注:该文章发表于CVPR2020,文章主体框架建立在2019年“MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation”的基础上,欢迎查阅:MS-TCN介绍
论文原题:Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
原文地址:https://arxiv.org/abs/2003.02824
论文的目标为“行为分割”(Action Segmentation),由于文章的主体网络结构建立在MS-TCN的基础之上,这里我只对本文的Contribution进行介绍。
论文的Motivation是通过使用自监督学习(Self-supervised learning)来解决训练样本及测试样本之间可能存在的Domain variation问题(例如,不同的个体,在执行相同的action时可能有不同的习惯,若在训练集(source)及测试集(target)之间存在较大的差异,则会给模型精度带来很大的影响)。所谓自监督学习,就是通过使用无需标记的样本,建立某些辅助任务(auxiliary tasks),来学得更好的特征表示,从而为目标任务带来帮助,那么现在问题就是如何设计一个好的auxiliary task,来帮助我们解决Domain variation 问题。
机器学习领域一个专门解决此类问题的方向为领域自适应(Domain Adaption, DA),属于迁移学习的一个分支。作者使用了对抗学习(adversarial learning)的方式(类似于GANs),试图通过无标记视频序列,学得Domain invariant feature,从而使得Domain variation问题得到解决。为此,作者设计了两个self-supervised auxiliary tasks, 分别用于逐帧(frame-wise)特征提取以及对时间序列片段的特征提取(sequence-wise),接下来分别对这两部分进行介绍。

1. Local SSTDA (Frame-wise)
上图的左侧部分为Local SSTDA,用于逐帧(frame-wise)特征提取的自监督学习,为了解决domain variation问题(也就是减缓source(训练数据)及target(测试数据)之间特征表示的差异性),如上文所述,这里使用类似于GANs中的对抗学习。设计一个判别器Discriminator
,用于判断我们的输入数据是源自于source还是target(二分类问题),而我们的特征提取网络则希望学得domain-invariant的特征,从而欺骗判别器Discriminator。在两者的交替更新之下,最达到纳什均衡。

2. Global SSTDA
Global SSTDA与上文所述的Local SSTDA类似,区别在于其用于提取对连续时间序列片段进行特征提取(sequence-wise),作者首先分别原始的source及target中的的完整video截成一系列片段,对每个截出的片段,使用**DATP(Domain Attentive Temporal Pooling)**进行特征提取,获得每个clip的特征向量,随后将这些源自source及target的片段进行随机打乱(shuffle)及拼接,输入后续的Discriminator进行类别预测(from source or target)。该部分的损失函数类似于Local SSTDA。
总损失函数loss function如下所示
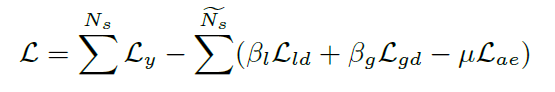
SSTDA的自监督学习部分总体框下如下图所示:
