题记:
临近农历年关(对国人来说,这个才叫新年嘛),工作琐事较多,因此本月发博数量锐减至①篇。虽不以博文数量为目标,但每月一篇的数量还是说不过去。博文数量锐减,总结下来有两个原因:
第一,近期在花时间对比分析DICOM各大开源库中使用的各种线程池技术,诸如fo-dicom中的ThreadPoolQueue、ThreadPool,dcm4chee中的LF_ThreadPool、newCachedThreadPool、newSingleThreadScheduledExecutor等。但还未整理出思绪,未找到很好的切入点。
第二,原本计划中的每月“医疗时鲜资讯”系列,也因为资本市场的浮躁和自己的迷茫而找不新的吐槽点。
赶在农历新年放假前,整理出“DICOM开源库多线程分析系列”的第一篇博文。
背景:
之前博文DICOM:DICOM3.0网络通信协议之“开源库实现剖析”中,简短提到过fo-dicom开源库中使用的自定义线程池队列ThreadPoolQueue,以及dcm4chee中使用的java的Executors类中的newCachedThreadPool、 newSingleThreadScheduledExecutor。其中fo-dicom的ThreadPoolQueue是基于.NET系统ThreadPool线程池基础上添加了分类管理功能,dcm4chee在解析时使用的是java提供的多种预设线程池。
对于.NET与java两种系统自带线程池的对比会放到该系列的随后博文中,本篇博文着重介绍dcm4chee中使用的Leader/Follower线程池LF_ThreadPool。
线程池:Leader/Follower ThreadPool
Leader/Follower线程池模型状态切换示意图如下: 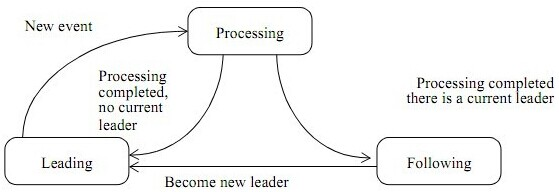
在Leader/Follower线程池模式下,线程可处于三种状态:leader、follower、processor。处于leader状态的线程负责响应客户端请求(诸如ServerSocker.accept()监听某个端口),当客户端请求到来时,leader线程会从follower状态的诸多线程中选出新的线程作为leader继续监听客户端请求,自己则放弃leader角色进入到processor状态,开始处理客户端请求的实际操作。
借用58沈剑的总结,Leader/Follower多线程模型有六个关键点:
(1)线程有3种状态:领导leading,处理processing,追随following;
(2)假设共N个线程,其中只有1个leading线程(等待任务),x个processing线程(处理),余下有N-1-x个following线程(空闲);
(3)有一把锁,谁抢到就是leading;
(4)事件/任务来到时,leading线程会对其进行处理,从而转化为processing状态,处理完成之后,又转变为following;
(5)丢失leading后,following会尝试抢锁,抢到则变为leading,否则保持following;
(6)following不干事,就是抢锁,力图成为leading;
Leader Follower相较于传统的线程池的优点是不需要消息队列,其自身具有一定的“智能”,我们参照dcm4chee的LF_ThreadPool的具体代码来看一下:
public void join(){log.debug("Thread: " + Thread.currentThread().getName() + " JOIN ThreadPool " + name);try {while (!shutdown && (running == 0 || maxWaiting == -1 || waiting < maxWaiting)&& (maxRunning == 0 || (waiting + running) < maxRunning)){synchronized (mutex){while (leader != null){if (log.isDebugEnabled())log.debug("" + this + " - "+ Thread.currentThread().getName() + " enter wait()");++waiting;try { mutex.wait(); }catch (InterruptedException ie){log.error(ie);}finally { --waiting; }if (log.isDebugEnabled())log.debug("" + this + " - "+ Thread.currentThread().getName() + " awaked");}if (shutdown)return;leader = Thread.currentThread();if (log.isDebugEnabled())log.debug("" + this + " - New Leader"); ++running;}try { do {handler.run(this);} while (!shutdown && leader == Thread.currentThread());} catch (Throwable th) {log.warn("Exception thrown in " + Thread.currentThread().getName(), th);shutdown();} finally { synchronized (mutex) { --running; } }}} finally {log.debug("Thread: " + Thread.currentThread().getName() + " LEFT ThreadPool " + name);}}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
从上述join函数内部的多层循环(两层while循环、一层do-while循环)可以清晰看出Leader/Follower线程池之所以不需要使用队列来管理池内各线程,究其原因是各线程自身内部的判定逻辑可形成闭环,即:
各线程内部能够自我判定各自的状态,从而做出适当的选择,诸如
1)创建新的线程并选为leader、
2)自身转换为leader监听客户端请求、
3)转换为follower进入waiting状态、
4)退出,避免过多的等待线程
从而形成一个指定运行数与等待数的稳定线程池。
dcm4chee的LF_ThreadPool实际测试
dcm4chee中使用LF_ThreadPool线程池来监听客户端的TCP请求,线程池的实现放在LF_ThreadPool.java文件中,具体的处理过程放在ServerImpl.java与ActiveAssociationImpl.java文件中。由于dcm4chee整个工程量巨大,调试过程相对复杂,为了演示LF_ThreadPool线程池的具体运行状态,我在本地单独编写了一个工程进行测试(工程代码可去我的github主页CSDN仓库下下载)。
1.初始LF_ThreadPool线程池线程数为1
这种方式是LF_ThreadPool线程池区别于.NET以及java系统线程池的地方,由于LF_ThreadPool模型会根据整体线程池运行状态选出新的leader线程(当然包括创建新的线程、提升follower线程等)。因此线程池初始化时可以只创建单一线程。
new Thread(new Runnable(){@Overridepublic void run(){main.pool.join();}}).start();- 1
