
文章目录
- Abstract
- 1.Introduction
- 2.RelatedWork
- 3.Method
- 3.1.FindingExemplars
- 3.2.DifferentialAttentionNetwork(DAN)
- 3.3.DifferentialContextNetwork(DCN)
- 4.Experiments
- 4.1.AnalysisofNetworkParameters
- 4.2.Comparisonwithbaselineandstateoftheart
- 4.3.AttentionVisualization
- 5.Discussion
- 6.Conclusion
Abstract
在本文中,我们的目标是在训练过程中为图像提供问题-答案对数据集时,根据图像回答问题。许多方法已经集中于通过使用基于图像的注意力来解决这个问题。这是通过在回答问题时专注于图像的特定部分来完成的。解决这个问题时,人类也会这样做。但是,以前系统关注的区域与人类关注的区域不相关。由于该缺点,精度受到限制。在本文中,我们建议使用基于示例的方法来解决此问题。我们获得一个或多个支持和对立示例,以获得差异化的注意力区域。与其他基于图像的注意力方法相比,这种差异注意力更接近人类注意力。它也有助于在回答问题时提高准确性。在具有挑战性的基准数据集上评估了该方法。我们比其他基于图像的注意力方法表现更好,并且与关注图像和问题的其他最新方法相比具有竞争力。
1.Introduction
回答有关图像的问题需要我们对图像有所了解。通过在回答问题时观察该方法所关注的图像区域,我们可以深入了解该方法。在最近的工作中已经观察到,人类在回答问题时也会注意图像的特定区域[3]。因此,我们期望在回答问题时专注于“正确的”区域与获得更好的语义理解以解决问题之间有很强的相关性。就人类而言,这种相关性存在[3]。因此,我们的目标是获得与人的注意力更好相关的基于图像的注意力区域。我们通过获得不同的关注来做到这一点。差异注意力依赖于认知的示例模型。
在认知研究中,样例理论表明,人类能够依靠样例模型来获得解决认知任务的一般化方法。在这个模型中,个体将新的刺激与已经存储在存储器中的实例进行比较[10] [24],并基于这些示例获得答案。我们希望一个示例模型来提供关注。我们希望集中于最接近的示例中的特定部分,以区别于较远的示例。我们通过获得区分注意力样本和相对样本的差异注意力区域来做到这一点。我们的前提是,最接近的语义样本与最远的语义样本之间的差异可以引导对特定图像区域的关注。我们表明,通过使用这种差异注意力机制,我们能够在解决视觉问题回答任务方面获得显着改善。此外,我们表明,获得的注意力区域在数量和质量上与人类注意力区域的相关性更高。我们在具有挑战性的VQA-1 [2],VQA-2 [7]和HAT [3]上对此进行评估.

