1 图像分类案例2
Kaggle上的狗品种识别(ImageNet Dogs)
在本节中,我们将解决Kaggle竞赛中的犬种识别挑战,比赛的网址是https://www.kaggle.com/c/dog-breed-identification 在这项比赛中,我们尝试确定120种不同的狗。该比赛中使用的数据集实际上是著名的ImageNet数据集的子集。
# 在本节notebook中,使用后续设置的参数在完整训练集上训练模型,大致需要40-50分钟
# 请大家合理安排GPU时长,尽量只在训练时切换到GPU资源
# 也可以在Kaggle上访问本节notebook:
# https://www.kaggle.com/boyuai/boyu-d2l-dog-breed-identification-imagenet-dogs
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
import os
import shutil
import time
import pandas as pd
import random
# 设置随机数种子
random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed(0)
整理数据集
我们可以从比赛网址上下载数据集,其目录结构为:
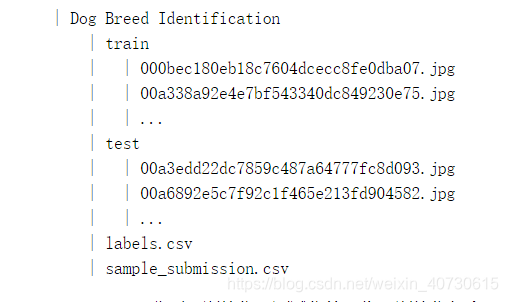
train和test目录下分别是训练集和测试集的图像,训练集包含10,222张图像,测试集包含10,357张图像,图像格式都是JPEG,每张图像的文件名是一个唯一的id。labels.csv包含训练集图像的标签,文件包含10,222行,每行包含两列,第一列是图像id,第二列是狗的类别。狗的类别一共有120种。
- 我们希望对数据进行整理,方便后续的读取,我们的主要目标是:
- 从训练集中划分出验证数据集,用于调整超参数。划分之后,数据集应该包含4个部分:划分后的训练集、划分后的验证集、完整训练集、完整测试集
- 对于4个部分,建立4个文件夹:train, valid, train_valid, test。在上述文件夹中,对每个类别都建立一个文件夹,在其中存放属于该类别的图像。前三个部分的标签已知,所以各有120个子文件夹,而测试集的标签未知,所以仅建立一个名为unknown的子文件夹,存放所有测试数据。
我们希望整理后的数据集目录结构为:

data_dir = '/home/kesci/input/Kaggle_Dog6357/dog-breed-identification' # 数据集目录
label_file, train_dir, test_dir = 'labels.csv', 'train', 'test' # data_dir中的文件夹、文件
new_data_dir = './train_valid_test' # 整理之后的数据存放的目录
valid_ratio = 0.1 # 验证集所占比例
def mkdir_if_not_exist(path):# 若目录path不存在,则创建目录if not os.path.exists(os.path.join(*path)):os.makedirs(os.path.join(*path))def reorg_dog_data(data_dir, label_file, train_dir, test_dir, new_data_dir, valid_ratio):# 读取训练数据标签labels = pd.read_csv(os.path.join(data_dir, label_file))id2label = {Id: label for Id, label in labels.values} # (key: value): (id: label)# 随机打乱训练数据train_files = os.listdir(os.path.join(data_dir, train_dir))random.shuffle(train_files) # 原训练集valid_ds_size = int(len(train_files) * valid_ratio) # 验证集大小for i, file in enumerate(train_files):img_id = file.split('.')[0] # file是形式为id.jpg的字符串img_label = id2label[img_id]if i < valid_ds_size:mkdir_if_not_exist([new_data_dir, 'valid', img_label])shutil.copy(os.path.join(data_dir, train_dir, file),os.path.join(new_data_dir, 'valid', img_label))else:mkdir_if_not_exist([new_data_dir, 'train', img_label])shutil.copy(os.path.join(data_dir, train_dir, file),os.path.join(new_data_dir, 'train', img_label))mkdir_if_not_exist([new_data_dir, 'train_valid', img_label])shutil.copy(os.path.join(data_dir, train_dir, file),os.path.join(new_data_dir, 'train_valid', img_label))# 测试集mkdir_if_not_exist([new_data_dir, 'test', 'unknown'])for test_file in os.listdir(os.path.join(data_dir, test_dir)):shutil.copy(os.path.join(data_dir, test_dir, test_file),os.path.join(new_data_dir, 'test', 'unknown'))
reorg_dog_data(data_dir, label_file, train_dir, test_dir, new_data_dir, valid_ratio)
图像增强
transform_train = transforms.Compose([# 随机对图像裁剪出面积为原图像面积0.08~1倍、且高和宽之比在3/4~4/3的图像,再放缩为高和宽均为224像素的新图像transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3.0/4.0, 4.0/3.0)),# 以0.5的概率随机水平翻转transforms.RandomHorizontalFlip(),# 随机更改亮度、对比度和饱和度transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),transforms.ToTensor(),# 对各个通道做标准化,(0.485, 0.456, 0.406)和(0.229, 0.224, 0.225)是在ImageNet上计算得的各通道均值与方差transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # ImageNet上的均值和方差
])# 在测试集上的图像增强只做确定性的操作