- 2
- 3
- 4
- 5
- 6
- 7
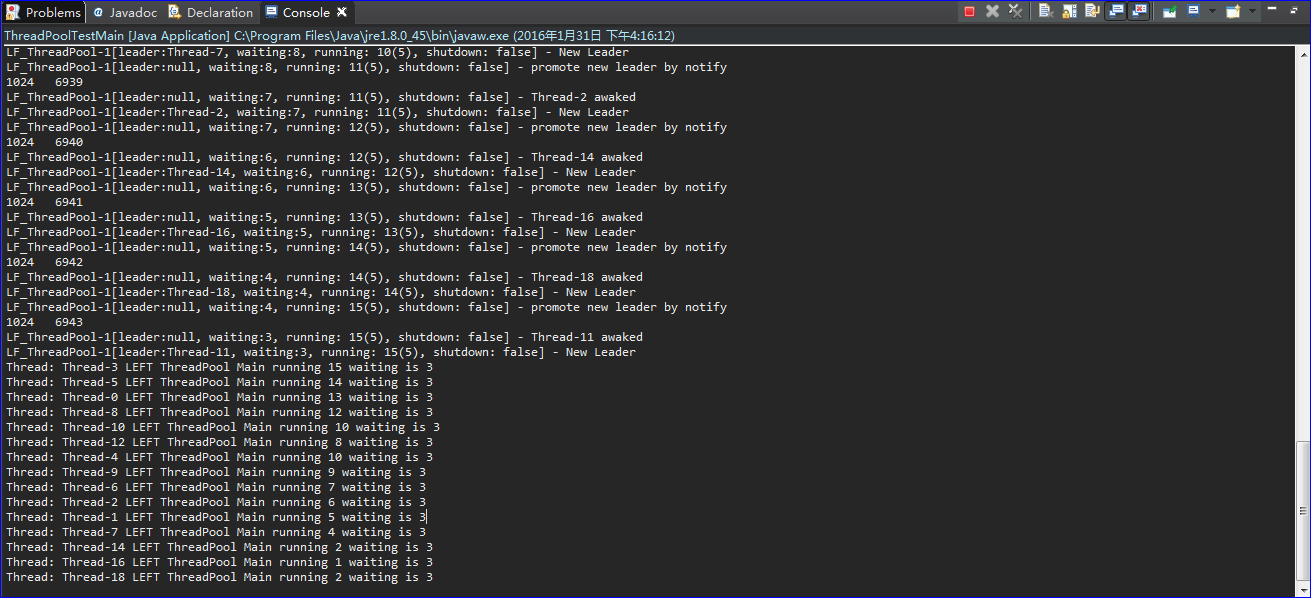
随着客户端请求数量增加,LF_ThreadPool线程池会自动创建指定数量的线程来响应用户需求,待处理完毕后又会自动返回等待状态,关闭多余waiting线程。我本地运行调试结果如下:
从上图可以清晰看出,起初的单个线程会随着客户端请求的增加逐渐创建新的线程直至最大运行线程数。
2.初始LF_ThreadPool线程池线程数为n
LF_ThreadPool线程池除了上述单线程启动模式外,也可以提前开启任何n个线程,此时n
public static void main(String[] args) {// TODO Auto-generated method stubThreadPoolTestMain main=new ThreadPoolTestMain();main.initLF_ThreadPool();for(int i=0;i<5;++i){new Thread(new Runnable(){@Overridepublic void run(){main.pool.join();}}).start();}try {System.in.read();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}private void initLF_ThreadPool(){pool.setMaxRunning(5);pool.setMaxWaiting(3);}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
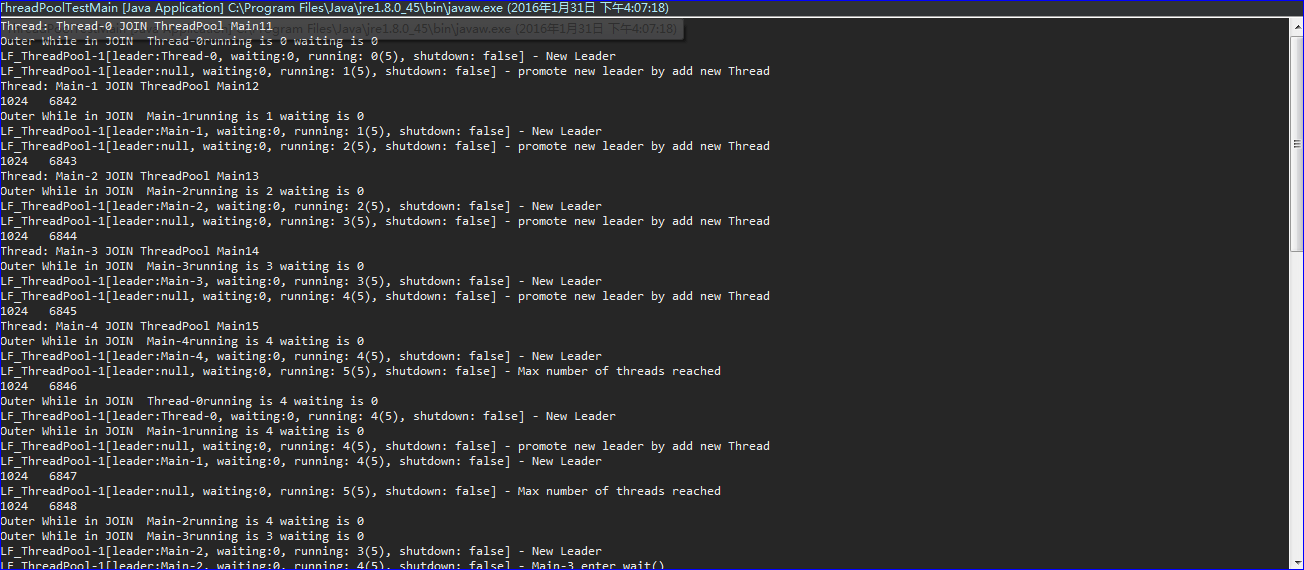
程序启动时刻的输出日志如下,由此可以看出预先开设的线程会选出一个充当leader角色,通过ServerSocket.accept()来监听用户请求,其余进入waiting状态充当follower角色,对于过多的follower会根据maxwaiting数适当关闭多余线程。
Thread: Thread-0 JOIN ThreadPool Main11
Thread: Thread-3 JOIN ThreadPool Main14
Thread: Thread-2 JOIN ThreadPool Main13
Thread: Thread-1 JOIN ThreadPool Main12
Thread: Thread-4 JOIN ThreadPool Main15
Outer While in JOIN Thread-2running is 0 waiting is 0
Outer While in JOIN Thread-3running is 0 waiting is 0
LF_ThreadPool-1[leader:Thread-2, waiting:0, running: 0(5), shutdown: false] - New Leader
LF_ThreadPool-1[leader:Thread-2, waiting:0, running: 1(5), shutdown: false] - Thread-3 enter wait()
Outer While in JOIN Thread-0running is 0 waiting is 0
Outer While in JOIN Thread-4running is 0 waiting is 0
Outer While in JOIN Thread-1running is 0 waiting is 0
