研究了骨骼关节的特征表示和动作识别的时间动力学建模问题。传统方法一般使用依赖于某些节点的相对坐标系,只对长期依赖进行建模,而不考虑短期和中期依赖。我们不以原始骨架作为输入,而是将骨架转换为另一个坐标系,以获得对尺度、旋转和平移的鲁棒性,然后从中提取显著运动特征考虑到不同时间步长的长短期记忆(LSTM)网络能够很好地建模各种属性,我们提出了一种新的基于骨架的动作识别集成时域滑动LSTM (TS-LSTM)网络。该网络由短期、中期和长期TS-LSTM网络组成。在我们的网络中,我们利用多个部分之间的平均集合作为最终特征,以捕获各种时间依赖性。我们评估了所提出的网络和附加的其他架构,以验证该方法的有效性。并在五个具有挑战性的数据集上与其他几种方法进行比较。实验结果表明,我们的网络模型通过不同的时间特征实现了最先进的性能。此外,通过对多部分softmax特征的可视化,分析了识别动作与多项TS-LSTM特征之间的关系。
介绍
人类动作识别是计算机视觉研究人员所研究的具有挑战性的任务之一。它有许多重要的应用,包括视频监控、人机交互、游戏控制、体育视频分析等。传统的行为识别研究主要集中在对行为的识别上。在单目RGB视频序列中,单目视频传感器很难完全捕捉三维空间中的人体动作。在过去的几十年里,随着三维数据采集技术的快速发展,大量关于三维数据中人类活动识别的研究得以积极开展。
人体可以用一种称为人体骨架的棍状图形来表示,它由关节连接的线段组成,关节的运动是整个图形[1]运动估计和识别的关键。因此,如果能够在三维空间中可靠地提取和跟踪人体骨骼,则可以通过对骨骼的时间运动进行分类来进行动作识别。目前,利用实时骨架估计算法,深度传感器可以获得可靠的关节坐标[15,22]。这些有效的姿态估计技术促进了基于骨架的动作识别的研究。
基于人体骨架的动作识别有两个相关问题。第一个是输入数据的问题。变化,如比例,旋转和平移,另一个是人类行为的建模,是可变的,动态的,彼此相似的。现有的基于骨架的动作识别方法大多使用相对关节坐标[17,16,6],忽略了骨骼关节的绝对运动。在人类行为建模方面,近期研究表明,长短期记忆(LSTM)网络[6,24,10]优于时间金字塔[17,12,16]和隐马尔科夫模型[21,20]。然而,这些LSTM网络只是对骨骼关节的整体时间动态进行建模,而没有考虑骨骼关节的详细时间动态。在本文中,我们提出了一种新的动作识别集成时域滑动LSTM网络。图1给出了我们模型的概述。首先,我们对输入骨架序列的坐标进行变换,使数据具有缩放、旋转和平移的鲁棒性。其次,我们没有使用简单的关节位置,而是使用了时间差异方面的运动特征。

