本项目我们遵循以下工作流程。
1项目概况2、数据理解3、头脑风暴4、数据清理5、探索性数据分析6、特色工程7、功能选择8、型号9、选型10、参数微调11。进一步改进
项目概述
目标是根据学生之前的学习经验预测学生是否能够正确回答下一个问题。数据集包含了学生以前的学习经历(观看的讲座和回答的问题)、描述和讲座的信息。这是一个时间序列预测问题。
评估指标:预测概率与观测目标之间ROC曲线下的面积。
数据理解
trian.csv

question.csv

lecture.csv

3
解决问题需要哪些信息?
–问题是什么?
–用户是否看过相关课件?
–用户是否回答了相关问题?回答正确还是错误?
–用户有任何反馈吗?
–用户学习了多长时间?
–其他用户呢?关系密切的用户可能会执行类似的操作。
–问题的难度。
总之,我们需要每个用户的学习体验,用户之间的关系,讲座和问题之间的联系。问题之间的关系。讲座之间的关系。
?数据集提供了哪些信息?
–用户:学习多久了?看了什么讲座?回答什么问题,回答这些问题需要多长时间?是否阅读了正确答案的解释?
–问题:id、标签、类别、答案、组。
–讲座:id、类型、类别、标签。
?我们是否需要外部数据集?
讲课和提问的层次结构可能有用。
?如何处理数据集?
我们需要开发用户、问题和讲座之间的相互联系以及讲座和问题的层次结构
哪些模型擅长解决问题?
这是一个时间序列二值分类问题。很多模型都可以。
import numpy as np
import pandas as pd def student_ability(train_data, user_id):student_data = train_data[train_data.user_id.values==user_id]student_data=student_data[student_data.content_id.values==0]total_question = student_data.shape[0]correct_count = student_data[student_data.correct==1].shape[0]ability = correct_count/total_questionreturn ability, correct_count, total_questiondef update_ability(new_data, correct_count, total_question) :if new_data.correct == 1:correct_count +=1total_question +=1ability = correct_count/total_questionreturn abilitydef question_hardness(train_data, ques_id):ques_data = train_data[train_data.context_type==0]ques_data = ques_data[ques_data.content_id==ques_id]correct_count = ques_data[ques_data.correct == 1].shape[0]total = ques_data.shape[0]hardness = correct_count/total return hardnessdef update_hardness(new_data, correct_count, total):if new_data.correct == 1:correct_count += 1total += 1hardness = correct_count/totalreturn hardness
数据清理
我们处理丢失的值。
?用平均难度代替缺失的难度。
?对于新生,能力设置为平均水平。
分类变量由LabelEncoder()处理
解释转换为0/1。
?讲座类型编码为0;1;2。
最后,我们合并训练数据集和问题数据集。经过以上数据处理,我们得到以下特征。所有特征都是数值的。对于建模,“user id”被忽略,因为它不包含信息
特征选择
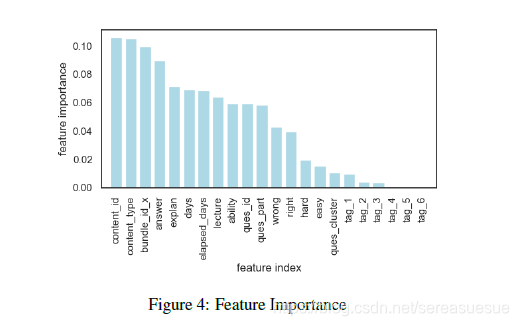
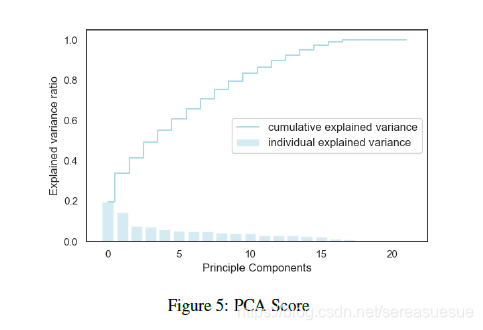
建模
训练数据集按升序用户id和递增时间戳排序。我们通过随机抽样将数据集分解为训练和测试数据集。这样可以确保学生出现在两个子集中。
由于这是一个二元分类问题,可以使用许多模型。我们测试以下模型。
?逻辑回归?SVM?KNN?决策树?随机森林?神经网络?XGBoost
模型选择
这是一个大数据和在线项目。 选择模型时,我们需要考虑计算 模型的复杂性和可伸缩性。 在计算复杂度方面,KNN和SVC不能逐步接受培训。 在可伸缩性方面,KNN不能很好地处理大数据。
模型微调
可以通过对超参数的网格搜索来微调模型。 由于计算量有限 消息来源,我们省略了此步骤。
进一步改进 学生之间的相似性将有助于预测给定其他学生的正确答案 性能。 问题之间的关系也很重要。
参考文章 https://github.com/yang0110/Knowledge-Tracing-Project