总览
这篇文章属机器学习公平性领域,它的中文题目为《k-NN作为用于歧视发现和预防的情境测试的实现》。作者通过k-NN分类的变体对歧视发现和预防问题进行了建模,该变体实现了情境测试的法律方法。与现有提案相比,其主要的进步在于:
提供了更强大的法律基础,克服了针对未分化群体的综合措施的弱点;
提出关于谁被歧视以及谁没有被歧视发现的全局描述;
提出一种与现有分类模型无关的防止歧视的方法;
提出一种接受区间缩放和有序属性和决策的方法。
概述
文章摘要及基本框架如下:
“在具有法律基础的情况测试方法的支持下,我们通过采用k-NN分类的变体来解决历史决策数据集中发现和预防歧视的问题。如果我们可以观察到一个元组被标记为“歧视”,那么我们可以观察到该组在属于受法律保护的群体的邻居与不属于该组的邻居之间存在明显的区别。歧视发现归结为从标记的元组中提取分类模型。通过在训练分类器之前更改标记为“歧视”的元组的标签,可以解决歧视预防问题。本文的方法克服了现有提案的法律缺陷和技术局限性。”
 文章的组织如下,首先回顾了歧视分析的法律依据,强调了现有数据挖掘方法的不足,还介绍了情境测试的法律方法;然后回顾了距离函数的概念并总结实验设置;接着介绍了基于k-NN的方法,并将其应用于歧视发现和歧视预防。
文章的组织如下,首先回顾了歧视分析的法律依据,强调了现有数据挖掘方法的不足,还介绍了情境测试的法律方法;然后回顾了距离函数的概念并总结实验设置;接着介绍了基于k-NN的方法,并将其应用于歧视发现和歧视预防。
详述
一、歧视分析
1、代表性不足原则
下面是我从网上搜集到的关于代表性不足的事例,简单说就是利用现有数据训练的模型泛化性不足。

歧视发现和预防的最新数据挖掘建议遵循了代表性不足的法律原则。根据法律规定,当一个群体受到的待遇比其他群体“差”时,就会发生歧视。一般的原则是在获得利益时(雇佣、升职、加薪等)考虑群体代表性不足,作为对受法律保护群体的歧视的定量度量。
为此,作者提到的方法如下:
令p1为受保护群体中未获得福利的比例,p2为非保护群体中未获得福利的比例,令p为两个群体中没有获得福利的比例。群体代表性不足可以用英国立法中采用的差异p1-p2来衡量;或作为比率p1/p2,称为选择提升,在美国法律中采用;或作为四重列联表中中定义的措施之一。这些方法得出的的值越高,表示受保护群体的代表人数越少。

代表性不足的原则启发了歧视发现和预防的现有方法。
the form A,B→C unveils subsets B of the dataset where the protected group A su?ered from under-representation with respect to the decision C.
