下面是我对最近看的逆向视觉问答文章的理解
一、文章摘要
我们提出了视觉问题回答(iVQA)的反问题,并探 讨了其是否适合作为视觉语言理解的基准.iVQA任务是生成一个与给定图像和答案对对应的问题。由于答案的信息量低于问题,而且问题具有较少的可学习偏差,因此iVQA模型需要比VQA模型更好地理解图像才能成功。我们将问题生成作为一种多模式动态推理过程,并提出一个 iVQA 模型,该模型可以逐渐调整其关注点以部分生成的问题和答案为指导。为了进行评估,除了现有的语言指标外,我们还提出了一种新的排名指标。此度量标准比较了干扰因素列表中的地面真相问题的排名,从而可以研究不同算法和错误源的缺点。实验结果表明,我们的模型可以生成与给定答案相匹配的各种语法正确且内容相关的问题。
二、文章介绍
在本文中,作者采用了不同的方法,并探讨了逆VQA 任务是否提供了有趣的多模式智能基准。逆 VQA(iVQA)任务是输入一对图像并回答,然后询问(输出)在给定图像的上下文中给定答案所适用的合适问题。面临的挑战有以下几点:
(i)对于iVQA模型来说,与VQA通过答案偏差获得高分相比,它利用问题偏差的余地可能更小(不存在太多的问题偏见,利用这种偏见比明确的答案更难)
(ii)与 VQA 中的问题相比,答案本身在 iVQA 中提供了非常稀疏的提示。因此,在i VQA中单独从答案中推断问题的操作可能比在VQA中单独从问题中推断问题的答案要少。因此,iVQA 任务在很大程度上取决于理解图像内容。
(三)从知识表示和推理的角度来看,iVQA可以提供机会来测试更复杂的推理策略,如反事实推理[4]
本篇论文的贡献如下:
(1)引入新的 iVQA 问题,作为高级多模态视觉语言理解的替代挑战。(2)我们提出了一种基于多模式动态注意力的 iVQA 模型。
(3)我们提出了一种基于问题排名的 iVQA 评估方法,这有助于诊断不同模型的优缺点。
(4)作为 VQA 的双重问题,我们证明 iVQA 有潜力帮助提高 VQA 性能。
三、实验模型和方法
提议的IVQA模型的总体框架

3.1问题表述Problem formulation
逆视觉问题回答(iVQ A)的问题是在特定图像I的上下文中推断一个给定答案a成立的问题q。形式上:
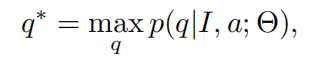
其中 q 是带有单词(w1,w2,…,wn)的句子,而Θ是模型参数。
作为序列生成问题,我们可以使用递归神经网络语言模型,通过使可能性最大化来生成句子
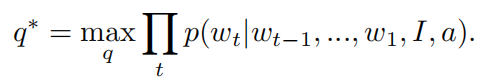
由于任务以图像 I 和答案 a 为条件,因此视觉信息必须与答案适当地集成在一起以产生问题。
3.2模型概述Model overview
模型共包括3部分:
(1) Image Encoder
从给定的image中提取局部和全局信息,使用ResNet-152模型计算的res5c特征用作局部特征 全局信息利用image caption中最常用的1000个语义概念作为image的全局信息
(2)Answer Encoder
使用具有512个单元的LSTM,将最终隐藏状态和单元状态的串联作为答案a的表示
(3)Question decoder
Question decoder部分包括Multi-modal attention
3.3.动态多模态注意Dynamic multi-modal attention
给定答案中包含的稀疏信息,拥有有效的注意力模型来专注于图像的正确区域对于 iVQA 至关重要。我们的 iVQA 问题具有一些独特的特征,因此需要量身定制的关注模块。具体而言,与 VQA 相比,iVQA 需要多个解码步骤,因此关注焦点需要相应地动态更改。同样与图像字幕不同,生成过程具有多模式条件:即图像和答案,这两者都需要以动态方式集成在每个解码步骤中。
它由以下模块组成:
Initial glimpse
初步了解应该提供一个输入图像-答案对的概述线索,为解码过程建立一个良好的起点。我们使用语义概念预测作为一个全局视觉线索,它捕获可能与问题相关的1克信息[23]。编码的答案a被作为文本线索,它决定了目标问题的可能的初始词集。这两个线索被整合为:
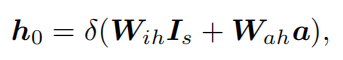

Encoding of partial question :
部分问题编码器将到目前为止生成的部分问题 qt = {w1,w2,…,wt}顺序编码为隐藏表示 ht。具有 512 个单元的 LSTM 网络用于将部分问题编码为隐藏表示 ht:
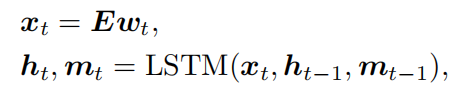

