环境要求
说明:本文档为wordcount的mapreduce job编写及运行文档。
操作系统:Ubuntu14 x64位
Hadoop:Hadoop 2.7.0
Hadoop官网:http://hadoop.apache.org/releases.html
MapReduce参照官网步骤:
http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Source_Code
本章基于前一篇文章《hadoop2.7.0实践-环境搭建》。
1.安装Eclipse
1)下载eclipse
官网:http://www.eclipse.org/
2)解压eclipse包
$tar -xvf eclipse-jee-mars-R-linux-gtk-x86_64.tar.gz3)启动eclipse
4)写测试程序
public class TestMore {public static void main(String[] args) {System.out.println("hello world!");System.out.println("I'm so glad to see that");}
}2.编写wordcount
1)jar包引入
eclipse的lib中引入的jar包
hadoop包下的share/hadoop下的各个目录都有jar包
hadoop-2.7.0/share/hadoop/common/hadoop-common-2.7.0.jar
hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.0.jar
2)编写worcount程序
对应源码
import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
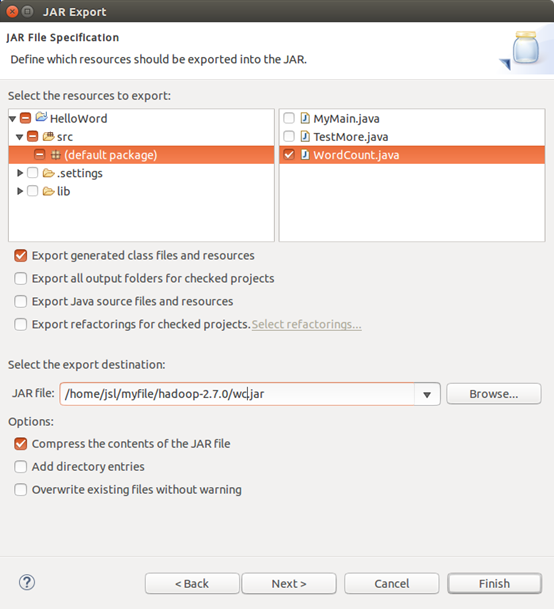
}3)导出jar包
取名wc.jar,直接导出到hadoop目录下。
3.运行wordcount
1)启动dfs服务
参照文件《hadoop2.7.0实践-环境搭建》。
进入hadoop目录,用cd命令。
$sbin/start-dfs.sh对应查看网页:http://localhost:50070/
2)准备文件
hadoop-2.7.0/wctest/input目录中放入待统计文件file01
输入内容:hello world bye world
//创建hdfs目录,操作命令类似本地操作
$ bin/hdfs fs -mkdir /user
$ bin/hdfs fs -mkdir /user/a//复制本地文件到hdfs中
$ bin/hdfs fs -put wctest/input /user/a/input//备注:对应目录删除命令如下
delete dir:bin/hadoop fs -rm -f -r /user/a/input对应文件http://localhost:50070/
3)启动yarn服务
$ sbin/start-yarn.sh4)运行wordcount程序
$ bin/hadoop jar wc.jar WordCount /user/a/input /user/a/output5)查看结果
$ bin/hadoop fs -cat /user/a/output/part-r-00000
bye 1
hello 1
world 2常见错误及说明
1)未启动yarn时运行MapReduce程序
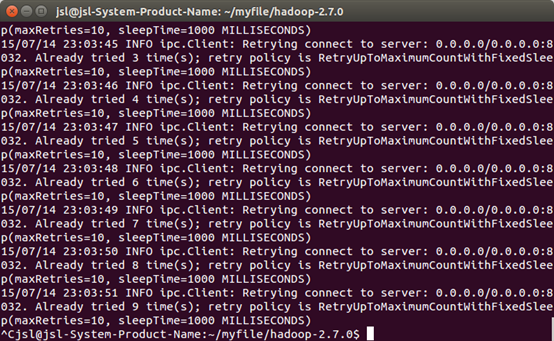
原因:已经配置了yarn,但没有启动引起的
调整:启动一下yarn
$ sbin/start-yarn.sh