transform_test = transforms.Compose([transforms.Resize(256),# 将图像中央的高和宽均为224的正方形区域裁剪出来transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
读取数据
# new_data_dir目录下有train, valid, train_valid, test四个目录
# 这四个目录中,每个子目录表示一种类别,目录中是属于该类别的所有图像
train_ds = torchvision.datasets.ImageFolder(root=os.path.join(new_data_dir, 'train'),transform=transform_train)
valid_ds = torchvision.datasets.ImageFolder(root=os.path.join(new_data_dir, 'valid'),transform=transform_test)
train_valid_ds = torchvision.datasets.ImageFolder(root=os.path.join(new_data_dir, 'train_valid'),transform=transform_train)
test_ds = torchvision.datasets.ImageFolder(root=os.path.join(new_data_dir, 'test'),transform=transform_test)
batch_size = 128
train_iter = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size=batch_size, shuffle=True)
train_valid_iter = torch.utils.data.DataLoader(train_valid_ds, batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size=batch_size, shuffle=False) # shuffle=False
定义训练函数
def evaluate_loss_acc(data_iter, net, device):# 计算data_iter上的平均损失与准确率loss = nn.CrossEntropyLoss()is_training = net.training # Bool net是否处于train模式net.eval()l_sum, acc_sum, n = 0, 0, 0with torch.no_grad():for X, y in data_iter:X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l_sum += l.item() * y.shape[0]acc_sum += (y_hat.argmax(dim=1) == y).sum().item()n += y.shape[0]net.train(is_training) # 恢复net的train/eval状态return l_sum / n, acc_sum / n
def train(net, train_iter, valid_iter, num_epochs, lr, wd, device, lr_period,lr_decay):loss = nn.CrossEntropyLoss()optimizer = optim.SGD(net.fc.parameters(), lr=lr, momentum=0.9, weight_decay=wd)net = net.to(device)for epoch in range(num_epochs):train_l_sum, n, start = 0.0, 0, time.time()if epoch > 0 and epoch % lr_period == 0: # 每lr_period个epoch,学习率衰减一次lr = lr * lr_decayfor param_group in optimizer.param_groups:param_group['lr'] = lrfor X, y in train_iter:X, y = X.to(device), y.to(device)optimizer.zero_grad()y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()train_l_sum += l.item() * y.shape[0]n += y.shape[0]time_s = "time %.2f sec" % (time.time() - start)if valid_iter is not None:valid_loss, valid_acc = evaluate_loss_acc(valid_iter, net, device)epoch_s = ("epoch %d, train loss %f, valid loss %f, valid acc %f, "% (epoch + 1, train_l_sum / n, valid_loss, valid_acc))else:epoch_s = ("epoch %d, train loss %f, "% (epoch + 1, train_l_sum / n))print(epoch_s + time_s + ', lr ' + str(lr))
调参
num_epochs, lr_period, lr_decay = 20, 10, 0.1
lr, wd = 0.03, 1e-4
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = get_net(device)
train(net, train_iter, valid_iter, num_epochs, lr, wd, device, lr_period, lr_decay)
在完整数据集上训练模型
# 使用上面的参数设置,在完整数据集上训练模型大致需要40-50分钟的时间
net = get_net(device)
train(net, train_valid_iter, None, num_epochs, lr, wd, device, lr_period, lr_decay)
对测试集分类并提交结果
用训练好的模型对测试数据进行预测。比赛要求对测试集中的每张图片,都要预测其属于各个类别的概率。
preds = []
for X, _ in test_iter:X = X.to(device)output = net(X)output = torch.softmax(output, dim=1)preds += output.tolist()
ids = sorted(os.listdir(os.path.join(new_data_dir, 'test/unknown')))
with open('submission.csv', 'w') as f:f.write('id,' + ','.join(train_valid_ds.classes) + '\n')for i, output in zip(ids, preds):f.write(i.split('.')[0] + ',' + ','.join([str(num) for num in output]) + '\n')
2 GAN
Generative Adversarial Networks
GAN是什么?