不幸的是,由于对未分化人群使用聚集度量,他们既遭受法律的困扰也受到技术限制。在法律方面,典型的法律论点是真正的职业要求。若一个工作需要特殊的驾驶执照,大多数男性申请人都有,而大多数女性申请人没有,那么用p1,p2表示则不可行。在技术方面,首先,由于它依赖于频繁的项目集挖掘,因此仅处理名义属性。间隔缩放的属性(年龄,收入)和决策(贷款利率,工资)必须作为预处理步骤离散化;其次,缺乏关于谁受歧视,谁不受歧视的整体描述,如,银行分支机构经理对少数群体的歧视仍然隐藏在整个银行的大量决策中。
2、情境测试
在法律领域,情境测试是系统的研究程序,用于创建可控制的实验,以分析决策者对申请人的个人特征的公正回应。通过培训测试人员使他们(例如,一个白人和一个黑人)看起来同样适合该活动,这一对测试人员可能与情境相关的特征是平等的。即作者寻求的测试人员除了是否在受保护的群体之外,都具有类似的,在法律上可以接受的特征。如果观察到受保护组的测试者与未受保护的组的测试者之间的决策结果有显着差异,那么我们可以将负面决定归因于对受保护组的偏见。
二、 实验设置
1、距离函数
作者介绍了区间域,标称域和序数域在实验中采用的距离函数。假设i是一个属性索引,并且第i个属性域中有x,y两个值。
(1)对于区间域
首先使用zi(x) = (x ? mi)/si标准化间隔标度值,其中mi是平均值,而si是平均绝对偏差。x,y之间的距离通过其z分数的绝对差来测量:di(x,y) = |zi(x)?zi(y)|。对于未知值,如果x = ? 或y =?,di(x,y)=3。
(2)对于标称域
如果x = y,则di(x,y)= 0,否则,di(x,y)= 1。 对于未知值,如果x = ? 或y =?,di(x,y)=1。
(3)对于序数域
排名值为V1…VM的序数域,首先被映射成区间值mi(Vj)=(j-1)/(M -1)。 然后借助于绝对距离di(x,y)= | mi(x)-mi(y)|来计算距离。如果x = ?, y/=?我们通过设置di(x,y)= max {mi(x),1 ? mi(x)}处理未知值。反之亦然,如果x = y = ?,则di(x,y)= 1。
最后,元组之间的距离定义为:
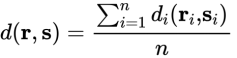
补充:按照属性值功能的不同,可把属性分为定性属性和定量属性
(1)定性属性指用文本描述对象的特征,它们的取值为集合,即使使用数值来表示,也不具备数的大部分性质,只是一个符号而已。
标称(nominal)属性:
仅提供区分对象的足够信息用于对数据对象分类(Category),比如,头发的颜色、职业,,性别(男、女)等;
序数(ordinal)属性:
属性的顺序是有意义的,通常用于等级评定,序数属性的值可以提供确定对象顺序的足够信息,如成绩等级(优、良、中、及格、不及格)等。序数属性也可以通过把数值属性分割成不同的区间来得到,比如,年龄段。
(2)定量属性是指用数值描述对象,可以比较大小,是可以量化的属性。定量属性可以使用整数值或连续值来表示,具备数的大部分性质。量属性通常含有量纲,例如,身高的量纲是cm,而薪水的量纲是元,同一量纲的数据可以比较大小,不同量纲的数据,需要通过归一化去量纲之后,比较大小才有意义。
区间(interval)属性:
区间属性是可度量的数值,用整数或实数表示,比如,年纪、薪水,其值之间的差是有意义的,即存在测量单位,如温度、日历日期等;
比率(ratio)属性
比率属性的值之间的差和比值都是有意义的,如绝对温度、年龄,长度、速度、留存率等。
2、数据集
作为运行示例,作者使用德国信用数据集,该数据集由银行帐户持有人的1000条记录组成。
三、K-NN情境测试
1、k-NN
k近邻算法(k-NN)是一种基于懒惰实例的分类方法。分类模型仅包含存储训练集。
给定要分类的元组r,首先在最接近r的训练集中通过距离量度d()搜索k个元组,即它的k个近邻;然后将其k近邻中出现最频繁的类值赋值给r。
