? 这是一篇通过卷积神经网络预测降水的文章。一直以来,专家们通过数值天气预报(NWP)的方式预测降水,但这种方法很难利用过去的时刻信息,且需要大量的数学计算和时间需求。因此,作者提出了一种数据驱动的神经网络用于降水预报。过去在深度学习方面,预测降水之前更多用的是RNN模型,如ConvLSTM,TrajGRU等模型,这些模型有着存储记忆的门单元,能对过去的时序信息有记忆功能。另一种用于预测的模型是一种Encoder-Decoder结构的模型,称为UNet。UNet本质上是CNN的一种,它没有用于记忆的单元。它可以将多个特征在通道数上叠加,然后经过UNet得到最后的输出。与之前用于做分类的任务不同,在这篇论文中,作者用它做回归,即预测具体的降水强度。
? 作者采用的是一种被称为SmaAt-UNet的模型,它建立在UNet上,在UNet的基础上加入了注意力机制,并且采用depthwise-separable卷积取代传统的卷积。实验结果证明,作者提出的SmaAt-UNet在牺牲少量的指标的情况下,能将参数量减少至原来的1/4。
首先介绍一下Attention机制。放上论文中的原话:

意思是说近些年来,注意力机制可以看成是在CNN中非常有用的一种方法。它能放大你想要关注的信号,并且抑制不想要的信号。(个人觉得作用有点像LSTM中的记忆门,记忆门的作用是选择保留输入中重要的信息。)作者在SmaAt-UNet中加入了convolutional block attention modules (CBAMs),得到的结果就相当于在各个feature map中加入权重。
? 接下来讲一下Depthwise-Separable卷积。这个卷积应该?最早是在Xception中提出的。Depthwise-Separable卷积就是由Depthwise(DW)和Separable(PW)结合而来,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。
? 先讲一下Group Convolution,它是将channels细分为成多个groups,然后分组进行卷积。如果对每个通道都进行卷积,则就是Depthwise卷积。Separable卷积就是Pointwise convolution,在卷积层中间插入1x1卷积。将二者结合,可以有效的降低模型的参数量。
? 模型结构如下:

CBAMs加在每一层Encoder的最后。需要注意的是,与UNet不同,SmaAt-UNet并不是拿每一层Encoder的最后的输出当做下一层的输入,就如上图所示,它是取的还未经过CBAM的特征图作为下一层Encoder的输入。在上采样的过程汇总,作者采用的是双线性插值的方法。
然后看一下作者在实验中的一些情况。
首先是作者制作了三种数据集,第一种是完整的,包含全部数据的数据集。但这个数据集中包含大量没有降雨的时刻,可能会对预测降水产生一定的影响,受此影响,作者又制作了两个训练集,其中分别包含不少于20%和50%的降水时刻。这两个数据集远小于第一种数据集。(这给了我们有个启示,也许用类似后面两种数据集能在预测降水方面取得更好的效果。)
第二,作者比较了UNet,UNet with CBAMs(即带注意力机制的UNet),UNet with DSC(采用depthwise-separable卷积)和SmaAt-UNet的参数量,实验中采用的depthwise-separable卷积能将参数量减少至原来的1/4,增加注意力机制会少量增加参数量。
第三,作者采用了多个评价指标,包括MSE,Precision, Recall, Accuracy and F1-score, critical success index (CSI) and false alarm rate (FAR).在训练时,作者采用的是MSE作为训练时的损失函数。原文中指出,采用MSE作为损失函数会在一定程度上使得预测的图像变得模糊。

第四,实验结果。作者以0.5mm/h为阈值,在后面两种数据集上计算了评价指标,结果如下:
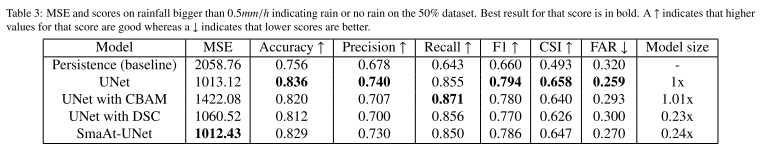

实验结果显示,四个模型的效果都要好于Persistence方法(即取上一个真实时刻直接当输出)。尽管UNet在大部分指标上做的更好,但SmaAt-UNet在略微牺牲了性能的情况下,将参数量减少了1/4。
总结一下这篇论文,尽管没有实现比UNet更好的效果,但SmaAt-UNet中加入的注意力机制和Depthwise-Separable卷积都给了我们足够多的的启示,也具有扩展性。也许在其他数据集上,这种模型能够取得更好的效果。在接下来的工作中,作者会尝试将该模型用于更多的数据集。