图1:提出的深度学习网络的系统概述。该系统主要由坐标变换、运动特征提取、多项LSTMs和集成深度学习四个阶段组成。
这有助于我们的网络聚焦于实际的骨骼运动。第三,采用包含短期、中期和长期三种lstm的多周期lstm对运动特征进行处理,对变化的时间动态具有鲁棒性。最后,多术语LSTMs通过集成捕获各种动作动力学。
相关的工作
在本节中,我们简要回顾现有文献与提出的处理基于人体骨架的行动识别的两个主要问题的模型密切相关。一是骨架输入序列的特征表示,二是动作识别的时间动态建模。Wang et al.[17]通过关节的两两相对位置来表示人体运动,具有更多的区别特征。Cho等人[4]标准化了骨架的方向,这样每个骨架都可以在原点有根。利用身体各部分对之间的相对几何关系,Vemulapalli等人[16]表示李群中人体部位的三维几何关系。Du等,[6]利用Cho等人[4]标准化了骨架的方向,这样每个骨架都可以在以髋关节中心、髋关节左、髋关节右关节坐标为坐标系原点。这种相对坐标系在对骨骼关节的绝对运动进行分类时,会造成对动作的误解。
Wang等人[17]提取出三维关节位置和局部占用格局,然后进行处理傅里叶时间金字塔(FTP)表示动作的时间动力学。Vemulapalli等人[16]就业动态时间扭曲(DTW)和FTP来处理速率变化、时间错位、噪声等问题。Luo等人[12]提出了一种新的字典学习方法,该方法没有建模特征的时间演化。时态金字塔匹配,保存时态信息。Xia等[21]采用基于直方图的三维人体姿态表示,然后使用离散隐马尔可夫模型(HMM)识别动作。Wu和Shao[20]提取了高水平的骨骼关节特征,然后利用它们估计HMM的发射概率来推断动作序列,尽管DTW、FTP和HMM等方法在处理时间动态方面很有用,但最近使用的LSTM网络在建模时间动态方面表现出了优于传统方法的性能。Du等人[6]提出了一种递归神经网络,将低级身体部位的时间表示建模并组合为高级身体部位的表示。利用新的正则化方法开发了端到端全连接的深度LSTM网络,用于学习骨骼关节的共现特征。Liu等人[10]在LSTM中引入了一种新的门控机制来学习序列数据的可靠性,并相应地调整其对存储在记忆单元中的长期上下文信息的更新效果。由于这些研究一般只观察到人类行为的长期记忆,因此很难对包括短期、中期行为等在内的各种时间动态进行完整的建模。
贡献
我们的主要贡献安排如下:
我们研究了人体骨骼的特征表示,以获得对各种变化的鲁棒性和提取显著运动。实验表明,该特征表示方法能显著提高动作识别的性能。我们利用一个多期滑动LSTM网络集合,它可以分别捕获短期、中期、长期的时间依赖性,甚至空间骨架姿态依赖性。不同于传统的集成研究,我们的模型有效地学习不同的空间和时间动态行为属性。
我们对MSR进行综合评价Action3D数据集[9],UTKinect-Action数据集[21]NTU RGB+D数据集[14],西北- ucla数据集[19]和UWA3DII数据集[13]。实验结果表明,我们的网络模型明显优于先前开发的基于骨架的动作识别方法。
系统模型:在本节中,我们首先介绍所提议的系统的特征表示,包括输入骨架的提取和运动特征的提取。接下来,我们给出了时域滑动LSTM作为系统的一个具体模块。最后,我们解释了整个体系结构,包括培训和测试过程。
特征表示:
如图2(a)所示,在得到骨架时,原始输入骨架可以进行一次方向错位。换句话说,尽管骨架包含在相同的动作类别中,但是由于方向不对称,骨架的运动可能具有不同的属性。为了解决这个问题,我们需要将原始坐标系转换为人类认知坐标系,其方向一致性如图2(b)所示。

图2:特征表示过程。(a)原始输入骨架框架(st)。(b)转换后的输入骨架框架(?st)。(c)提取出显著运动特征(xt)
让s i t∈R3×1为第t个骨架框架第i个关节的坐标。变换后的骨架关节坐标为:
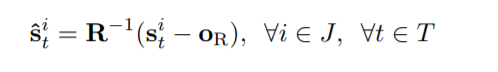
式中,J和T分别表示骨架关节和框架指标的集合。式(1)中,得到旋转矩阵R和旋转原点或为:
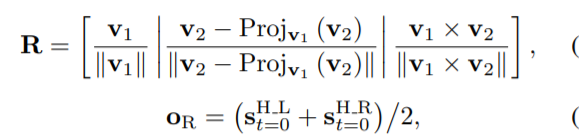
其中v1和v21分别是每个序列中与地面垂直的向量和与初始骨架髋左关节和髋右关节的差向量。(2)Projv1(v2)和v1乘以v2表示向量v2在v1上的投影以及这两个向量的外积。(3)H L t=0和sH R t=0分别表示各序列初始骨架髋左右关节的坐标。图2(c)为显著运动特征提取过程。我们使用两帧之间的时间差异,而不是使用骨骼关节坐标。当骨架关节坐标只关注当前位置时,运动特征可以捕捉到骨架关节[8]的实际运动。在此基础上,我们进一步利用运动特征作为所提架构的输入特征。让?圣∈RSIN乘以1为第t个坐标系的转换骨架坐标,SIN为所提系统的输入维数。然后得到变换后的骨架坐标:

其中concat([elements], 0)和|J|分别表示元素沿第0轴的拼接和集合J的元素个数。得到运动特征b:

其中D为时间差偏移量。这些运动特征根据D可以变成各种形式,并通过(D + 1)进行归一化,我们可以同时使用转换后的骨架坐标和运动特征作为输入特征。它们被缩放成厘米的单位,这使得我们的模型运行良好。
时间滑动LSTM一般情况下,LSTM网络被用来建模时序动态[7]。虽然遗忘之门。
网络可以帮助短期和中期依赖性的获得,但要完全忘记LSTM细胞的记忆几乎是不可能的。为了对这些依赖关系进行建模,我们提出了时间滑动LSTM (TS-LSTM)模块。如图3所示,由于第l个TS-LSTM模块可以有不同的LSTM网络号(Nl)、LSTM窗口大小(Wl)和时间跨度(T Sl),因此在对具有可变时间动态的动作进行分类时非常有用。换句话说,在识别序列长度可变的动作时,我们只需要调整TS-LSTM的窗口大小和跨距。