? GAN启发自博弈论中的二人零和博弈(two-player game),GAN 模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。
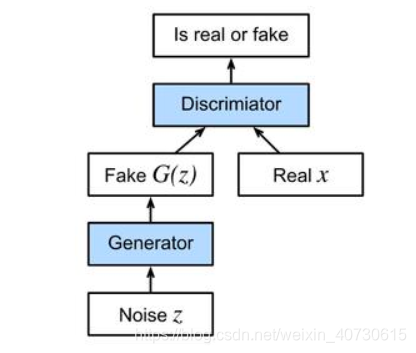
Decriminator(判别器)损失函数
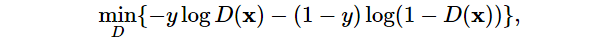
Generator(生成器)损失函数
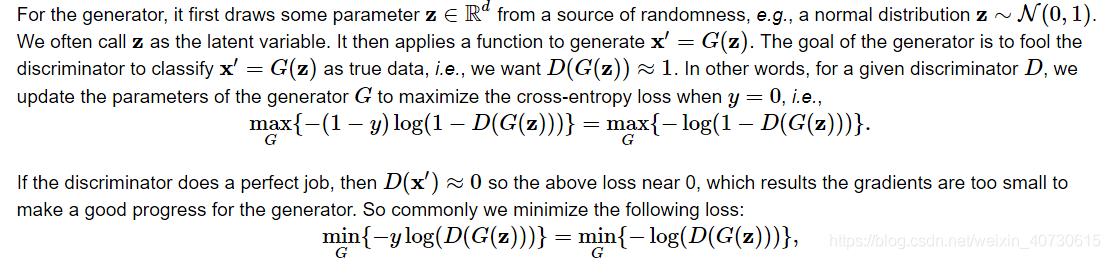
总损失函数
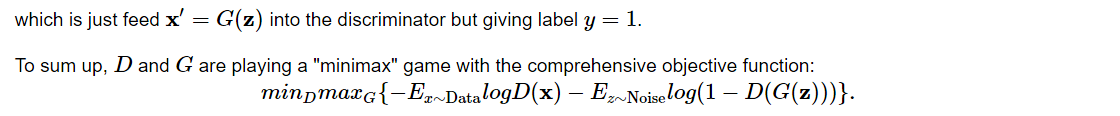
我们将说明如果我们使用GANs来构建世界上最低效的高斯分布参数估计器会发生什么。让我们开始吧。
%matplotlib inline
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch import nn
import numpy as np
from torch.autograd import Variable
import torch
生成一些“真实的”数据
因为这将是世界上最蹩脚的例子,我们只是从高斯分布中生成数据。
X=np.random.normal(size=(1000,2))
A=np.array([[1,2],[-0.1,0.5]])
b=np.array([1,2])
data=X.dot(A)+b
Let’s see what we got. This should be a Gaussian shifted in some rather arbitrary way with mean b and covariance matrix .
plt.figure(figsize=(3.5,2.5))
plt.scatter(X[:100,0],X[:100,1],color='red')
plt.show()
plt.figure(figsize=(3.5,2.5))
plt.scatter(data[:100,0],data[:100,1],color='blue')
plt.show()
print("The covariance matrix is\n%s" % np.dot(A.T, A))
batch_size=8
data_iter=DataLoader(data,batch_size=batch_size)
Generator(生成器)
Our generator network will be the simplest network possible - a single layer linear model. This is since we will be driving that linear network with a Gaussian data generator. Hence, it literally only needs to learn the parameters to fake things perfectly.