遵循的方法的主要流程如图1所示。给定图像和相关问题,我们使用注意力网络将图像和问题进行组合以获得参考注意力嵌入。这用于对数据库中的示例进行排序。我们获得了一个接近的例子作为支持范例,而获得了一个远的例子作为对立范例。 这些用于获得差分注意力向量。我们评估了我们方法的两种变体,其中一种被称为“差异注意力网络”(DAN),其中支持和相反的示例仅用于更好地关注图像。另一个我们称为“差异上下文网络”(DCN),可获取差异上下文特征。 这是从相对于原始图像的支撑样例和相对样例之间的差异获得的,以提供差异特征。附加上下文用于回答问题。两种变体在基线之上均改善了结果,而差异上下文变体更好。
通过本文,我们提供了以下贡献:
- 我们采用基于范例的方法,通过提供差异化??的关注来改进视觉问答(VQA)方法
- 我们评估了两种获得差异化注意力的变体-一种仅获得注意力,另一种则获得除了注意力之外的差异上下文
- 我们证明了这种方法与人的注意力更好地相关,并且可以改善视觉问题的答案,从而改善基于图像的注意力方法的最新水平。就此问题而言,它相对于其他建议方法也具有竞争力。
2.RelatedWork
视觉问答系统(VQA)问题是最近出现的问题,它是一种新型的视觉图灵测试。 目的是展示与传统的视觉识别任务(例如对象检测和分割)相比,系统在解决更具挑战性的任务方面的进步。 Geman等人[6]在该领域的初步工作提出了这种视觉图灵测试。 大约在同一时间,Malinowski等人[18]提出了一种基于多世界的方法来获取问题并从图像中回答问题。 这些作品旨在回答有限类型的问题。 在这项工作中,我们的目标是回答自由格式的开放域[2]问题,这是以后的工作所尝试的。
开放域形式解决此问题的最初方法是[19]。这是受到神经机器翻译工作的启发,该工作提出将翻译作为序列编码器-解码器框架[26]。然而,随后的工作[22] [2]使用编码嵌入将问题作为分类问题来解决。他们在图像嵌入(通过CNN获得)和问题嵌入(通过LSTM获得)上使用了soft-max分类。 Ma等人的进一步工作。 [17]通过使用CNN获得图像和问题嵌入来改变获得嵌入的方式。另一个有趣的方法[21]使用动态参数预测,其中基于使用散列的问题嵌入来修改用于图像嵌入的CNN模型的权重。但是,这些方法不是基于关注的。注意的使用使我们能够专注于与实例相关的图像或问题的特定部分,并提供对系统性能的宝贵见解。
对解决VQA问题的关注引起了极大的兴趣。基于注意力的模型包括基于图像的注意力模型,基于问题的注意力以及一些既基于图像又基于问题的注意力。在基于图像的注意力方法中,目标是使用问题来将注意力集中在图像中的特定区域上[25]。最近的一项有趣的工作[30]表明,可以根据问题在图像上使用堆叠注意力来反复获得注意力。我们的工作与此工作密切相关。还有进一步的工作[13]考虑图像上的基于区域的注意力模型。基于图像的注意力已经允许对各种方法进行系统的比较,并能够分析与人类注意力模型的相关性,如[3]所示。在我们的方法中,我们专注于使用差异注意力的基于图像的注意力,并表明它与基于图像的注意力更好地相关。关于基于问题的注意力也有许多有趣的著作[31] [29]。一项有趣的工作获得了用于回答不同类型问题的各种模块集[1]。最近的工作还探讨了基于联合图像和问题的分层协同注意[16]。也可以通过这些方法探索差异注意力的概念。但是,我们将自己限制在基于图像的注意力上,因为我们的目标是获得一种与人类注意力密切相关的方法[3]。 [5]提出了一项有趣的工作,提倡多模式池化并获得VQA中的最新技术。有趣的是,我们表明通过将其与所提出的方法结合可以进一步改善我们的结果。
3.Method
在本文中,我们采用一种分类框架,该框架使用图像嵌入和问题嵌入相结合的方法,在多选设置中使用softmax函数来求解答案。 堆叠注意力网络(SAN)[30]中采用了类似的设置,其目的还在于获得更好的注意力和其他几种最新方法。 我们提供两种不同的变体,以在VQA系统中获得不同的关注。 我们将第一个变量称为“差异注意力网络”(DAN),将另一个称为“差异上下文网络”(DCN)。 我们将在以下小节中介绍这两种方法。 这两项任务的共同要求是获得最接近的语义样本。
3.1.FindingExemplars
在我们的方法中,我们使用语义最近的邻居。图像级别的相似性不足,因为最近的邻居可能在视觉上相似,但问题中暗示的上下文可能不相同(例如,“孩子在玩吗?”会根据视觉相似性为带有孩子的图像产生相似的结果。孩子们在玩还是不玩)。为了获得语义特征,我们使用VQA系统[15]为我们提供了与有意义的示例相关的联合图像问题级别嵌入。我们将图像级别特征与语义最近的邻居进行比较,并观察到语义最近的邻居更好。我们在使用K-D树数据结构表示特征的k最近邻居方法中使用了语义最近邻居。数据集特征的排序基于欧几里得距离。在第4.1节中,我们为评估提供了几个最近邻的值,这些值被用作支持样本。为了获得相反的示例,我们使用了远邻,其数量比最近邻远一个数量级。这是通过将训练数据粗化为垃圾箱获得的。我们将相反的样例指定为以50个簇的顺序约在20个簇之外的样例。该参数不是严格的,仅重要的是,相反的示例要远离支持示??例。我们表明,使用这些支持和对立的示例将有助于该方法,而任何随机排序都会对该方法产生不利影响。

