该篇主要是讨论为什么要做word embedding:
gitbook阅读:Word Embedding介绍
至于word embedding的详细训练方法在下一节描述。
目录
- 单词表达
-
- One hot representation
- Distributed representation
- Word embedding
-
- 目的
-
- 数据量角度
- 神经网络分析
- 训练简述
单词表达
先前在卷积神经网络的一节中,提到过图片是如何在计算机中被表达的。 同样的,单词也需要用计算机可以理解的方式表达后,才可以进行接下来的操作。
One hot representation
程序中编码单词的一个方法是one hot encoding。
实例:有1000个词汇量。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,...],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列所示。
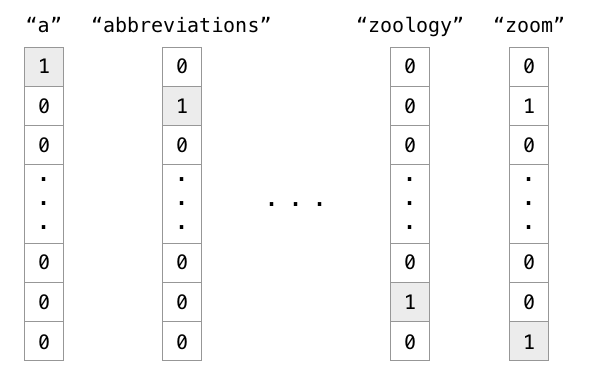
也就是说,
在one hot representation编码的每个单词都是一个维度,彼此independent。
Distributed representation
然而每个单词彼此无关这个特点明显不符合我们的现实情况。我们知道大量的单词都是有关。
语义:girl和woman虽然用在不同年龄上,但指的都是女性。
复数:word和words仅仅是复数和单数的差别。
时态:buy和bought表达的都是“买”,但发生的时间不同。
所以用one hot representation的编码方式,上面的特性都没有被考虑到。
我们更希望用诸如“语义”,“复数”,“时态”等维度去描述一个单词。每一个维度不再是0或1,而是连续的实数,表示不同的程度。
目的
但是说到底,为什么我们想要用Distributed representation的方式去表达一个单词呢?
数据量角度
这需要再次记住我们的目的:
机器学习:从大量的个样本中,寻找可以较好预测未见过
所对应
的函数
。
实例:在我们日常生活的学习中,大量的 就是历年真题,
是题目,而
是对应的正确答案。高考时将会遇到的
往往是我们没见过的题目,希望可以通过做题训练出来的解题方法
来求解出正确的
。
如果可以见到所有的情况,那么只需要记住所有的 所对应的
就可以完美预测。但正如高考无法见到所有类型的题一样,我们无法见到所有的情况。这意味着,
机器学习需要从 有限的例子中寻找到合理的。
高考有两个方向提高分数:
- 方向一:训练更多的数据:题海战术。
- 方向二:加入先验知识:尽可能排除不必要的可能性。
问题的关键在于训练所需要的数据量上。
同理,如果我们用One hot representation去学习,那么每一个单词我们都需要实例数据去训练,即便我们知道"Cat"和"Kitty"很多情况下可以被理解成一个意思。
为什么相同的东西却需要分别用不同的数据进行学习?