class net_G(nn.Module):def __init__(self):super(net_G,self).__init__()self.model=nn.Sequential(nn.Linear(2,2),)self._initialize_weights()def forward(self,x):x=self.model(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m,nn.Linear):m.weight.data.normal_(0,0.02)m.bias.data.zero_()
Discriminator(判别器)
For the discriminator we will be a bit more discriminating: we will use an MLP with 3 layers to make things a bit more interesting.
class net_D(nn.Module):def __init__(self):super(net_D,self).__init__()self.model=nn.Sequential(nn.Linear(2,5),nn.Tanh(),nn.Linear(5,3),nn.Tanh(),nn.Linear(3,1),nn.Sigmoid())self._initialize_weights()def forward(self,x):x=self.model(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m,nn.Linear):m.weight.data.normal_(0,0.02)m.bias.data.zero_()
Training
First we define a function to update the discriminator.
# Saved in the d2l package for later use
def update_D(X,Z,net_D,net_G,loss,trainer_D):batch_size=X.shape[0]Tensor=torch.FloatTensorones=Variable(Tensor(np.ones(batch_size))).view(batch_size,1)zeros = Variable(Tensor(np.zeros(batch_size))).view(batch_size,1)real_Y=net_D(X.float())fake_X=net_G(Z)fake_Y=net_D(fake_X)loss_D=(loss(real_Y,ones)+loss(fake_Y,zeros))/2loss_D.backward()trainer_D.step()return float(loss_D.sum())
The generator is updated similarly. Here we reuse the cross-entropy loss but change the label of the fake data from 0 to 1.
# Saved in the d2l package for later use
def update_G(Z,net_D,net_G,loss,trainer_G):batch_size=Z.shape[0]Tensor=torch.FloatTensorones=Variable(Tensor(np.ones((batch_size,)))).view(batch_size,1)fake_X=net_G(Z)fake_Y=net_D(fake_X)loss_G=loss(fake_Y,ones)loss_G.backward()trainer_G.step()return float(loss_G.sum())
Both the discriminator and the generator performs a binary logistic regression with the cross-entropy loss. We use Adam to smooth the training process. In each iteration, we first update the discriminator and then the generator. We visualize both losses and generated examples.
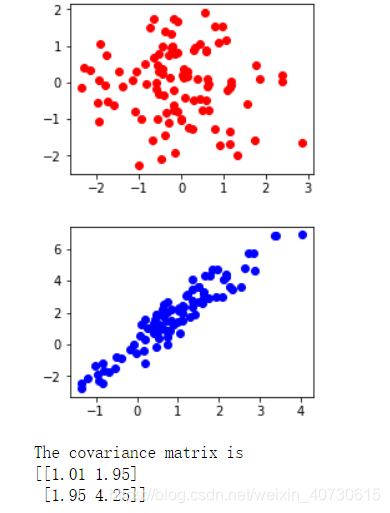
def train(net_D,net_G,data_iter,num_epochs,lr_D,lr_G,latent_dim,data):loss=nn.BCELoss()Tensor=torch.FloatTensortrainer_D=torch.optim.Adam(net_D.parameters(),lr=lr_D)trainer_G=torch.optim.Adam(net_G.parameters(),lr=lr_G)plt.figure(figsize=(7,4))d_loss_point=[]g_loss_point=[]d_loss=0g_loss=0for epoch in range(1,num_epochs+1):d_loss_sum=0g_loss_sum=0batch=0for X in data_iter:batch+=1X=Variable(X)batch_size=X.shape[0]Z=Variable(Tensor(np.random.normal(0,1,(batch_size,latent_dim))))trainer_D.zero_grad()d_loss = update_D(X, Z, net_D, net_G, loss, trainer_D)d_loss_sum+=d_losstrainer_G.zero_grad()g_loss = update_G(Z, net_D, net_G, loss, trainer_G)g_loss_sum+=g_lossd_loss_point.append(d_loss_sum/batch)g_loss_point.append(g_loss_sum/batch)plt.ylabel('Loss', fontdict={'size': 14})plt.xlabel('epoch', fontdict={'size': 14})plt.xticks(range(0,num_epochs+1,3))plt.plot(range(1,num_epochs+1),d_loss_point,color='orange',label='discriminator')plt.plot(range(1,num_epochs+1),g_loss_point,color='blue',label='generator')plt.legend()plt.show()print(d_loss,g_loss)Z =Variable(Tensor( np.random.normal(0, 1, size=(100, latent_dim))))fake_X=net_G(Z).detach().numpy()plt.figure(figsize=(3.5,2.5))plt.scatter(data[:,0],data[:,1],color='blue',label='real')plt.scatter(fake_X[:,0],fake_X[:,1],color='orange',label='generated')plt.legend()plt.show()
Now we specify the hyper-parameters to fit the Gaussian distribution.
if __name__ == '__main__':lr_D,lr_G,latent_dim,num_epochs=0.05,0.005,2,20generator=net_G()discriminator=net_D()train(discriminator,generator,data_iter,num_epochs,lr_D,lr_G,latent_dim,data)
- Summary
- Generative adversarial networks (GANs) composes of two deep networks, the generator and the discriminator.