3.2.DifferentialAttentionNetwork(DAN)
在DAN方法中,我们使用多任务设置。作为一项任务,我们使用三元组损失[8]来学习距离度量。该度量确保附近示例的注意力加权区域之间的距离较小,而远程示例的注意力加权区域之间的距离较大。另一个任务是VQA的主要任务。更正式地,给定图像xi,我们使用CNN获得嵌入
,该CN通过函数
进行参数化,其中
是CNN的权重。类似地,问题
在通过使用函数
参数化的LSTM之后导致嵌入
的问题,其中
是LSTM的权重。这在图2的第1部分中进行了说明。输出图像嵌入
和问题嵌入
用于关注网络,该网络将图像和问题嵌入与加权softmax函数结合在一起,并生成输出关注加权向量
。注意机制在图2中进行了说明。该网络的权重是通过使用两个损失(答案的三元组损失和soft-max分类损失)进行端到端学习的(如图2的第3部分所示)。目的是获得注意力权重向量,其使支持的示例性注意力接近图像注意力,而远离相反的示例性注意力。用于训练的关节损失函数由下式给出:
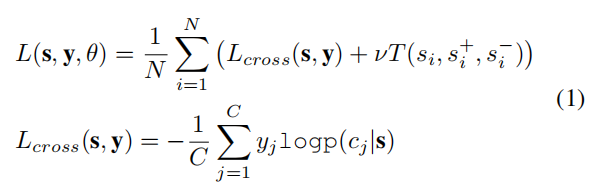
其中
是两个损失函数的模型参数集,
是输出类别标签,
是输入样本。
是VQA中的类总数(由一组包括颜色,计数等的输出类总数组成),
是样本总数。 第一项是分类损失,第二项是三重态损失。
是控制分类损失与三重态损失之间的比率的常数。
是所使用的三重态损失函数。 这被分解为两个术语,一个使正样本接近,而另一个使负样本更远。 这是由
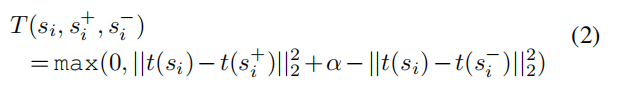
常数
控制支撑和相对示例之间的间隔裕度。 常数
和
通过验证数据获得。
该方法如图2所示。我们进一步将模型扩展到五重设置,在度量学习设置中,我们将两个支持注意力权重更近,并将两个相反注意力权重进一步加重。 我们在4.1节中观察到,这进一步提高了DAN方法的性能。

3.3.DifferentialContextNetwork(DCN)
接下来,我们考虑提出的另一种变体,其中添加了差异上下文功能,而不是仅使用它来引起注意。 前两个部分与DAN网络相同。 在第1部分中,我们使用图像,支撑和相对示例,并获得相应的图像和问题嵌入。 接下来是获得图像,支撑和对立样本的注意力向量
。 在DAN中,使用三重态损失函数对它们进行了训练,而在DCN中,我们获得了两个上下文特征,即支持上下文
和相对上下文
。 这在图3的第3部分中显示。使用以下公式可获得支持的上下文。
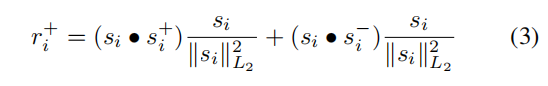
其中
是点积。 这导致获得注意力向量之间的相关性。
支持上下文 的第一项是 在 上的矢量投影,第二项是 在 上的矢量投影。 类似地,对于相反的上下文,我们计算 上 和 上 的向量投影。 这个想法是,投影测量相关向量之间的相似性。 我们从结果中减去不相关的向量。 在执行此操作时,我们确保增强相似性,并且仅删除与原始语义嵌入不相似的特征向量。 该方程式提供了支持并与图像xi的当前问题 有关的附加功能。
同样,相反的上下文也可以通过以下公式获得