神经网络分析
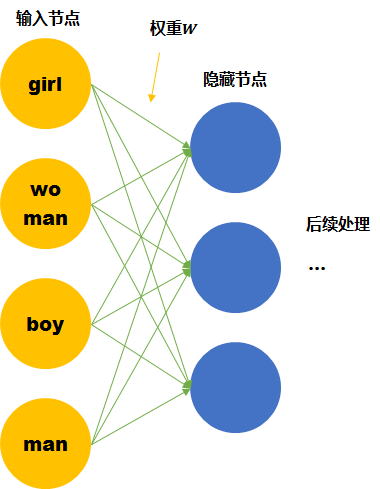
假设我们的词汇只有4个,girl, woman, boy, man,下面就思考用两种不同的表达方式会有什么区别。
One hot representation
尽管我们知道他们彼此的关系,但是计算机并不知道。在神经网络的输入层中,每个单词都会被看作一个节点。 而我们知道训练神经网络就是要学习每个连接线的权重。如果只看第一层的权重,下面的情况需要确定4*3个连接线的关系,因为每个维度都彼此独立,girl的数据不会对其他单词的训练产生任何帮助,训练所需要的数据量,基本就固定在那里了。
Distributed representation
我们这里手动的寻找这四个单词之间的关系。可以用两个节点去表示四个单词。每个节点取不同值时的意义如下表。 那么girl就可以被编码成向量[0,1],man可以被编码成[1,1](第一个维度是gender,第二个维度是age)。

那么这时再来看神经网络需要学习的连接线的权重就缩小到了2*3。同时,当送入girl为输入的训练数据时,因为它是由两个节点编码的。那么与girl共享相同连接的其他输入例子也可以被训练到(如可以帮助到与其共享female的woman,和child的boy的训练)。
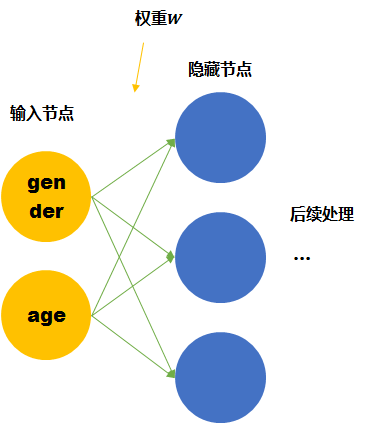
Word embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。
Word embedding
而上面的四个单词可以被拆成2个节点的是由我们人工提供的先验知识,所以才能够降低训练所需要的数据量。 但是我们没有办法一直人工提供,机器学习的宗旨就是让机器代替人力去发现pattern。
Word embedding就是要从数据中自动学习到Distributed representation。
训练方法
问题来了,我们该如何自动寻找到类似上面的关系,将One hot representation转变成Distributed representation。 我们事先并不明确目标是什么,所以这是一个无监督学习任务。
无监督学习中常用思想是:当得到数据后,我们又不知道目标(输出)时,
- 方向一:从各个输入 {
}之间的关系找目标。 如聚类。
- 方向二:并接上以目标输出
作为新输入的另一个任务
,同时我们知道的对应
值。用数据
训练得到
,也就是
,中间的表达
则是我们真正想要的目标。如生成对抗网络。
Word embedding更偏向于方向二。 同样是学习一个 ,但训练后并不使用
,而是只取前半部分的
。
到这里,我们希望所寻找的 既有标签
,又可以让
所转换得到的
的表达具有Distributed representation中所演示的特点。
同时我们还知道,
单词意思需要放在特定的上下文中去理解。
那么具有相同上下文的单词,往往是有联系的。
实例:那这两个单词都狗的品种名,而上下文的内容已经暗指了该单词具有可爱,会舔人的特点。
- 这个可爱的 泰迪 舔了我的脸。
- 这个可爱的 金巴 舔了我的脸。
而从上面这个例子中我们就可以找到一个 :预测上下文。
用输入单词作为中心单词去预测其他单词
出现在其周边的可能性。
我们既知道对应的 ,同时该任务
又可以让
所转换得到的
的表达具有Distributed representation中所演示的特点。 因为我们让相似的单词(如泰迪和金巴)得到相同的输出(上下文),那么神经网络就会将泰迪的输入和金巴的输入经过神经网络
得到的泰迪的输出和 金巴的输出几乎相同。
用输入单词作为中心单词去预测周边单词的方式叫做:Word2Vec The Skip-Gram Model。
用输入单词作为周边单词去预测中心单词的方式叫做:Continuous Bag of Words (CBOW)。
Embedding Layer其实就是lookup table,具有降维的作用。输入到网络的向量常常是非常高的维度的one-hot vector,比如8000维,只有一个index是1,其余位置都是0,非常稀疏的向量。Embedding后可以将其降到比如100维度的空间下进行运算。
同时还有额外的特点,比如:
词向量“女人”与“男人”的距离 约定于 “阿姨”与“叔叔”距离。
W(‘‘woman")?W(‘‘man") ? W(‘‘aunt")?W(‘‘uncle")
W(‘‘woman")?W(‘‘man") ? W(‘‘queen")?W(‘‘king")
更多关于词向量的内容参考http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/