在整篇论文中,作者将数据集表示为带有上标的元组集合R,例如,在ri中,i∈[1,|R|]是元组id。对于元组r,我们根据其与r的距离为每个ri∈R分配一个等级(作为r的邻居)。
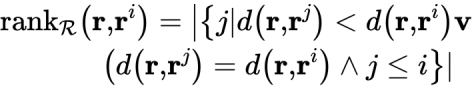
改进版本可能包括对最大允许距离的附加约束。
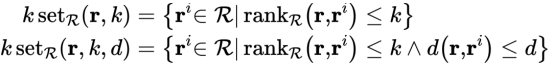
2、歧视分析的输入
除了数据集R外,我们对歧视的分析(无论是发现还是预防)都将需要以下输入:正在分析的组,一个属性上的距离函数以及决策属性。
(1)受法律保护的团体
假设将法律保护组指定为歧视分析的输入,并将其称为保护组。例如要求性别是数据的属性,并设置protected(r) iff r [sex] =female。
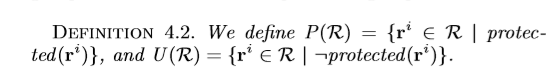
注意,R = P(R)∪U(R)不一定成立,因为具有未知值的元组将不包含在P(R)或U(R)中,例如,在前面的例子中,r [sex ] =?。
(2)合法的距离测量属性
用πG(r)来表示元组r在G中的属性索引上的投影,例如π{1,3}(< 3,5,4>)=<3,4>。我们进行以下语法假设,这有助于简化表示法。
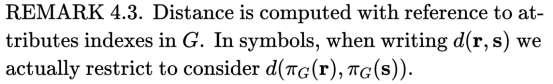
(3)决策属性
用dec(r)表示决策属性r的值。
3、 k-NN作为情境测试
假设K1和K2代表属性分别位于受保护组或不受保护组中与r的属性接近的人。注意,距离函数是在合法基础的属性上定义的,即在决定授予或不授予利益时可以合法采用的属性。对于标称属性,可以根据决策值与r相同的元组的比例p1(resp.,p2)从K1(resp.,K2)估算r的决策结果的概率。观察值p1和p2之间的差异表示由于属于保护组而对r的决策偏差。然后将之差测量为p1-p2。让我们提供一个正式的定义
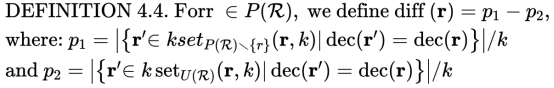
假定r为消极决策,diff(r)= t≥0(是判别歧视偏差强度的度量),表示受保护组的邻居相对于未受保护组的邻居的决策要高出t百分比,受保护组受到歧视。t<0的表示r的消极决定,无法通过对受保护组中邻居的更消极决策来解释,无法得出歧视结论。
假定r为积极决策,diff(r)≥0表示由于组成员关系而导致对肯定决策的偏见。 这可能是平权行动(也称为积极行动或反歧视)的结果,其中包括一系列旨在克服和补偿过去和现在的歧视的政策或配额。t<0意味着不能通过更好地对待受保护群体中的邻居,来解释积极的决定。
四、歧视发现
作者设计了一种发现和表征歧视的方法。对于受保护组的元组r,diff(r)衡量了歧视性偏见。通过假设diff(r)的阈值为非负值,我们可以将元组标记为已歧视或不歧视。

在标称决策属性上进行歧视发现的整个过程,显示为DiscoveryN()。
在区间缩放的决策属性上进行歧视发现的整个过程,显示为DiscoveryI()。现在需要另一个参数,即阈值L,以使dec(r)≥L表示负决策结果。
可以通过将歧视发现问题简化为分类问题来提供对已区分元组的全局描述。歧视发现现在简化为在R的标记版本上提取一个精确的分类器,disc作为类属性。准确度将通过标准度量进行评估,例如,精度率和召回率超过类别值,disc=yes。分类器的预期用途是描述性的,即为分析人员提供对发生歧视的条件的描述。

五、歧视预防
从历史决策记录的数据集开始,分类模型通常是出于从元组r的其他属性开始学习和预测决策dec(r)的目的而提取的。训练分类器时防止歧视包括平衡这两个相反的目标:最大化提取的分类模型的准确性;并尽量减少具有歧视性的预测。在我们的框架内,对于某些固定阈值t,如果分类元组是t-歧视的,则预测是歧视的。
给定一个受保护的基团和一个阈值t,为了评估预处理方法的有效性,我们建立了两个分类器:一个基于训练集T,另一个基于经过t校正的版本T’ 相对于两个量度,在测试集V上评估两个分类器:准确性和t区分。