������Ҫ�ο��ò��ͣ�https://blog.csdn.net/qq_27825451/article/details/90295508ֻ��ѧϰ��¼�������κ���ҵ��;��
ǰ�ԣ�������Ĵ������һ����Ϊ���ӵĹ��̣����������зdz���ġ��dz����Ի��Ŀ�Դ����ṩ������ʹ�ã����Ǽ�����ˣ�����ĴҲ���ж��ַ�������ѡ������pytorchΪ���Ӽ���˵����
������Ļ������̿��Է�Ϊ�����裬��
����ṹ�+�������ݶȸ��£������ְ��� ��ǰ��+����������ݶ�+�ݶȸ��¡���
����ʵҲ�Ǻ���pytorch��������һ������˼·
ԭʼ�����ʹ��numpyʵ��
# -*- coding: utf-8 -*-
import numpy as np# N��ѵ����batch size; D_in ��input�������ݵ�ά��;
# H�����ز�Ľڵ���; D_out �����ά�ȣ�������ڵ���.
N, D_in, H, D_out = 64, 1000, 100, 10# �������롢�������
x = np.random.randn(N, D_in) #��64��1000��
y = np.random.randn(N, D_out) #��64��10�����Կ�����һ��10��������# Ȩֵ��ʼ��
w1 = np.random.randn(D_in, H) #(1000,100),������㵽���ز��Ȩ��
w2 = np.random.randn(H, D_out) #(100,10),�����ز㵽������Ȩ��learning_rate = 1e-6 #ѧϰ��for t in range(500):# ��һ�������ݵ�ǰ��������Ԥ��ֵp_predh = x.dot(w1)h_relu = np.maximum(h, 0)y_pred = h_relu.dot(w2)# �ڶ������������Ԥ��ֵp_pred����ʵֵ�����loss = np.square(y_pred - y).sum()print(t, loss)# ����������������������Ȩֵ����grad_y_pred = 2.0 * (y_pred - y) #ע�⣺����ĵ�����Ҳ���Լ���ģ���Ϊ����ط��Ǻܼ��ĺ�������ʽgrad_w2 = h_relu.T.dot(grad_y_pred)grad_h_relu = grad_y_pred.dot(w2.T)grad_h = grad_h_relu.copy()grad_h[h < 0] = 0grad_w1 = x.T.dot(grad_h)# ���²���w1 -= learning_rate * grad_w1w2 -= learning_rate * grad_w2
ȱ�㣺
��1��û�취����ӵ�����ṹ������Ľṹ�̫�ײ�����
��2���ݶ���Ҫ�Լ��������������̫���ӣ�����̫��ͺ������ˣ�
��3��û�а취ʹ��GPU����
ʹ��torch��Tensorԭʼʵ��
import torchdtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # ����ʹ��CPU,��ʵ���Ͽ���ʹ��GPU# N��ѵ����batch size; D_in ��input�������ݵ�ά��;