设x l t为第l个TS-LSTM的输入,Dl为其差置。用Dl D(5),输入的l th TS-LSTM选为x l t =?圣??圣?Dll(0≤≤5)和x l t =?圣(l = 6),如图4所示。将第l TS-LSTM的第n个LSTM的第t帧输出,得到存储单元、三个门和第l个TS-LSTM的第n个LSTM的第t帧输出为:

其中,是s型函数,是i l n tf l n t, c l,n t, o l,n t, h l,n t分别是TS-LSTM的第n个LSTM的第t个帧的输入门、遗忘门、细胞激活、输出门和输出向量。(6)-(9)中,所有矩阵wl,n mn都是第l个TS-LSTM的第n个LSTM的n到m的连接权值。

图4:短期、中期、长期和位姿TS-LSTM模块组成的整体架构,其中短期l = 0,中期l = 1,2,长期l = 3,4,5,位姿特征l = 6。
提出了网络体系结构:
如图4所示,所提出的体系结构由Dl确定的多个TS-LSTM模块组成,王,T Sl。体系结构根据过程的类型(如培训和测试)有不同的结构。在培训过程中,各部分主要由TS-LSTM层,和池(SumPool)层,线性(LN)层,softmax激活层和交叉层计算代价函数。在测试过程中,我们没有使用交叉熵层,我们利用各种softmax输出的平均集合作为GoogLeNet[5]的最终输出。令xl mt是第m个序列的xl t。将x l,m t代入x l t (6)-(9), h l,n t(10)可以写成h l,n,m t。的得到第l个TS-LSTM的第n个LSTM的第m个序列的SumPool和MeanPool值为:
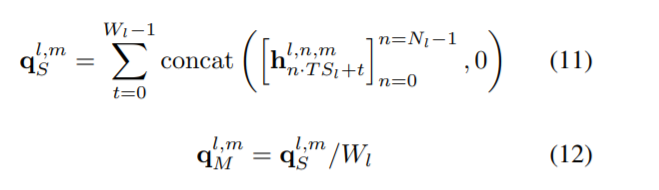
在[n (·)n=0 =[(·)0,(·)1,…,(·)Nl?1]第l个TS-LSTM的第n个LSTM的第m个序列的均值,q l,mM = q l, M年代/王。在每一部分中,将第m个序列的SumPool和MeanPool的值串联为:

在[?]T表示转置运算。得到各部分的线性活化为:
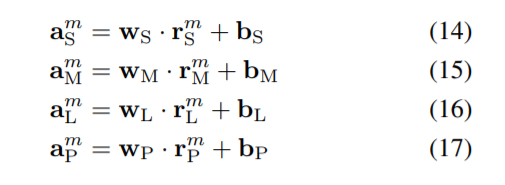
其中w和b2分别为LN层的权值和偏置项。让一个m, k年代米,kM, a M,kL和m,kP是m的第k个动作类值年代一个米米、一个米L和a mP,分别。然后用softmax函数对第m个序列的线性激活值进行归一化:

其中c和NC分别为对应的类索引和操作类总数。为了求出所有训练样本的最大似然值,我们将交叉熵函数应用于两个目标函数:

其中,y m c和NM分别为第m个样本的ground-truth label和训练样本总数。我们分别通过最小化两个目标函数来训练模型。
在测试过程中,对Pr (c|a m)等三个线性激活值进行平均,得到集成输出v1年代),公关(c |米米)和公关(c |米l),利用4个线性激活值(Pr (c|a m)中的平均集成,得到集成输出v2年代),公关(c |米米),公关(c |米l)和Pr (c|a m)。
实验:
在本节中,我们评估了提出的模型,并与五个基准数据集上的几种最新方法进行比较:MSR Action3D数据集[9]、UTKinect-Action数据集[21]、NTU RGB+D数据集[14]、NorthwesternUCLA数据集[19]和UWA3DII数据集[13]。分析了识别动作与多项TS-LSTM特征之间的关系。
为了显示所提技术的效果,我们在五种不同架构下进行了实验。第一个是简单的LSTM,用作的基线基于骨架的动作识别的LSTM。第二个模型将人类认知坐标应用到第一个模型中,显示了人类认知坐标的作用。第三种方法将显著运动特征应用到第二种方法中,显示了显著运动特征的效果。第四种方法是采用代价为(22)的TS-LSTM v1集成。最后一个是使用c的组合TSLSTM v2。
数据集和参数设置:
MSR Action3D数据集:该数据集是使用Kinect等深度传感器捕获的。它由10个被试进行2 - 3次的20个动作组成。总共有557个有效动作序列,序列中的每一帧由20个骨骼关节组成。UTKinect-Action数据集:该数据集是使用单一的静止Kinect捕获的。它由10个不同的被试执行10个动作组成,每个被试执行每个动作两次。总共199个动作序列,给出了20个关节的三维位置。这被认为是一个具有挑战性的数据因为观点的变化和阶级内部的高度变化。
NTU RGB+D数据集:该数据集被3个捕获微软Kinect v2摄像头。它总共包含60个行动类,分为三个主要组:40个日常行动、9个与健康有关的行动和11个相互行动。每个序列包含了25个骨骼关节的三维位置。由于大量的内部类和视图变化,这是非常具有挑战性的。
northwest - ucla数据集:此数据集由3台微软Kinect v1相机同时捕获。它包含1494个序列,涵盖10个动作类别。每一个动作由十名受试者执行一到六次。这个数据集包含了来自不同视点的数据。
UWA3DII数据集:该数据集由4台微软Kinect v1相机捕获。它包含30个人类动作,由10个受试者执行4次。每个动作都是从前视图、左右视图和顶视图观察。数据集是具有挑战性的,因为不同的观点,自遮挡和高度相似的行动。