Multi-modal attention network :
注意网络以局部特征I、部分问题编码ht和回答编码a作为输入,并输出由部分问题指定的出席视觉特征ct的联合嵌入。回答上下文ZT。为了获得部分问题答案上下文,将部分问题编码ht和答案编码a融合为:
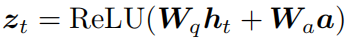
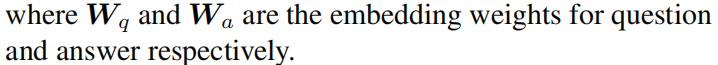
然后通过软注意对视觉特征i和文本上下文zt进行空间匹配:通过多模态低秩双线性池(MLB)融合视觉特征vi、j和上下文向量zt,然后,在所有方程中的融合特征fij1用于注意图计算,如下所示
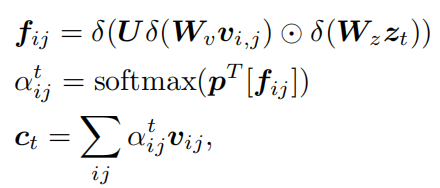
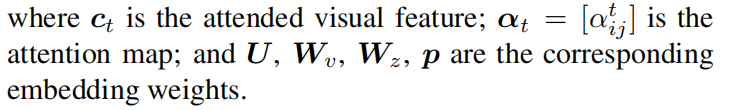
进一步融合:
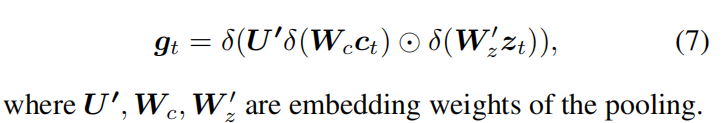
Word predictor
下一个单词预测器是一个Softmax分类器,它在下一个单词上生成一个分布,利用多模态注意网络的输出gt:

四、实验
我们重新调整了 VQA 数据集[2]的用途,以调查 iVQA 任务。VQA 数据集使用来自 MSCOCO [5],包括 82,783 训练,40,504 验证和81,434 测试图像。每个图像收集了三个问题-答案对。
由于无法获得测试集答案,因此我们采用[19,25]中常用的离线数据拆分来进行图像字幕:82783 张图像用于训练,而 5,000 张用于验证和测试。
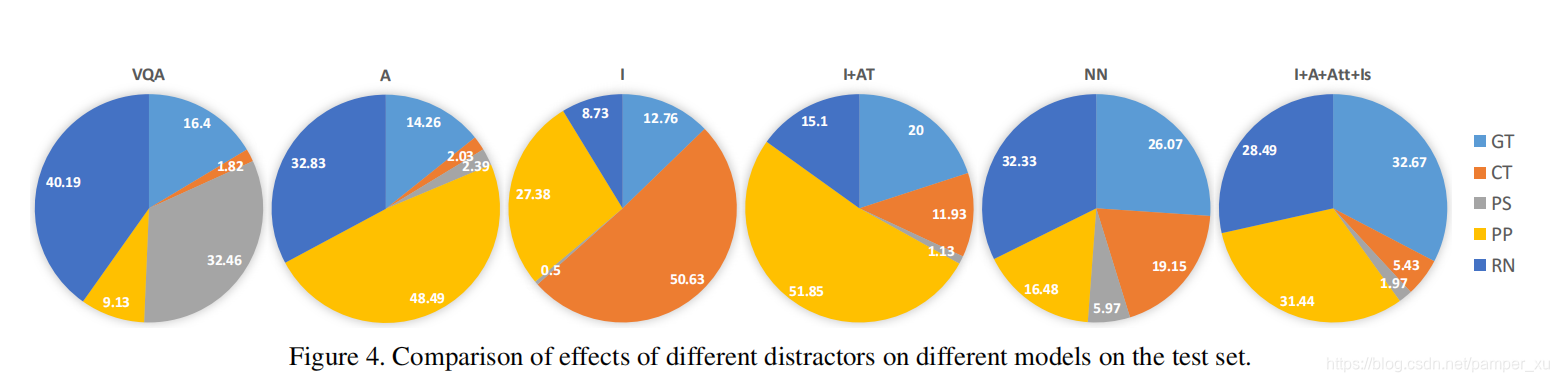
与其他的比较:
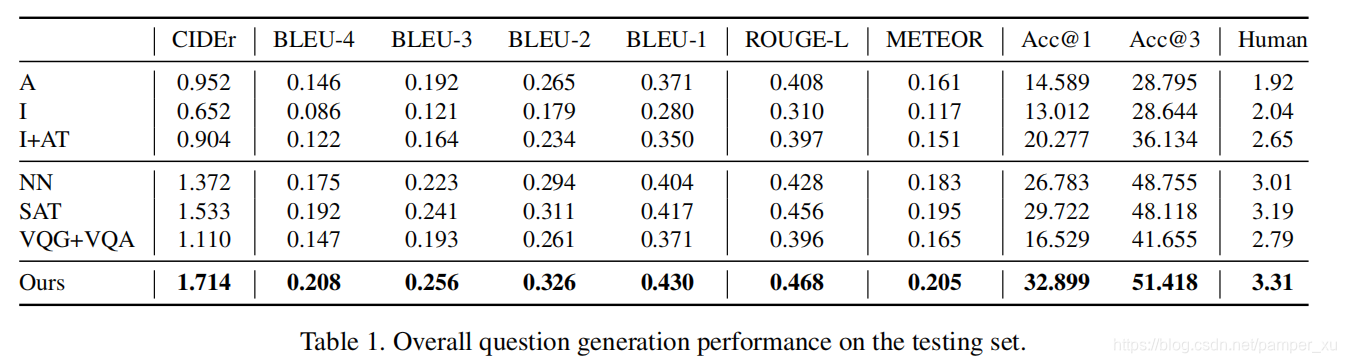
不同干扰因素对测试集上不同模型的影响的比较。