# H�����ز�Ľڵ���; D_out �����ά�ȣ�������ڵ���.
N, D_in, H, D_out = 64, 1000, 100, 10# �������롢�������
x = torch.randn(N, D_in, device=device, dtype=dtype) #��64��1000��
y = torch.randn(N, D_out, device=device, dtype=dtype) #��64��10�����Կ�����һ��10��������# Ȩֵ��ʼ��
w1 = torch.randn(D_in, H, device=device, dtype=dtype) #(1000,100),������㵽���ز��Ȩ��
w2 = torch.randn(H, D_out, device=device, dtype=dtype)#(100,10),�����ز㵽������Ȩ��learning_rate = 1e-6for t in range(500):# ��һ�������ݵ�ǰ��������Ԥ��ֵp_predh = x.mm(w1)h_relu = h.clamp(min=0)y_pred = h_relu.mm(w2)# �ڶ������������Ԥ��ֵp_pred����ʵֵ�����loss = (y_pred - y).pow(2).sum().item()print(t, loss)# ����������������������Ȩֵ����grad_y_pred = 2.0 * (y_pred - y) #ע�⣺����ĵ�����Ҳ���Լ���ģ���Ϊ����ط��Ǻܼ��ĺ�������ʽgrad_w2 = h_relu.t().mm(grad_y_pred)grad_h_relu = grad_y_pred.mm(w2.t())grad_h = grad_h_relu.clone()grad_h[h < 0] = 0grad_w1 = x.t().mm(grad_h)# �������£��ݶ��½�����w1 -= learning_rate * grad_w1w2 -= learning_rate * grad_w2
����
x = x.mm(self.w) #x��w���ע��x������tensor���ſ���Ӧ�ø÷�����
torch.clamp(input, min, max, out=None) �� Tensor������input����ÿ��Ԫ�صļн������� [min,max][min,max]�������ؽ����һ����������
�����������£�
| min, if x_i < miny_i = | x_i, if min <= x_i <= max| max, if x_i > max���������FloatTensor or DoubleTensor���ͣ������min max ����Ϊʵ����������Ϊ����������ע���ƺ�������ˣ����������ͣ�min�� maxȡ������ʵ���Կɡ���
������
input (Tensor) �C ��������
min (Number) �C ���Ʒ�Χ����
max (Number) �C ���Ʒ�Χ����
out (Tensor, optional) �C �������
- .t()��ʾת��
ȱ�㣺
��1��û�취����ӵ�����ṹ������Ľṹ�̫�ײ�����
��2���ݶ���Ҫ�Լ��������������̫���ӣ�����̫��ͺ������ˣ�
�����GPU�������⡢����һ��ȱ�㡣
torch���Զ���autograd
import torchdtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # ����ʹ��CPU,��ʵ���Ͽ���ʹ��GPU# N��ѵ����batch size; D_in ��input�������ݵ�ά��;
# H�����ز�Ľڵ���; D_out �����ά�ȣ�������ڵ���.
N, D_in, H, D_out = 64, 1000, 100, 10# �������롢�������
x = torch.randn(N, D_in, device=device, dtype=dtype,requires_grad=True) #��64��1000��
y = torch.randn(N, D_out, device=device, dtype=dtype,requires_grad=True) #��64��10�����Կ�����һ��10��������# Ȩֵ��ʼ��
w1 = torch.randn(D_in, H, device=device, dtype=dtype) #(1000,100),������㵽���ز��Ȩ��
w2 = torch.randn(H, D_out, device=device, dtype=dtype)#(100,10),�����ز㵽������Ȩ��learning_rate = 1e-6for t in range(500):# ��һ�������ݵ�ǰ��������Ԥ��ֵp_predy_pred = x.mm(w1).clamp(min=0).mm(w2)# �ڶ������������Ԥ��ֵp_pred����ʵֵ�����loss = (y_pred - y).pow(2).sum()print(t, loss.item())# ����������������������Ȩֵ��������ǹؼ��ˣ�������Ҫ�Լ�д���������������Զ���ɵ�loss.backward() #һ����λ���Զ���# �����ݶȸ���with torch.no_grad():w1 -= learning_rate * w1.grad #grad���Ի�ȡ�ݶȣ���ʵ����ط������൱�����ݶ��½������Ż��Ĺ��̿����Լ����壬��Ϊ�����������w2 -= learning_rate * w2.grad#����һ��֮���ݶȹ���w1.grad.zero_()w2.grad.zero_()
ȱ�㣺
��1��û�취����ӵ�����ṹ������Ľṹ�̫�ײ㣩��
�����GPU�������⡢�����ݶȵ���Ҳ�����Լ����ˣ���������ȱ�㡣�����ھ�ֻʣһ������û����ˣ��Ǿ�����ô���ٴ�����ӡ�����������ṹ��
��2��������²���w1��w2�Ĺ�����ʵ����һ���Ż����̣��������õľ��Ǽ��ݶ��½�������������һ���ܴ��ȱ�㣬�Ǿ�������ֻ������������Ҫ�Ż������Կ����Լ�д���������ڵ������кܶ�IJ�����Ҫ�Ż������Լ�д�Ļ�ʵ����̫�鷳�ˡ����Ǿ����˺���ķ�����
ʹ��pytorch.nnģ��
���Խ�������Ϊһ���ϸ߲�ε�API��װ
# -*- coding: utf-8 -*-
import torch# N��ѵ����batch size; D_in ��input�������ݵ�ά��;
