸ�Ľṹ����ͼ��ʾ

��� CoordConv ����������һ����Ϸ��ɫ�ʣ����Ե�ͬѧ���Բο� Ҫ����CNN��CoordConv�ܳ�������������껹��ѵ��?
Ȼ���� STN ���磬����������һ���������� HxWx322 ������������Ϊ N*322 �� vector

�ο� ���ıʼǣ��ռ�任���磨Spatial Transformer Networks��
2��Deforming network
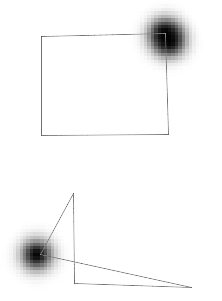
���ڳ�ʼ���Ķ����������������һ����������꣬���������ı�Ҳ��֮�ƶ�����Щ�ߵ��ƶ�ȡ�������ڶ����λ�ã���ˣ�ÿ���������֪�������ھӣ�����Ҫһ�ַ������ͨ�ţ��Լ��ٲ��ȶ����ص�����Ϊ�������������ͼ���ı��ɫ�����λ�ã������֪�����ڶ���ľ���λ�ã������ı䶥���������ص���Ϊ����Ȼ�������Dz��뿴���ˣ�
����ͨ�� self-attending Transformer network�������ԡ�Attention is all you need������ѧϰ�����������ϵ��Ȩ�أ�����������
���� ��N*322 �� vector ����ͨ�� self-attending Transformer network ���Եõ� Query��Key��Value�� �� �� ���ο� ��MoCo����Momentum Contrast for Unsupervised Visual Representation Learning����Ȼ�������湫ʽ���������֮���Ȩ��
��ʽ����
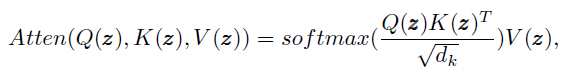
����
�� Q �� K �� dimension

ʲô��˼�أ����ǵ�ǰ���������Ĺ�ϵ��Ȩ�أ����ҿ��������� attention ��ʽ�� QK ���������Ȼ��� V ��Ȩ��һ���γ�Ԥ�⣬�����û�� self-attention �����磬�� self-attention ���������ѧϰ����ͬ����֮��Ĺ�ϵ�����ǹ�����Ԥ�⣬����ѧһ���Ͳ�ͬ����֮���ϵ��Ȩ�أ�Ȼ������������㹲ͬԤ�⣨Ԥ����Ƕ����ƫ������
������һ������������ӣ��������ÿ�����ͱ�ǩ֮��Ĺ�ϵ���Ա�ǩ�Ĺ��ȣ����� attention���������ÿ�����֮��Ĺ�ϵ�������ȣ�Ȩ�أ����� self-attention�����Ա��ļ��㶥���붥��֮��Ĺ�ϵ���õ��� self-attention

4.4 Polygon Transforming Loss
1��Chamfer Distance loss
polygon
closer to the ground truth polygon
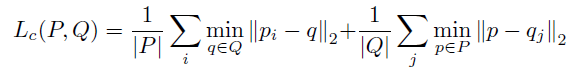
and
are the rasterized edge pixels��դ�ı����ص㣩 of the polygons
and
��һ���Ԥ��Ķ��������һ�㣬��GT��С����ĺ�
�ڶ����GT������һ�㣬��Ԥ��Ķ������С����ĺ�
Ŀ�ľ�����Ԥ����Ķ���κ� GT �����ܵıƽ�
�ο� Chamfer Distance�C���Ǿ���
2��the standard deviation loss
��ֹ�����ƫ�ƹ���
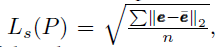
��ʾ�ߵ�ƽ�����ȣ�
��ʾ�ߵij��ȣ�
Ӧ���DZߵĸ���
5 Experiments
5.1 Datasets
- Cityscapes��1024 �� 2048
5.2 Instance Segmentation
1��Instance Initialization
���õ��� UPSNet ʵ���ָ������� WideResNet38 �������磨�ο� ��WRNs����Wide Residual Networks����
2��Comparison to SOTA

����

3��Robustness to Initialization
�Ա��ò�ͬ��ʼ���ָ���Ľ��

DCN �� deformable convolution network
PANet Ӧ��ֵ���ǸĽ��� FPN �ṹ
6 Conclusion��own��
- �� mask �����������õ��� opencv ��
- CoordConv ����ϸ��
- STN ����ϸ��
- self-attention �����㶥��֮��Ĺ�ϵ����������Ԥ�ⶥ���ƫ��