接下来,我们计算支持和相对的上下文特征之间的差,即
,它为我们提供了差分上下文特征
。 然后将其与原始关注向量(DCN-Add)相加或与原始关注向量
(DCN-Mul)相乘,从而为我们提供最终的差分上下文关注向量
。 然后,这是最终注意力权重向量乘以图像嵌入
以获得向量
,然后将其与分类损失函数一起使用。 这在图3的第4部分中显示。观察到的结果注意力要比通过DAN获得的早期差异注意力特征更好,因为这些特征也用作上下文。
使用以下soft-max分类丢失函数对网络进行端到端训练
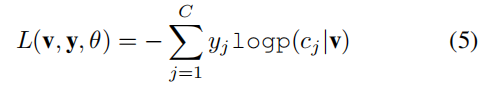
4.Experiments
实验是使用两种差异注意力进行的,这些差异被提出并与标准数据集的基线进行了比较。 我们首先分析提出的两个变体DAN和DCN的不同参数。 我们通过将网络与可比较的基线进行比较来进一步评估这两个网络,并针对最新技术水平评估性能。 进行主要评估的目的是根据注意力与人类相关性的相关性评估性能,在此方面,我们可以获得与人类注意力相关性的最新技术。 此外,我们观察到,在解决VQA任务的准确性方面,其性能得到了显着提高,并且与标准基准数据集上的最新技术水平相比具有竞争力。 我们还根据最近提出的VQA2数据集分析了网络的性能。
4.1.AnalysisofNetworkParameters
在提出的DAN网络中,我们与应考虑的k个最近邻居的数量有关。 我们在表1中观察到,在三元组网络中使用4个最近的邻居,使用VQA-1数据集可以获得与人类关注度和准确性最高的相关性。 因此,我们在实验中使用了4个最近的邻居。 我们观察到,增加最近的邻居超过4个最近的邻居会导致准确性降低。 此外,即使使用一个最近的邻居,也会带来实质性的改进,当我们移至4个最近的邻居时,该改进会略有改善。

我们还评估了通过基准模型[2]使用最近的邻居与使用支持样本和对立样本的随机分配相比的效果。 我们观察到,将DAN与随机的一组最近邻居一起使用会降低网络的性能。 在比较网络参数时,我们使用的可比较基线是使用LSTM和CNN的VQA的基本模型[2]。 但是,这不会引起注意,因此我们会谨慎评估此方法。 使用最佳的参数集,性能可将与人类注意力的相关性提高10.64%。 我们还观察到,相应的VQA性能比可比较的基准提高了4.1%。 然后,我们进一步将此模型与来自MCB [5]的模型相结合,该模型是最新的VQA模型。 这样可以将VQA的结果进一步提高4.8%,并将与人类注意力的相关性进一步提高1.2%。
在建议的DCN网络中,我们有两种不同的配置,一种是使用加法模块(DCN-add)来添加差分上下文特征,另一种是使用(DCN-mul)乘法模块来添加差分上下文特征。 。我们还进一步依赖DCN网络的k个最近邻居。这也被考虑。接下来,我们将评估使用固定缩放权重(DCN_v1)来添加差异上下文特征的效果,而不是学习线性缩放权重(DCN_v2)来添加差异上下文特征的效果。表2比较了所有这些参数结果。

从表2可以看出,在VQA数据集[2]上获得最大准确性并与人的注意力相关的配置是使用与学习权重相乘并考虑4个最近邻居的配置。在与人的注意力相关的方面,这导致VQA-1数据集的准确性提高了11%,在准确性上的提升为4.8%[2]。我们还观察到DCN与MCB的结合[5]在VQA数据集上进一步将结果提高了4.5%,与关注度的相关性提高了1.47%。将这些配置与基线进行比较。

4.2.Comparisonwithbaselineandstateoftheart
我们在人的注意力(HAT)数据集[3]上获得了与基线的初步比较,该数据集通过在解决VQA时使用区域去模糊任务来提供人的注意力。在人类之间,等级相关性是62.3%。表5中提供了各种最新方法与基准的比较。我们使用的基准[2]是我们用于获得样本的方法。这使用使用LSTM的问题嵌入和使用CNN的图像嵌入。我们还考虑了引起注意的相同变量。我们还获得了堆叠注意力网络的结果[30]。分层协同注意力工作的结果[16]是从Das等人[3]中报告的结果中获得的。我们观察到,在与人类注意力相关的等级相关性方面,使用DAN网络(具有4个最近的邻居),我们获得了大约10.7%的改善,而使用DCN网络(具有乘法模块和学习的缩放权重的4个邻居),我们得到了大约11的改善。超过可比基线的百分比。与在图像和问题上使用共同注意的“分层共同注意”工作[16]相比,我们还获得了大约6%的改进。进一步合并MCB可以改善DAN和DCN的结果,与层次式共同注意工作相比,可提高7.4%,与MCB方法相比,可提高5.9%。然而,如[3]所指出的,使用基于显着性的方法[11],该方法在眼睛跟踪数据上进行训练以获得人们以独立于任务的方式看待哪里的度量,从而与人的注意力更加相关(0.49)。但是,这是使用人的注意力进行明确训练的,并且与任务无关。在我们的方法中,我们旨在获得一种可以模拟人类解决任务的认知能力的方法。