- The generator generates the image as much closer to the true image as possible to fool the discriminator, via maximizing the cross-entropy loss, i.e., maxlog(D(x′))
- The discriminator tries to distinguish the generated images from the true images, via minimizing the cross-entropy loss, i.e., min?ylogD(x)?(1?y)log(1?D(x))
3 DCGAN
DCGAN(
Deep Convolutional Generative Adversarial Networks)是继GAN之后比较好的改进,其主要的改进主要是在网络结构上,到目前为止,DCGAN的网络结构还是被广泛的使用,DCGAN极大的提升了GAN训练的稳定性以及生成结果质量。
论文的主要贡献是:
◆ 为GAN的训练提供了一个很好的网络拓扑结构。
◆ 表明生成的特征具有向量的计算特性。
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch import nn
import numpy as np
from torch.autograd import Variable
import torch
from torchvision.datasets import ImageFolder
from torchvision.transforms import transforms
import zipfile
cuda = True if torch.cuda.is_available() else False
print(cuda)
The Pokemon Dataset

data_dir='/home/kesci/input/pokemon8600/'
batch_size=256
transform=transforms.Compose([transforms.Resize((64,64)),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
pokemon=ImageFolder(data_dir+'pokemon',transform)
data_iter=DataLoader(pokemon,batch_size=batch_size,shuffle=True)
打印并观察第20张图片
fig=plt.figure(figsize=(4,4))
imgs=data_iter.dataset.imgs
for i in range(20):img = plt.imread(imgs[i*150][0])plt.subplot(4,5,i+1)plt.imshow(img)plt.axis('off')
plt.show()

The Generator

class G_block(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=4,strides=2, padding=1):super(G_block,self).__init__()self.conv2d_trans=nn.ConvTranspose2d(in_channels, out_channels, kernel_size=kernel_size,stride=strides, padding=padding, bias=False)self.batch_norm=nn.BatchNorm2d(out_channels,0.8)self.activation=nn.ReLU()def forward(self,x):return self.activation(self.batch_norm(self.conv2d_trans(x)))
转置卷积网络层的尺寸计算
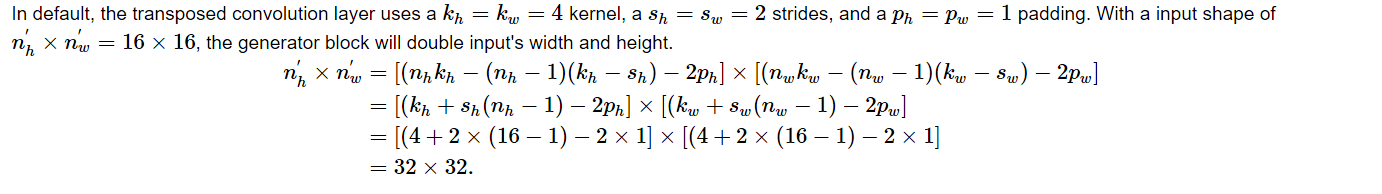
Discriminator
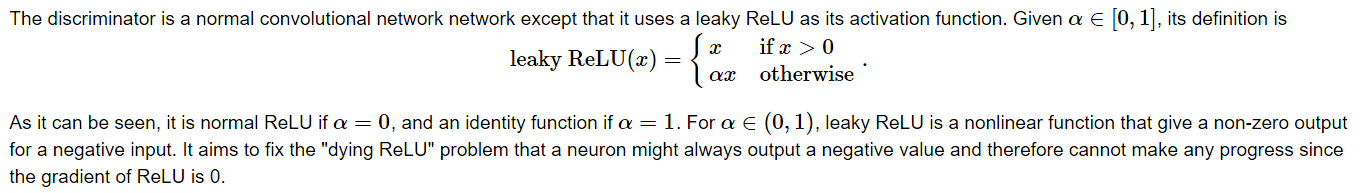
alphas = [0, 0.2, 0.4, .6]
x = np.arange(-2, 1, 0.1)
Y = [nn.LeakyReLU(alpha)(Tensor(x)).cpu().numpy()for alpha in alphas]
plt.figure(figsize=(4,4))
for y in Y:plt.plot(x,y)
plt.show()
Training

def update_D(X,Z,net_D,net_G,loss,trainer_D):batch_size=X.shape[0]Tensor=torch.cuda.FloatTensorones=Variable(Tensor(np.ones(batch_size,)),requires_grad=False).view(batch_size,1)zeros = Variable(Tensor(np.zeros(batch_size,)),requires_grad=False).view(batch_size,1)real_Y=net_D(X).view(batch_size,-1)fake_X=net_G(Z)fake_Y=net_D(fake_X).view(batch_size,-1)loss_D=(loss(real_Y,ones)+loss(fake_Y,zeros))/2loss_D.backward()trainer_D.step()return