# H�����ز�Ľڵ���; D_out �����ά�ȣ�������ڵ���.
N, D_in, H, D_out = 64, 1000, 100, 10# �������롢�������
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)#ģ�ʹ��������ǰ��ؼ������𣬲�����Ҫ�Լ��ֶ����о�����ˣ���������һ����λ�ķ���
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),torch.nn.ReLU(),torch.nn.Linear(H, D_out),
)#������ʧ����
loss_fn = torch.nn.MSELoss(reduction='sum')learning_rate = 1e-4for t in range(500):# ��һ�������ݵ�ǰ��������Ԥ��ֵp_predy_pred = model(x)# �ڶ������������Ԥ��ֵp_pred����ʵֵ�����loss = loss_fn(y_pred, y)print(t, loss.item())# �ڷ���֮ǰ����ģ�͵��ݶȹ���model.zero_grad()# ����������������������Ȩֵ��������ǹؼ��ˣ�������Ҫ�Լ�д���������������Զ���ɵ�loss.backward()#���²������ݶ�with torch.no_grad():for param in model.parameters():param -= learning_rate * param.grad #����ʵ�����ݶ��½������Ż�������ͨ��ѭ���Զ�ʵ�֣���Ҫ��һ��һ��д�ˣ����������IJ������·������˺ܶࡣ���ǻ�����
������ʧ����
��������ѡ������reduce��size_average��reduction
�ܶ�� loss �������� size_average �� reduce �����������͵IJ�������Ϊһ����ʧ��������ֱ�Ӽ��� batch �����ݣ���˷��ص� loss �������ά��Ϊ (batch_size, ) ��������
(1)��� reduce = False����ô size_average ����ʧЧ��ֱ�ӷ���������ʽ�� loss
(2)��� reduce = True����ô loss ���ص��DZ���a)��� size_average = True������ loss.mean()����loss��ƽ��ֵ b)��� size_average = False������ loss.sum()��loss�ĺ�ע�⣺Ĭ������£� reduce = True��size_average = True
(3) reduction = ��none����ֱ�ӷ���������ʽ�� loss
(4) reduction = ��sum��������loss֮��,�DZ���
(5) reduction = ''elementwise_mean"������loss��ƽ��ֵ��������
(6) reduction = ''mean"������loss��ƽ��ֵ���DZ���
�ܽ
����һ�������������ǰ��������������⣬�������GPU�������⡢�����ݶȵ���Ҳ�����Լ����ˣ����ҿ��Դ���ӵ����磬����Ҫ�Լ�����һ��һ���ľ�����ˣ���������ȱ�㡣
ʹ������IJ�Σ�һЩ���������;�ûʲô�����ˣ���Ȼ���ǻ����Խ�һ���Ż�����Ϊ�������Ƕ�loss�����Զ���֮����Ҫͨ��һ��ѭ������ģ�͵ĸ�������������в����ĸ��£����������ṩ��������η�����Ż���ʩ��
ʹ��torch.optim����һ����ѵ������
��һ��ʡ���ֶ��IJ������£�����һ����λ
# -*- coding: utf-8 -*-
import torch# N��ѵ����batch size; D_in ��input�������ݵ�ά��;
# H�����ز�Ľڵ���; D_out �����ά�ȣ�������ڵ���.
N, D_in, H, D_out = 64, 1000, 100, 10# �������롢�������
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)#ģ�ʹ��������ǰ��ؼ������𣬲�����Ҫ�Լ��ֶ����о�����ˣ���������һ����λ�ķ���
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),torch.nn.ReLU(),torch.nn.Linear(H, D_out),
)#������ʧ����
loss_fn = torch.nn.MSELoss(reduction='sum')learning_rate = 1e-4
#����һ��optimizer����
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)for t in range(500):# ��һ�������ݵ�ǰ��������Ԥ��ֵp_predy_pred = model(x)# �ڶ������������Ԥ��ֵp_pred����ʵֵ�����loss = loss_fn(y_pred, y)print(t, loss.item())# �ڷ���֮ǰ����ģ�͵��ݶȹ��㣬��optimizer.zero_grad()# ���������������loss.backward()# ֱ��ͨ���ݶ�һ����λ�����������������ѵ��������һ�仰�Ż����еIJ������Dz��Ǻ�ţ��optimizer.step()
torch.optim��һ��ʵ���˶����Ż��㷨�İ��������ͨ�õķ�������֧�֣��ṩ�˷ḻ�Ľӿڵ��ã�δ�����ྫ�����Ż��㷨Ҳ�����Ͻ�����
Ϊ��ʹ��torch.optim����������һ���Ż�������Optimizer���������浱ǰ��״̬�����ܹ����ݼ���õ����ݶ������²�����
Ҫ����һ���Ż���optimizer����������һ���ɽ��е����Ż��İ��������в��������еIJ��������DZ���s�����б��� Ȼ��������ָ�������Ż��ض���ѡ�����ѧϰ���ʣ�Ȩ��˥���ȡ��DZ���s�����б��� Ȼ��������ָ�������Ż��ض���ѡ�����ѧϰ���ʣ�Ȩ��˥���ȡ�
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr = 0.0001) self.optimizer_D_B = torch.optim.Adam(self.netD_B.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))Optimizer��֧��ָ��ÿ������ѡ� ֻ������һ���ɵ�����dict���滻��ǰ�ɵ�����Variable��dict�е�ÿһ����Զ���Ϊһ�������IJ����飬��������һ��params���������������IJ����б���������Ӧ�����Ż������ܵĹؼ��ֲ�����ƥ�䣬��������������Ż�ѡ�
optim.SGD([{'params': model.base.parameters()},{'params': model.classifier.parameters(), 'lr': 1e-3}], lr=1e-2, momentum=0.9)���ϣ�model.base.parameters()��ʹ��1e-2��ѧϰ�ʣ�model.classifier.parameters()��ʹ��1e-3��ѧϰ�ʡ�0.9��momentum���������е�parameters��
�Ż����裺
���е��Ż���Optimizer��ʵ����step()�����������еIJ������и��£��������ֵ��÷�����optimizer.step()���Ǵ�����Ż�����֧�ֵļ汾��ʹ�����µ�backward()�����������ݶȵ�ʱ����������
for input, target in dataset:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()optimizer.step(closure)һЩ�Ż��㷨���繲���ݶȺ�LBFGS��Ҫ��������Ŀ�꺯����Σ����������봫��һ��closure�����¼���ģ�͡� closure��������ݶȣ����㲢������ʧ��
for input, target in dataset:def closure():optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()return lossoptimizer.step(closure)Adam�㷨��
adam�㷨��Դ��Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation)�������Ǵ��ж������RMSprop���������ݶȵ�һ�ع��ƺͶ��ع��ƶ�̬����ÿ��������ѧϰ�ʡ������ŵ���Ҫ���ھ���ƫ��У����ÿһ�ε���ѧϰ�ʶ��и�ȷ����Χ��ʹ�ò����Ƚ�ƽ�ȡ��乫ʽ���£�
���У�ǰ������ʽ�ֱ��Ƕ��ݶȵ�һ�ع��ƺͶ��ع��ƣ����Կ����Ƕ�����E|gt|��E|gt^2|�Ĺ���;
��ʽ3��4�Ƕ�һ���ع��Ƶ�У�����������Խ���Ϊ����������ƫ���ơ����Կ�����ֱ�Ӷ��ݶȵľع��ƶ��ڴ�û�ж����Ҫ���ҿ��Ը����ݶȽ��ж�̬���������һ��ǰ�沿���Ƕ�ѧϰ��n�γɵ�һ����̬Լ������������ȷ�ķ�Χ��class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)������
params(iterable)�������ڵ����Ż��IJ������߶���������dicts�� lr (float, optional) ��ѧϰ��(Ĭ��: 1e-3) betas (Tuple[float, float], optional)�����ڼ����ݶȵ�ƽ����ƽ����ϵ��(Ĭ��: (0.9, 0.999)) eps (float, optional)��Ϊ�������ֵ�ȶ��Զ����ӵ���ĸ��һ����(Ĭ��: 1e-8) weight_decay (float, optional)��Ȩ��˥��(��L2�ͷ�)(Ĭ��: 0)step(closure=None)������ִ�е�һ���Ż����� closure (callable, optional)��������������ģ�Ͳ�������ʧ��һ���հ�torch.optim.adamԴ�룺
import math from .optimizer import Optimizerclass Adam(Optimizer):def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8��weight_decay=0):defaults = dict(lr=lr, betas=betas, eps=eps,weight_decay=weight_decay)super(Adam, self).__init__(params, defaults)def step(self, closure=None):loss = Noneif closure is not None:loss = closure()for group in self.param_groups:for p in group['params']:if p.grad is None:continuegrad = p.grad.datastate = self.state[p]# State initializationif len(state) == 0:state['step'] = 0# Exponential moving average of gradient valuesstate['exp_avg'] = grad.new().resize_as_(grad).zero_()# Exponential moving average of squared gradient valuesstate['exp_avg_sq'] = grad.new().resize_as_(grad).zero_()exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']beta1, beta2 = group['betas']state['step'] += 1if group['weight_decay'] != 0:grad = grad.add(group['weight_decay'], p.data)# Decay the first and second moment running average coefficientexp_avg.mul_(beta1).add_(1 - beta1, grad)exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)denom = exp_avg_sq.sqrt().add_(group['eps'])bias_correction1 = 1 - beta1 ** state['step']bias_correction2 = 1 - beta2 ** state['step']step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1p.data.addcdiv_(-step_size, exp_avg, denom)return lossAdam���ص��У�
1�������Adagrad���ڴ���ϡ���ݶȺ�RMSprop���ڴ�����ƽ��Ŀ����ŵ�;
2�����ڴ������С;
3��Ϊ��ͬ�IJ������㲻ͬ������Ӧѧϰ��;
4��Ҳ�����ڴ����Ż�-�����ڴ����ݼ���ά�ռ䡣
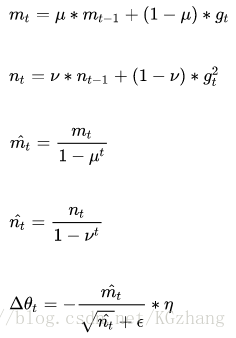
���Dz��Ǹ��Ӽ��ˣ�
�������ܽ�һ��ʹ��pytorch�����·��һ�㲽�裺
- ��һ���������Ľṹ���õ�һ��model������Ľṹ��������������������ģ�ͣ���Ȼ�������Ƕ�����-�����ģ�͡�������-�����ģ�͡�������-�����ģ�͡�������ӵ�ģ�͵ȣ����Ǻÿ����Լ�����ģ�ͣ������ٽ���
- �ڶ�����������ʧ������loss = torch.nn.MSELoss(reduction='sum')
- �������������Ż���ʽ������һ��optimizer���� optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
������ģ���Լ�ģ����ص�������������������ѵ�����岽����
- ��һ��������y_pred;
- �ڶ�����������ʧ��������loss
- ���������ݶȹ��㣬optimizer.zero_grad()
- ���IJ���������� loss.backward()
- ���²�����ʹ��step����optimizer.step()
���й۵㣺
���ѧϰ������ĵط����������㣬����������������������Լ���ʵ��˼·����Ȼ�������㲻����һ��һ��Ĵ��������Ϊ����Ҫ����������������
��1����һ���Զ�������һ�£����һ����˸��ӵġ���ά�ȡ����������ԡ��ĺ�������Ҫ�Լ�д����ʽ���ڽ��о������㣬��һ��ͺܲ���ʵ�ˡ�
��2���ڶ����������Ż�������ν��optimizer�����ã�����ÿһ�������ĸ��¹�������ģ�Ͳ����ڶ࣬������һ��һ�������£�����ûһ�����µ�ԭ�����ظ��ģ����ѧϰ��������ṩ��һ����λ�ķ�����������tensorflow����pytorch��
�����
https://blog.csdn.net/KGzhang