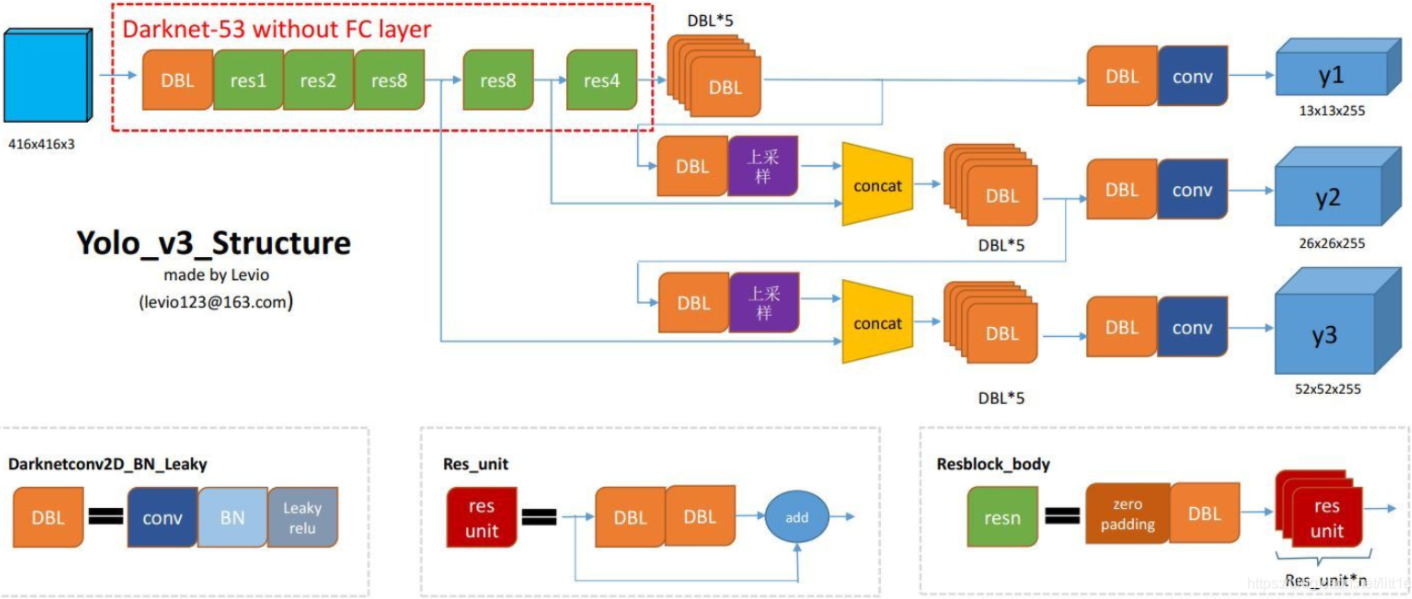
Yolov3
Yolov4
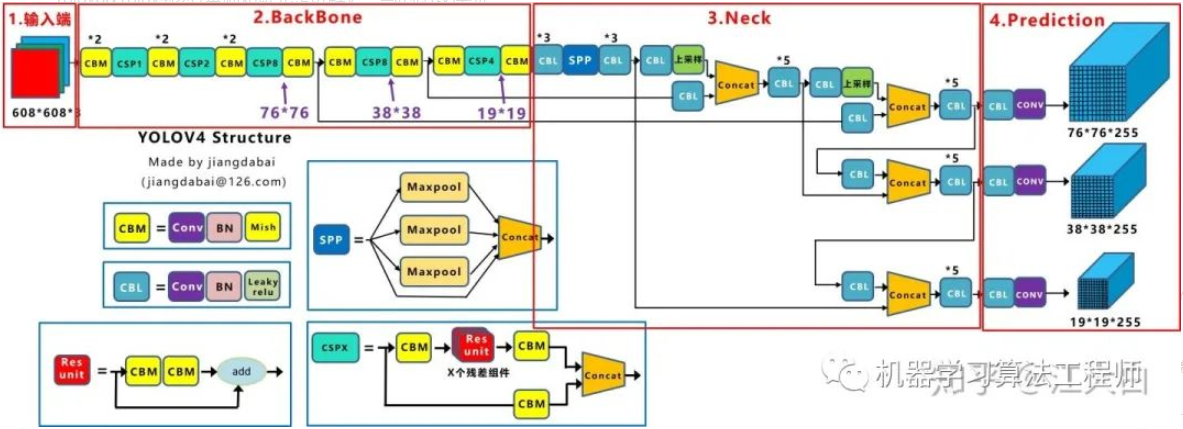
输入端采用 Mosaic、CutMix数据增强、cmBN、SAT自对抗训练 Backbone采用了CSPDarknet53、Mish激活函数、DropBlock正则化等方式 Neck中采用了SPP、FPN+PAN的结构 Prediction则采用CIOU_Loss、DIOU_nms操作
Yolov5
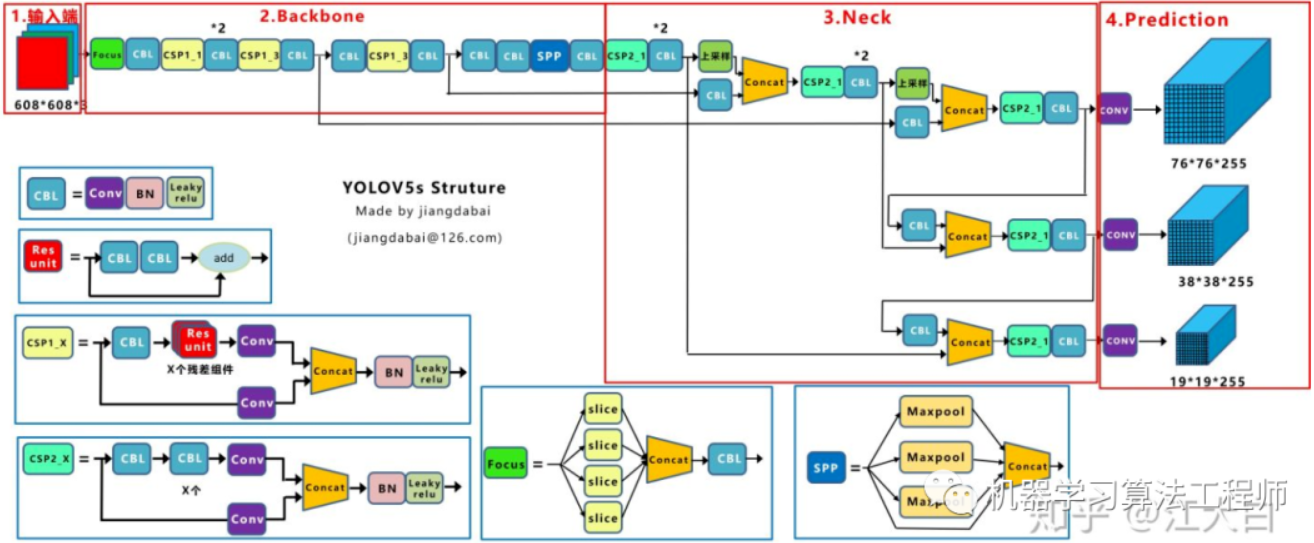
YOLOv5其实就是YOLOv4的工程化的版本。输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放 Backbone:Focus结构,CSP结构 Neck:FPN+PAN结构 Prediction:CIOU_Loss anchor: 采用 k 均值和遗传学习算法对自定义数据集进行分析,获得适合自定义数据集中对象边界框预测的预设锚定框。 开始会先计算Best Possible Recall (BPR) , 再在kmean_anchors函数中进行k 均值和遗传学习算法更新anchors。 数据增强采用了马赛克数据增强,就是从train的数据集中选择四张图片,在一张大图上的一定范围随机选择中心点,在中心点的左上,左下,右上,右下放置一张图片。这样做在一定程度上增加了batch size,四合一图片吗。当然,四张图片上面的label也要做相应的更新;DropBlock机制。防止过拟合很常用的方法就是Dropout,即随机杀死一些神经元,DropBlock则是随机杀死一片区域的神经元。例如,之前是把狗狗图片的眼睛一个像素点删掉了,现在是整个眼睛都删掉了;Label Smoothing。让标签平滑一些,目的是让神经网络不那么自信。例如,softmax的结果:(1,0)->[1,0]*(1-0.1)+0.05=[0.95,0.05];损失函数:边框回归:采用了CIoUObjectness(置信度损失):采用了BCEWithLogitsLoss和CIoU分类损失:采用了交叉熵损失函数BCEWithLogitsLoss三种损失平衡:边框:Objectness:分类=0.05:1:0.5三个检测层的损失平衡是:4.0, 1.0, 0.4对应8,16,32的输出层