float(loss_D.sum())def update_G(Z,net_D,net_G,loss,trainer_G):batch_size=Z.shape[0]Tensor=torch.cuda.FloatTensorones=Variable(Tensor(np.ones((batch_size,))),requires_grad=False).view(batch_size,1)fake_X=net_G(Z)fake_Y=net_D(fake_X).view(batch_size,-1)loss_G=loss(fake_Y,ones)loss_G.backward()trainer_G.step()return float(loss_G.sum())def train(net_D,net_G,data_iter,num_epochs,lr,latent_dim):loss=nn.BCELoss()Tensor=torch.cuda.FloatTensortrainer_D=torch.optim.Adam(net_D.parameters(),lr=lr,betas=(0.5,0.999))trainer_G=torch.optim.Adam(net_G.parameters(),lr=lr,betas=(0.5,0.999))plt.figure(figsize=(7,4))d_loss_point=[]g_loss_point=[]d_loss=0g_loss=0for epoch in range(1,num_epochs+1):d_loss_sum=0g_loss_sum=0batch=0for X in data_iter:X=X[:][0]batch+=1X=Variable(X.type(Tensor))batch_size=X.shape[0]Z=Variable(Tensor(np.random.normal(0,1,(batch_size,latent_dim,1,1))))trainer_D.zero_grad()d_loss = update_D(X, Z, net_D, net_G, loss, trainer_D)d_loss_sum+=d_losstrainer_G.zero_grad()g_loss = update_G(Z, net_D, net_G, loss, trainer_G)g_loss_sum+=g_lossd_loss_point.append(d_loss_sum/batch)g_loss_point.append(g_loss_sum/batch)print("[Epoch %d/%d] [D loss: %f] [G loss: %f]"% (epoch, num_epochs, d_loss_sum/batch_size, g_loss_sum/batch_size))plt.ylabel('Loss', fontdict={ 'size': 14})plt.xlabel('epoch', fontdict={ 'size': 14})plt.xticks(range(0,num_epochs+1,3))plt.plot(range(1,num_epochs+1),d_loss_point,color='orange',label='discriminator')plt.plot(range(1,num_epochs+1),g_loss_point,color='blue',label='generator')plt.legend()plt.show()print(d_loss,g_loss)Z = Variable(Tensor(np.random.normal(0, 1, size=(21, latent_dim, 1, 1))),requires_grad=False)fake_x = generator(Z)fake_x=fake_x.cpu().detach().numpy()plt.figure(figsize=(14,6))for i in range(21):im=np.transpose(fake_x[i])plt.subplot(3,7,i+1)plt.imshow(im)plt.show()
开始训练
if __name__ == '__main__':lr,latent_dim,num_epochs=0.005,100,50train(discriminator,generator,data_iter,num_epochs,lr,latent_dim)
- Summary
- DCGAN architecture has four convolutional layers for the Discriminator and four “fractionally-strided” convolutional layers for the Generator.
- The Discriminator is a 4-layer strided convolutions with batch normalization (except its input layer) and leaky ReLU activations.
- Leaky ReLU is a nonlinear function that give a non-zero output for a negative input. It aims to fix the “dying ReLU” problem and helps the gradients flow easier through the architecture.