LF_ThreadPool-1[leader:Thread-2, waiting:1, running: 1(5), shutdown: false] - Thread-0 enter wait()
LF_ThreadPool-1[leader:Thread-2, waiting:2, running: 1(5), shutdown: false] - Thread-1 enter wait()
LF_ThreadPool-1[leader:Thread-2, waiting:3, running: 1(5), shutdown: false] - Thread-4 enter wait()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
待客户端发起请求后,运行日志如下:
这里为了突出显示LF_ThreadPool线程池关闭多余waiting线程的功能,我将初始化时刻的线程数扩大到了20,而设置最大等待数maxwaiting为3。
Leader/Follower线程池随想
1. 操作系统的时间中断
实际测试dcm4chee的Leader/Follower线程池,可以体会到该模型的优点。通过各线程池自身完整的判断逻辑来实现监听、处理等操作在同一个线程中完成,增强了CPU高速缓存相似性,消除了动态内存分配和线程间的数据交换,降低了线程上下文切换的成本。
在时钟中断周期对操作系统整体实时性的影响分析博文中对时钟中断进行了详细介绍。了解了时钟中断后,会更好地理解多线程、线程池的运行机制。
可用两个指标来衡量操作系统的实时性:一个是中断响应时间,即从外部中断发生,到得到操作系统处理之间的时间;另外一个是任务切入时间,即一个高优先级的线程运行所需的资源就绪,到得到调度所需的时间。时钟中断周期的大小,与这两个指标并无直接关联。
本文介绍的Leader/Follower线程池模型主要是希望减少任务切入时间来提高实际处理效率,即通常认为的线程上下文切换成本。
2. 分布式大数据时代
但任何模型都有其实际应用的场景,倘若同时有海量客户端发出请求,上述第二种本地模拟测试在初始就创建n个线程的方式比较合理。但它也有一个上限,那就是ServeSocket自身缓冲队列。与此同时对于ServerSocket而言,操作系统会提供缓冲队列来缓冲用户端快速的请求,但同样其响应速度和响应数量也有上限(时钟中断周期对操作系统整体实时性的影响分析)。
任何模型都有其自身的局限性,在极端情况下都会存在满负荷的情况,但通过线程池、操作系统(软件层面)和多核心、分布式系统(硬件层面)等技术可以解决海量请求。从单机单用户到单机多用户,从单线程到多线程,到现在的网络时代,直至大数据分布式时代,都是在围绕着高并发(提高响应数量)、高时效(提升响应速度)两个问题来解决。倘若摩尔定律永远成立,那么当今计算机科技依然会围绕着提高单晶片晶体管数量来努力,或许就不需要现如今的分布式。
【摩尔定律指出】:当价格不变时,每隔18个月,集成电路上可容纳的晶体管数据会增加一倍,性能也会提升一倍。
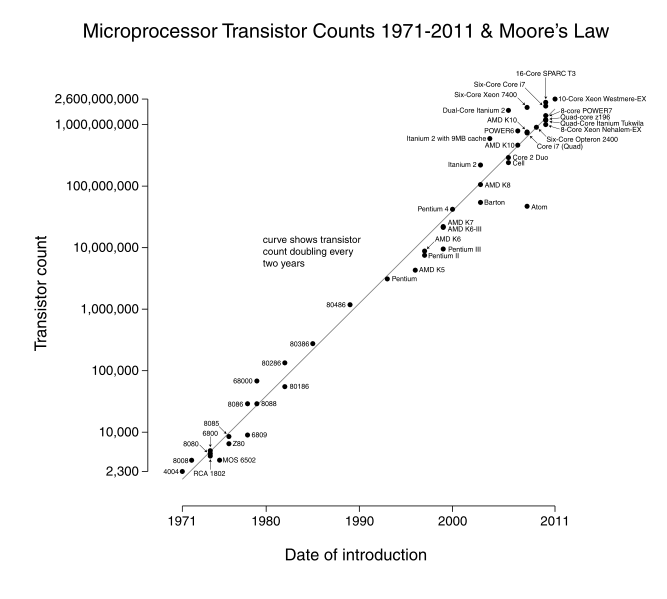
所谓的分布式系统其实依然可以看成一台巨大的冯诺依曼计算机,同样包括运算器、控制器、存储器、输入设备、输出设备五大部分。只不过在无法提升单晶片中晶体管数量的情况下,通过增加控制器的控制逻辑(Leader/Follower模型也是从提升各线程内部控制逻辑来去除了线程队列)来实现横向扩展。
本系列随后博文会继续介绍fo-dicom/dcmtk/dcm4che等开源库中使用到的多线程 技术,通过从微观层面的多线程入手分析,最终在宏观上实现DICOM服务分布式部署。
本地测试工程源码:
1. CSDN资源:LF_ThreadPool
2. Github CSDN仓库LF_ThreadPool
作者:zssure@163.com
时间:2016-01-31