接下来,我们在表3中评估VQA数据集[2]上不同的基准和最新技术水平。为此基准数据集提出了许多评估VQA任务的方法。在值得注意的不同方法中,分层协同注意力工作[16]在VQA任务上获得了61.8%的准确度,动态参数预测[21]方法在获得VQA任务上的准确度为57.2%,而堆叠注意力网络[30]的准确性为58.7%。我们观察到,差分上下文网络的性能好于所有基于图像的注意力方法,其准确性为60.9%。这是一个很好的结果,并且我们观察到在不同类型的问题上,性能都有所提高。此外,将方法与MCB相结合,使用DAN和DCN分别获得了65%和65.4%的改进结果,分别比MCB的结果提高了1.2%。这与我们在表5中观察到的与人类关注的改善的相关性是一致的。
接下来,我们在最近提出的VQA-2数据集上评估提出的方法[7]。此新数据集中的目的是消除不同问题中的偏见。与以前的VQA-1数据集相比,它是更具挑战性的数据集[2]。我们提供了DAN和DCN方法与堆叠注意力网络(SAN)[30]方法的比较。如表4所示,建议的方法在强大的堆叠注意力基线上获得了改进的性能。我们观察到,我们提出的方法也能够比SAN方法改善结果。与MCB结合使用时,具有4个最近邻居的DCN的准确度达到65.90%
4.3.AttentionVisualization
所提出的方法的主要目的是获得与人的注意力更好相关的改善的注意力。 因此,我们将注意力区域可视化并进行比较。 在注意力可视化中,我们覆盖注意力概率分布矩阵,该矩阵是基于查询问题的给定图像的最突出部分。 遵循的程序与Das等[3]遵循的程序相同。 我们在图4中提供了注意力可视化的结果。与SAN方法相比,使用DCN可以显着改善注意力。[30] 图5提供了使用DAN和DCN时支持和对立注意力图如何帮助提高参考注意力的图。 我们在项目网站上为注意力图的可视化提供了更多结果。



5.Discussion
在本节中,我们将进一步讨论方法的不同方面,这些方面有助于更详细地了解该方法。
我们首先考虑示例如何提高注意力。 在差异注意力网络中,我们使用样本,并使用三元组网络训练它们。 众所周知,使用三元组([8]以及更早的文献[4]),我们可以学习一种表示,该表示着重说明了图像相对于相对的示例如何更接近支持示例。 在图像和语言表示之间会引起注意。 因此,改进的图像表示有助于获得改进的注意力向量。 在DCN中,使用相同的方法进行更改,即使用投影在图像表示中也包含了差分示例特征。 在项目网站上包含有关如何理解这些方法如何定性提高注意力的更多分析。
接下来,我们考虑提高注意力是否意味着提高绩效。 在我们的实证分析中,我们观察到我们在VQA任务中获得了更多的关注并提高了准确性。 尽管可能还有其他方法可以提高VQA的性能(如MCB [5]所示),但这些方法可以与建议的方法结合使用,并且确实可以提高VQA的性能。
最后,我们考虑图像(I)和问题嵌入(Q)是否都相关。 我们考虑了这个问题,并通过仅考虑I,仅考虑Q以及使用两个Q&I的语义特征考虑了最近的邻居进行了实验。 我们已经观察到,从基准VQA模型进行的Q&I嵌入要比其他两个更好。 因此,我们认为两者都有助于嵌入。
6.Conclusion
在本文中,我们提出了两种不同的变体来获得不同的注意力,以解决视觉问题的回答问题。 它们是差分注意网络(DAN)和差分上下文网络(DCN)。 两种变体均提供了相对于基准的显着改进。 该方法提供了使用基于示例的方法改善VQA的初步观点。 将来,我们希望进一步探索该模型,并将其扩展到基于联合图像和问题的注意力模型。