目录
1. 数据说明及处理目标
2. groupby,按某列有序collect_list
3. explode 展开udf返回的array
4. 将单列按照分隔符展开为多列
1. 数据说明及处理目标
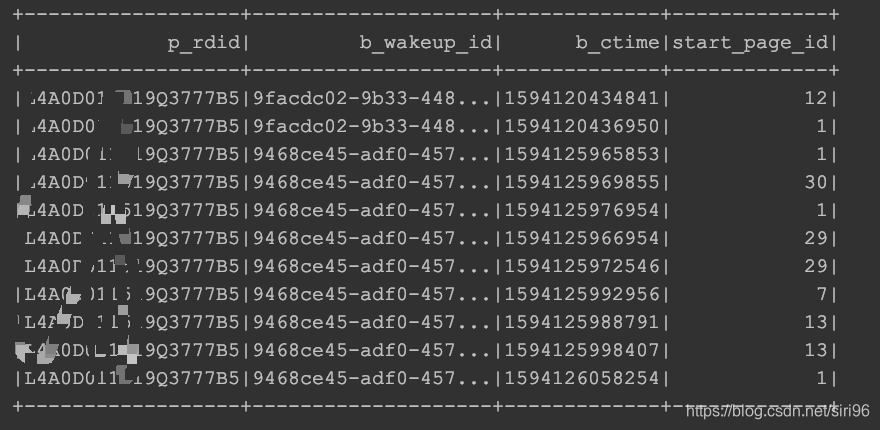
DataFrame格式及内容如下图所示,每个rdid下有多个wakeup_id,每条wakeup_id对应多条ctime及page_id。
处理目标:获取每个wakeup_id下的page_id变化序列,假设某wakeup_id下的page_id有序列表为[1,3,4,6,6,7,8,8],那么所需变化序列为[1-3, 3-4, 4-6, 6-7, 7-8],忽略连续相同的page_id
分解目标:
第一步,获取每个wakeup_id下按照时间顺序排列的page_id列表
第二步,根据1中的时序page_id列表,得到page_id变化对应关系组
第三步,将2中得到的关系组拆开成为start_page和end_page两列,目标达成
2. groupby,按某列有序collect_list
正常groupby collect_list不能保证list的顺序,而本目标需要按照ctime排序的page_id list,因此,可定义一个窗口,然后对指定列处理,代码如下。之后再选取每组中start_page_sorted长度最大的即为所需有序list。
import org.apache.spark.sql.expressions.{Window}
var w = Window.partitionBy("b_wakeup_id").orderBy("b_ctime")
var sorted_df = df.withColumn("start_page_sorted", collect_list("start_page_id").over(w))
此时生成的中间dataframe如下图所示:

选取每组中start_page_sorted长度最大的行,代码如下:
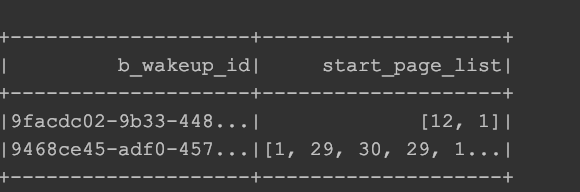
sorted_df = sorted_df.groupBy("p_rdid","b_wakeup_id").agg(max("start_page_sorted").as("start_page_list"))
所得有序列表的DataFrame如下图所示。
3. explode 展开udf返回的array
在udf中定义了处理函数,返回的结果是每个wakeup_id下的page_id变化序列。udf函数自定义,此处不展示,dataframe处理代码及效果如下所示。可以看到page变化序列对已经生成。
df = sorted_df.withColumn("result", UDFunctions.getEndPageList(col("start_page_list")))
explode展开result列,生成新列combine_page_id,结果如下图所示
df = df.withColumn("combine_page_id", explode(col("result")))

4. 将单列按照分隔符展开为多列
将3中生成的combine_page_id根据分隔符','拆开成两列,目标达成,代码及结果见下图。
df = df.withColumn("start_page_id", split(col("combine_page_id"), ",")(0))
df = df.withColumn("end_page_id", split(col("combine_page_id"), ",")(1))

以上为一次完整的小型数据处理过程,如有问题可在评论区交流。