Ŀ¼
- 1. LeNet-5
- 2. AlexNet
- 3.ZFNet
- 3. VGGNet
- 4. GoogLeNet
- 4.1 GoogLeNet V1
- 4.2 GoogLeNet V2, V3
- 4.3 GoogLeNet V4
- 5. ResNet
- 6. DenseNet
- 7. SqueezeNet
- 8. MobileNet
- 8.1 MobileNet V1
- 8.3 MobileNet V3
- 9 ShuffleNet
- 9.1 shuffleNet V1
- 9.2 shuffleNet V2
�Լ��������ʱ��һ�㶼�������е�����ģ�ͣ���������Ͻ����ġ���2012���AlexNet���֣�����Ѿ������������������ģ�ͣ�����ͼ��ʾ�� ��Ҫ��������չ����
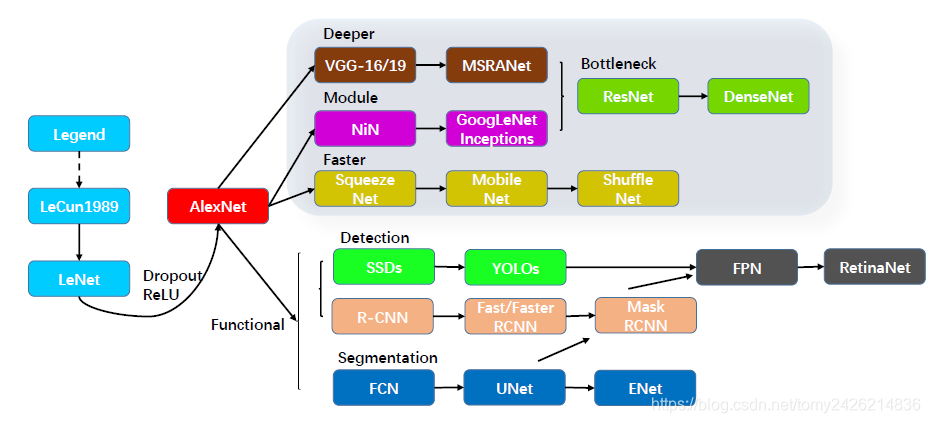
Deeper��������������������VggNet
Module�� ����ģ�黯������ṹ��Inception������������GoogleNet
Faster: ����������ģ�ͣ��ʺ����ƶ����豸����������MobileNet��ShuffleNet
Functional: ���������磬����ض�ʹ�ó�������չ����������ģ��YOLO��Faster RCNN���ָ�ģ��FCN�� UNet
�䷢չ��ʷ���Է�Ϊ�����Σ�
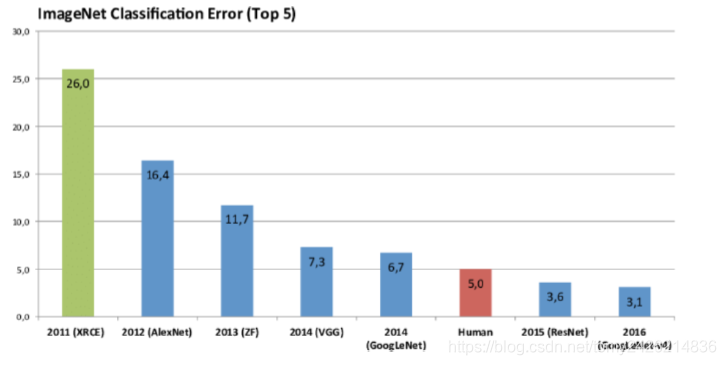
��Щģ����ImageNet�ϵı���Ч���Ա����£�
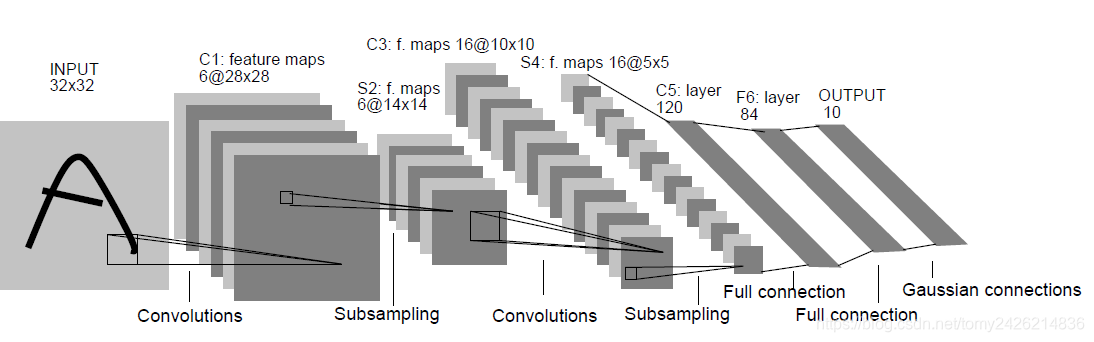
1. LeNet-5
LeNet-5��LeCun��1998���������Gradient-Based Learning Applied to Document Recognition ���������ģ�ͣ���ṹ���£������о���Ϊ55��kernel���²���Ϊ22��MaxPooling������ṹ�Ƚϼ�����LeNet-5�ṹ��Ƶ���ϸ�������μ����ο�һ���ο���
2. AlexNet
AlexNet��Alex Krizhevsky��2012������ImageNet Classification with Deep Convolutional Neural Networks���������ṹģ�����£��������������־��������������㣬��������GPU�ϣ�
AlexNet����ɫ�����ο�1���ο�2��
(1) Training on Multiple Gpus: ���ڵ�ʱ���������ƣ�Alexnet���µؽ�ͼ���Ϊ��������ֱ�ѵ����Ȼ����ȫ���Ӳ�ϲ���һ��
(2) ReLU Nonlinearity: ����ReLU���������Sigmoid��tanh, ������ݶȱ��͵�����
(3)Local Response Normalization: �ֲ���Ӧ��һ����
(4) Data Augmentation: �������ݣ���С����ϣ���һ���� ��ͼ����256x256�ٳ�224x224������ˮƽ��ת���ڶ����� �ı�RGB��ɫͨ��ǿ�ȡ�
(5) Dropout: ��һ������������Ԫ�������С����ϡ�
3.ZFNet
ZFNet��2013�������Visualizing and Understanding Convolutional Networks���������2013��ILSVRC�Ĺھ�����ƪ����ʹ�÷�������Deconvnet�������ӻ�����ͼ��feature map����ͨ�����ӻ�Alex-netָ����Alex-net��һЩ���㣬���������ṹ��ʹ�÷�������������CNN������ӻ�����Ŀ�ɽ֮��������ͨ�����ӻ�������ΪʲôCNN�зdz��õ����ܡ�������CNN���ܣ�Ȼ����е������磬����˾��ȣ��ο����£�
ZFNetͨ���Ľṹ�еij�������ʵ�ֶ�AlexNet�ĸ���������˵�������������м������ijߴ磬�õ�һ��IJ������˲����ߴ��С��������ṹ�����ֱ�ʾͼ���£�
�����AlexNet��Ľ����£���ImageNet top5 error��16.4%������11.7%��
(1) Conv1: ��һ���������ɣ�1111, stride=4����Ϊ��77��stride=2��
(2) Conv3, 4, 5: �������ģ���������˵�ͨ������384,384,256��Ϊ512,1024,512
3. VGGNet
VGGNet��2014������Very Deep Convolutional Networks for Large-scale Image Recognition �������2014���ImageNet�����У��ֱ��ڶ�λ�ͷ������������ȡ�õ�һ���͵ڶ���������Ҫ�Ĺ�����չʾ���������ȣ�depth�����㷨�������ܵĹؼ����֣���ṹ���£�
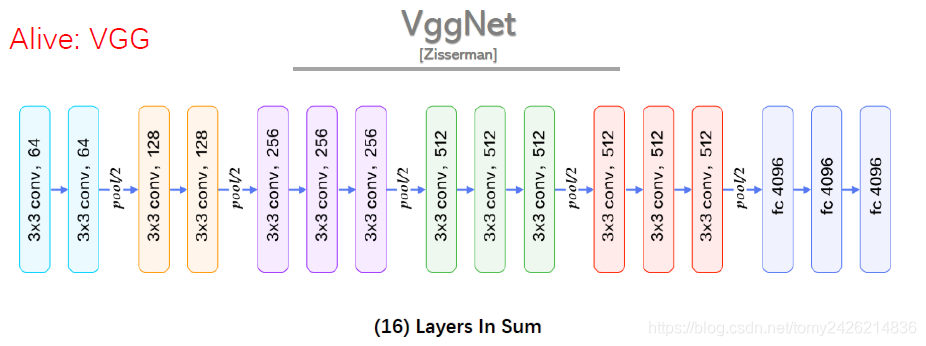
VGGNet����ɫ��(�ο�1�� �ο�2)
(1)�ṹ��ࣺ5������㡢3��ȫ���Ӳ㡢softmax����㹹�ɣ������֮��ʹ��max-pooling����أ��ֿ����������㼤�Ԫ������ReLU������
(2)С�����˺Ͷ�����ˣ�VGGʹ�ö����С�����ˣ�3x3���ľ��������һ�������˽ϴ�ľ����㣬һ������Լ��ٲ�������һ�����൱�ڽ����˸���ķ�����ӳ�䣬����������������/����������
VGG��������Ϊ����3x3�ľ����ѵ���õĸ���Ұ��С���൱һ��5x5�ľ�������3��3x3�����Ķѵ���ȡ���ĸ���Ұ�൱��һ��7x7�ľ����������������ӷ�����ӳ�䣬Ҳ�ܺܺõؼ��ٲ���������7x7�IJ���Ϊ49������3��3x3�IJ���Ϊ27��������ͼ��ʾ��
VGGNet����Ľ��ۣ�
(1) LRN�����������棨A-LRN��:AlexNet�����õ���LRN�㣨local response normalization���ֲ���Ӧ��һ������û�д������ܵ�����
(2) ����������ӣ�������������ߣ���11�㵽19�㣩
(3) ���С�����˱ȵ�������������ܺ�
4. GoogLeNet
4.1 GoogLeNet V1
GoogLetNet V1����2014������Going deeper with convolutions������ģ�ILSVRC 2014��ʤ���ߡ������VGG���䲢���ǵ����Ľ���������������Inceptionģ��ĸ���������ܺ�VGG��࣬�����������١�
Inception���ԭ��ͳ����Ϊ�˼��ٲ���������С����ϣ���ȫ���Ӻ�һ�����ת��Ϊ���ϡ�����ӣ����Ǽ����Ӳ���ԷǾ���ϡ�����ݵļ���Ч�ʲΪ�˼ȱ�������ṹ��ϡ���ԣ����������ܼ�����ĸ��������ܣ�Inception����ṹ����Ҫ˼����Ѱ�����ܼ��ɷ����������žֲ�ϡ�����ӣ�ͨ������һ�֡�������Ԫ���ṹ�����һ��ϡ���ԡ��������ܵ�����ṹ
Inception�Ľṹ����ͼ��ʾ��
Inception�ܹ��ص㣺
(1)����Ļ����Ͻ��мӿ���ϡ�������ṹ�����ܲ������ܵ����ݣ�����������������֣����ܱ�֤������Դ��ʹ��Ч��
(2) ���ò�ͬ��С�ľ�������ζ�Ų�ͬ�ĸ���Ұ�������channel��ƴ�ӣ���ζ�Ų�ͬ�߶ȵ������ں�
(3)����11������һ�Ǽ���ά�������ټ������Ͳ����������������Լ�����ӷ��������������ÿ��11����ReLU�������
��InceptionΪ����ģ�飬GoogLeNet V1����������ܹ����£���22�㣩��
GoogLeNet V1������ɫ�����ο�1�� �ο�2��
(1) ����Inceptionģ�黯�ṹ������������
(2) ����Average Pool ������ȫ���Ӳ㣨���Network in Network����ʵ�������һ�㻹��������һ��ȫ���Ӳ㣬������finetune��
(3) ��������������������softmax��֧(incetion 4b��4e����)�����������㣬һ��Ϊ�˱����ݶ���ʧ��������ǰ�����ݶȡ�����ʱ�����һ����Ϊ0����ʽ�����Ϊ0�����ǽ��м�ijһ������������࣬��ģ���ں����á�����loss=loss_2* 0.3 * loss_1 + 0.3 * loss_0��ʵ�ʲ���ʱ������������softmax��֧�ᱻȥ����
4.2 GoogLeNet V2, V3
GoogLeNet V2, V3����2015������ Rethinking the Inception Architecture for Computer Vision ���������Ҫ�Ƕ�V1�ĸĽ���
GoogLeNet v2��Inception�ṹ������ļܹ����£�
GoogLeNet V2�����ص㣺
(1) ���VGG��������33��������һ��55���������Ͳ�������������ٶȣ�����ͼFigure5��Inception��
(2)���ǽ��˲�����Сnxn�ľ����ֽ�Ϊ1xn��nx1��������ϣ�7x7�����൱������ִ��1x7������Ȼ�����������ִ��7x1����������ͼFigure6��Inception�������������ǰ��ʹ�����ַֽ�Ч�������ã����жȴ�С������ͼ��feature map����ʹ��Ч���Ż���ã�����ͼ��С������12��20֮�䣩
(3) Ϊ��ͬʱ����������ʾ�����ͼ����������ػ��;�������ִ���ٺϲ�������ͼ��ʾ��
GoogLeNet V3: V3������ΪV2�涨�����������Ľ������ʹ������������:
(1)����RMSProp�Ż���
(2) ѧϰFactorization into small convolutions��˼�룬��7x7�ֽ������һά�ľ�����1x7,7x1����3x3Ҳ��һ����1x3,3x1���������ĺô����ȿ��Լ��ټ��㣨����ļ����������������������磩���ֿ��Խ�1��conv���2��conv��ʹ��������Ƚ�һ�����ӣ�����������ķ����ԣ�����ֵ��ע��ĵط������������224x224��Ϊ��299x299�����Ӿ�ϸ�����35x35/17x17/8x8��ģ�顣
(3) �ڸ����������е�ʹ��BatchNorm��
(4) ���ñ�ǩƽ�������ӵ���ʧ��ʽ�е�һ�����滯������ɷ�ֹ�������������š���ֹ������ϣ�
4.3 GoogLeNet V4
GoogLeNet V4(Inception V4)����2016������� Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning ���������Ҫ�����òв����磨ResNet�����Ľ�V3���õ�Inception-ResNet-v1��Inception-ResNet-v2��Inception-v4���硣
5. ResNet
ResNet�Ǻο�����2015�������Deep Residual Learning for Image Recognition �������ResNet��������˲в�����ṹ���������ǰ���������ѵ�������⣬�����������GoogLeNet��22����ߵ���152�㡣�в�����(bottleneck)�Ľṹ���£����ο�1��
��ȴ�ͳ���磺y=f(x)��ResNet Block��ʽΪ��y=f(x) + x�����Գ�֮Ϊskip connect������������Ҫ˼���£�һ���䵼���ܱ�ԭ������1��������ʹԭ������Сʱ��Ҳ�ܴ�����ȥ���ܽ���ݶ���ʧ�����⣻ ����y=f(x) + xʽ���������˺��ӳ�䣨��f(x)=0ʱ��y=2����������������ʱ��������˻����⡣
ResNet�ɶ��Residual Block���ӳɵģ���ṹ���£�
����Resnet-18/34���õ�residual block��Resnet-50/101/152��̫һ�����ֱ�������ʾ��
���˲в�ṹ��ResNet��������ϸ����Ҫ��ע�£�
(1)��һ�������������7*7�Ĵ�����ˣ�����ĸ���Ұ����ȡͼƬ����ij�ʼ������primary feature��(ͼƬchannel=3����һ��ʹ�ô�kernel�����ӵIJ��������Ǻܴ�)
(2)��·�����У���������ά�Ȳ�һ��ʱ������ֱ����ӣ�Element-wise add�������ò���Ϊ2�ľ�������Сά�ȳߴ磿
6. DenseNet
DenseNet��������2017������ Densely Connected Convolutional Networks ���������ResNetһ�£�Ҳ����shortcut���ӣ������佫ǰ�����в��������ܼ����ӣ�dense connection��, ���������channel concatenate��ʵ���������ã�����ResNet��Element-wise addition��������������ṹ����ͼ��ʾ��
DenseNet�������Dense Block��Transition layer��������ģ�飬Dense Block������ResNet�е�residual block��������Ա����£�
����ͼ���Է���������Ҫ���𣺣��ο�1��
(1) DenseNet���ܼ����ӣ�ǰ���ͺ����䶼�����ӣ�ResNetֻ�����ڲ�������
(2) DenseNet��channel-wise concatenation�� Resnet ��Element-wise addition
DenseNet��Transition layer��Ҫ����������feature map�ijߴ磬�����Բ�ͬ���feature map�仯Ϊͬ�ȳߴ�����concatenate����ṹ���£�
BN + ReLU+11 Conv + 22 Average Pool
DenseNet���ص㣺
~~> ��(1) �����ܼ����ӷ�ʽ��DenseNet�������ݶȵķ�����ʹ�����������ѵ�� ��ÿ�����ֱ����������źţ�
(2) ������С�Ҽ������Ч ��concatenate��ʵ���������ã���������С��
(3) �����������ã�������ʹ�õ��˵ͼ�����
(4) ��Ҫ�ϴ���Դ�������У����в㶼��洢����~~
���https://zhuanlan.zhihu.com/p/66215918
https://zhuanlan.zhihu.com/p/22038289
��������Щ���͵ľ������磬���н�������Ҫ�Ľϴ������������������������ò�ͬ����ƺ�ģ�ͼܹ�����Ӧ���ƶ����豸�ϵ�ʹ�ã�Ŀǰ��Ҫ��������������� SqueezzeNet, MobileNet��ShuffleNet���䷢չ��ʷ���£�
��Щ����ʵ������������Ҫ�������£�
(1) �Ż�����ṹ�� shuffle Net
(2) ��������IJ����� Squeeze Net
(3) �Ż��������㣺 MobileNet(�ı������˳��)�� Winograd(�ı�������㷽ʽ)
(4) ɾ��ȫ���Ӳ㣺 Squeeze Net�� LightCNN
7. SqueezeNet
SqueezeNet����2017������� SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size ������� squeezeNet��ģ��ѹ��������Ҫ��������(Idea from GoogLeNet) ���ο�1��
(1) ��ʹ��11�ľ�������ʹ��33�ľ��������ٲ�����
(2) 3*3�������ø��ٵ�channel��
(3) �����������ã����Ƴ�ʹ��Pooling���Ӷ����Ӹ���Ұ�������ܶ�Ļ��feature
SqueezeNet�����������Ԫ��Fire Module�����fire module�ѵ������pooling���SqueezeNet������ͼ��ʾ�����ұ����ż�����shortcut��
Fire Module�ְ��������֣�squeeze layer �� Expand layer������ͼ��ʾ��
squeeze layer����Ҫ��1*1�ľ�����������channel����ѹ���������˵ĸ���ΪS1
expand layer��11�ľ�������ΪE1��33�ľ�������ΪE3����ͼ��E2Ӧ��ΪE3����Ȼ�����concate��
�����й���E1�� E3��S1�Ĺ�ϵ�������£�
8. MobileNet
8.1 MobileNet V1
MobileNet V1����2017��Google������ MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications �����������Ҫѹ����������ȿɷ������(Depthwise separable Convolution)�����������������ͼ��ʾ��

(1) ��Ⱦ��������������Ϊ��ͨ������ʽ���ڲ��ı���������ͼ�����ȵ�����£���ÿһͨ�����о����������õ�����������ͼͨ����һ�µ��������ͼ������ͼ������12��12��3������ͼ������5��5��1��3����Ⱦ���֮�õ���8��8��3���������ͼ������������ά���Dz����3��
(2)����������11�ľ���������Ⱦ����õ�������ͼ������ά������ͼ��8��8��3������ͼ��ͨ��113256�ľ��������88256���������ͼ��
�������ͼ������Աȣ�
��ȿɷ�������ʹ�ͳ������Ȳ����Ͳ������٣�����ͼ��ʾ�����Է�����ȿɷ�������������Ͳ������Ǵ�ͳ�����ģ�1/N +1/Dk2��, ����3*3����ʱ��Լ��1/9������ģ�;��ȴ��ֻ����1%��
ģ�ͽṹ�Աȣ�
��ȿɷ��������Ԫ��ȴ�ͳ������һ��ReLU6�������1*1�����㣬�Ա�����ͼ��
MobileNet V1���������ܹ�����ͼ, �����Ⱦ����Ķѵ���s2��ʾ����Ϊ2������ (�ο�1)
MobileNet V1����������ṹ����������һ��ѹ�����磬��Ҫ����kernel����Ⱥͳߴ������棬����ͼ��
8.2 MobileNet V2
MobileNet V2����2018������� MobileNetV2: Inverted Residuals and Linear Bottlenecks ���������V1�ľ�����Ԫ�����˸Ľ�����Ҫ������Linear bottleneck��Inverted residuals��
(1) Linear bottleneck : ��ԭʼV1ѵ��ʱ���׳��־��������Ϊ�յ�������������ReLU�������Ե�ά����ReLU���㣬�����������Ϣ�Ķ�ʧ�����ڸ�ά�Ƚ���ReLU����Ļ�����Ϣ�Ķ�ʧ�����٣��ο��������ȥ��������Ԫ�����һ��ReLU������
��Linear bottleneck: Eltwise + with no ReLU at the end of the bottleneck��
(2) Inverted Residual: ��Ⱦ�������û�иı�channel�������������Ƕ���ͨ��������Ƕ���ͨ�����������ͨ�����ٵĻ���DW��Ⱦ���ֻ���ڵ�ά���Ϲ���������Ч��������ܺã���������Ҫ�����š�ͨ������Ȼ�����Ѿ�֪��PW������Ҳ����1��1��������������ά�ͽ�ά���ǾͿ�����DW��Ⱦ���֮ǰʹ��PW����������ά����ά����Ϊt��t=6��������һ������ά�Ŀռ��н��о�����������ȡ����������ٽ��н�ά��
(Inverted Residual: expand - transfer - reduce)
�Ա���V2��ResNet�Ľṹ������ͼ�����Է���V2����������������ά����ResNet����ά����������ά���෴����˳�ΪInverted residual.
Linear bottleneck��Inverted Residual���ͣ�
�Ա���V1��V2�ľ����ṹ��Ԫ������ͼ��V2�����һ���ReLU6������Linear����������shortcut������ά�ͽ�ά(���ұߵ�stride=2��С�ߴ磬����û��shortcut)��
MobileNet V2������ṹ����ͼ��
8.3 MobileNet V3
MobileNet V3��2019�������Searching for MobileNetV3 ���������û���꣬�п�����ӡ�
9 ShuffleNet
9.1 shuffleNet V1
shuffleNet V1 ��2017��������ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices ������ģ�����Ҫѹ��˼·��group convolution �� channel shuffle�����ο�1���ο�2��
(1) group convolution(�������): ���������˼·�ǽ���������ͼ��ͨ������Ϊ���飬Ȼ����ò�ͬ�ľ������ٶԸ�������о����������ή�;����ļ���������ͳ�ľ����Ǿ�����������ͨ���Ͻ��о�������ȫͨ�������������������ͨ���ϵ�ϡ�����������ͼ��ʾ����mobileNet����һ������ķ����������������ͨ����һ����
(2)channel shuffle(ͨ����ϴ) : ���������һ�������Dz�ͬ��֮�������ͼ��Ϣ��ͨ�ţ��ͺ�����˼���������ɵ�·����Ҹ��߸��ģ��ή�������������ȡ������MobileNet�Dz����ܼ���1*1pointwise convolution����ͨ�������ںϣ��������ϴ�channel shuffle��˼·�ǶԷ������֮�������ͼ������˳����д����������У�������һ�������������������Բ�ͬ���飬��Ϣ�����ڲ�ͬ��֮����ת��channel shuffle��ʵ�ֲ�������ͼ��ʾ��reshape�Ctranspose-flatten
shufflleNet V1����Ļ�����Ԫ����ͼ��ʾ�����aͼ�У�bͼ��1x1���ܼ��������ɷ��������������һ��channel shuffle������3x3��depthwise convolution֮��û��ʹ��ReLU�������ͼc�������stride=2��ͬʱ��elment-wise add ������concat��
shuffleNet V1�ص㣬�Լ���ResNet��mobileNet�ĶԱ����£�
ShuffleNet V1������ܹ����£�ÿ��stage����shuffleNet������Ԫ�Ķѵ���
9.2 shuffleNet V2
shuffleNet V2 ��2018��������ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design������ģ� �����������ƿ��ٵ�������ģ�����������ָ�����루Guidelines����
(1)G1�� �������������������ͨ�������ʱMAC��С����ʱģ���ٶ����
(2)G2�� ����� group����������MAC���Ӷ�ʹģ���ٶȱ���
(3) G3�� ģ���еķ�֧����Խ�٣�ģ���ٶ�Խ��
(4) G4��element-wise������������ʱ������Զ����FLOPs�ϵ����ֵ���ֵҪ�࣬���Ҫ�����ܼ���element-wise������
�����н��ŷ�������������ģ��Υ������Ӧ��ԭ���룬����ͼ��ʾ��
�����������guidelines���������shuffleNet V2�Ļ�����Ԫ������ͼ��
(1) channel splitȻ��concat����֤�������channelһ�£���ѭ��1��
(2) ȥ��1*1�ķ������(channel split�൱�ڷ�����)����ѭ��2
(3) channel split�ͽ�channel shuffle�ƶ������棬��ѭ��3
(4)����concat����add����ѭ��4