表1:所提模型的参数设置。TS-LSTMl是该模型中第l个TS-LSTM,其参数为(Dl),王T Sl)。LN表示TS-LSTM各部分拼接的隐藏单元数,LN的下标S、M、L、P分别表示短期、中期、长期和姿态部分。NT是所有样本数据的最大骨架帧长度。
表1显示了我们提出的主要模型的参数设置。我们使用所有的骨骼关节作为每个数据集的输入。实验使用MSR Action3D数据集(MSR)和UTKinect-Action数据集(UTKi)上的所有序列。我们从NTU RGB+D数据集(NTU)、NorthwesternUCLA数据集(UCLA)和UWA3DII数据集(UWA)中排除无效序列,因为它们的序列长度比只有10帧要短。在不同的体系结构中, LSTMs根据输入特征类型执行和池化或平均池化,每个LN层保留隐藏单元的概率为0.4。
结果与比较:
MSR Action3D数据集:我们遵循[9]提供的标准协议。在这个标准协议中,数据集被分为三个动作集,例如动作Set1 (AS1),
动作Set2 (AS2)和动作Set3 (AS3)。我们使用受试者1、3、5、7、9的样本进行训练,使用受试者2、4、6、8、10的样本进行测试。如表2所示,本文提出的集成TS-LSTM v1和v2的平均精度显著提高(96.63%)和(97.22)%)分别与前面的方法进行了比较:

如表2所示,HCC和SMF加入LSTM的平均精度提高了6.1%,这表明我们的特征表示在这个数据集中是非常有用的。合TSLSTM模型比之前的最佳[10]方法高出约2%。此外,我们的网络模型在几乎每一个动作集都优于其他方法,包括AS2和AS3,这意味着提出的模型比其他方法对各种动作更健壮。UTKinect-Action dataset:我们遵循[25]协议,其中一半受试者用于培训,其余用于测试。前5个科目用于培训,后5个科目用于测试。如表3所示,我们的模型得到了更高的结果(95.96%)和(96.97%),与之前的最佳模型[23](95.96%)比较。

不同于MSR Action3D数据集,应该注意的是,增加肝细胞癌和SMF LSTM使精度平均提高了12.12%和21.21%,分别,这表明我们的特性表现在这个数据集比这更有效的MSR Action3D数据集。集成TS-LSTM v1和v2都比之前的最佳方法高出约1%.
NTU RGB+D数据集:我们遵循两个标准的评估协议[14]。一种是交叉科目(CS)评估,其中一半的科目用于培训,剩下的用于测试。第二种是跨视图(CV)评估,其中两种视点用于培训,一种视点用于测试。由于HCC最初的基础可能会因观点的不同而不同,我们使用每个序列的初始骨架的主干作为HCC的基础,而不是垂直载体。如表4所示,与之前的冰毒相比,与之前的方法相比,我们的模型取得了有竞争力的结果,这表明它可以更好地建模各种时间动态,即使对于这个具有挑战性的数据集。

图5:根据MSR Action3D数据集上的动作集,TS-LSTM v1集成的混淆矩阵。每个混淆矩阵的行和列分别表示ground truth和prediction。(一)AS1。(b) AS2。(c) AS3。

我们遵循评估协议[19]。我们使用来自前两个摄像机的样本作为训练数据,第三个摄像机的样本作为测试数据。如表5所示,所提出的集成TS-LSTM v1和v2取得了竞赛成绩(85.99)%)和(89.22%)与之前的最佳模型进行比较在northwest - ucla数据集中的[11](86.09%)。