���ڳ����ص��Լල:ѵ����ע�͵�Few-Shotҽѧͼ��ָ�
���ĵ�ַ
��Դ����
ժҪ
Few-Shot����ָ�(FSS)��ҽѧӰ��������й�����Ӧ��ǰ������������е�FSS��������Ҫ������ע��������������ѵ����������ȱ����ע����Щ�������ܲ�������ҽѧͼ��Ϊ�˽����һ���⣬�������������¼��㹱�ף�(1)�����һ���µ��Լලҽѧͼ��FSS��ܣ�������ѵ�������жԱ�ע��Ҫ�����ɻ��ڳ����ص�α��ǩ���мල��(2)������Ӧ�ֲ�ԭ�ͳػ�ģ�����ԭ�����磬���ҽѧͼ��ָ��г�����ǰ��-������ƽ�����⣻(3)����֤����������ķ�����һ�������ԣ�ҽѧͼ��ʹ��������ͬ������������CT��MRI�ָ�Լ������MRI�ָ�����������ҽѧͼ��ָ�棬�÷������ڴ�ͳ����Ҫ�˹���עѵ����FSS������
���ڵ����⼰�������
���еĴ����few-shot����ָ�ģ����ҽѧͼ���ϲ�����ɹ�����Ϊ�������FSS���������ڴ�����ѵ�����ݼ�������ע�͵�ѵ�������������ϡ�Ϊ���ƹ��������������ע���������������δ��ǵ�ͼ����ѵ��FSSģ�ͣ�������ͨ���������Լලѧϰ������һ���ල������ͨ��������Ƶ�������ѧϰ�ɷ�����ͼ���ʾ�������������Ƚ���FSS������ϵ�ṹ��˵����һ����ս����һ���ռ�仯������ѧϰ�ı�ʾ����ʧ�ֲ���Ϣ����һ������ҽѧͼ��������ͻ������Ϊҽѧͼ�����ձ�����ż��˵�ǰ��-������ƽ�⡣

��ͼ1(b)��ʾ������ϴ��ҿռ��ϲ����ȣ���ǰ����(��ɫ)��С�Ҿ��ȡ�����������£������������ƽ���������в�ͬ�ֲ�����(��)�IJ�ͬ�����Ϣ�����ܻᵼ��ǰ�������߽�Ԥ���ģ���ԡ����ҵ��ǣ��������ھֲ���Ϣ�Ķ�ʧ�������������ж����ڣ�����Щ�����У�ÿ������ռ�ƽ��Ϊһ��һά��ʾԭ�ͻ����Է�������Ȩ��������Ϊ�˽��������⣬����ͨ��Ϊÿ������ȡ�ֲ���ʾ�ļ������������籣�����ڲ��ľֲ���Ϣ��
ͬʱΪ�˴���ѵ������ϡȱ�Ľ��֣���߷ָ�ȣ����������һ���Լල��Few-Shotҽѧͼ������ָ���SSL-ALPNet���ÿ�����û��ڳ����ص��Լලѧϰ(SSL)��ʹ�ó������������ֹ���ע����Ҫ���Լ�����Ӧ�ֲ�ԭ�ͳػ�֧�ֵ�ԭ������(ALPNet)��ͨ����ѧϰ�ı�ʾ�б����ֲ���Ϣ����߷ָ�ȡ�
��ͼ1 (a)��ʾ��Ϊ��ȷ��ͨ���Լලѧϰ����ͼ���ʾ���Ժܺõ��ƹ㵽��ʵ�������࣬����ʹ�ó���������α�����ǩ�����������������Ľ��չ����顣���⣬Ϊ�����ѧϰ����ͼ���ʾ�ı�����������������һ�ֻ���һ�����ص��Լලѧϰ����������Few-Shotҽѧͼ��ķָ
���⣬Ϊ�˼�ǿ֧�ֺͲ�ѯ֮���ʾ�IJ����ԣ������ʵ�����е�Few-Shot�ָ���������Ҫ�ģ�����ͨ��Ӧ��֧�ֺͲ�ѯ֮���������α仯��ǿ��ת�����ϳ��µ���״��ǿ��ͼ���⣬Ϊ����߷ָ�ľ��ȣ���ͼ1��ʾ���������������Ӧ�ֲ�ԭ��ģ��(adaptive local prototype module, ALP)����ÿ�����ԭ�ͱ�ʾ�б�����ֲ���Ϣ������ͨ����ȡһ���ֲ�����ԭ����ʵ�ֵģ�ÿ��ԭ��ע��ͬ������ֵ��ע����ǣ�ԭ�͵��������������ÿ����Ŀռ��С����Ӧ���䡣ͨ�����ַ�ʽ��ALP������Ч�ؽ���ֲ���Ϣ���㵼�µķָ�ģ�����⡣
����

����Ӧ�ֲ�ԭ�ͳػ���Adaptive local prototype pooling��
�������ͨ����������Ӧ�ֲ�ԭ�ͳػ�ģ��(ALP)������ԭ���еľֲ���Ϣ����ALP�У�ÿ���ֲ�ԭ�ͽ��ڸ�����֧���ϵľֲ��ش����м��㣬����ֻ��ʾ����Ȥ�����һ���֡�������˵��������ÿ��f��(xls)��RD��H��Wf_{\theta}\left(\mathbf{x}_{l}^{s}\right) \in \mathbb{R}^{D \times H \times W}f��?(xls?)��RD��H��W��ʹ��һ����СΪ(LH,LW)(L_H,L_W)(LH?,LW?)�ijػ�������Ҫע����ǣ�(LH,LW)(L_H,L_W)(LH?,LW?)�������ڱ�ʾ�ռ�E\mathcal{E}E�м���ÿ���ֲ�ԭ�������ݵĿռ䷶Χ��ƽ���ػ�����ͼ�ڿռ�λ��(m,n)(m,n)(m,n)����ccc�ϵľֲ�ԭ��pl,mn(c)p_{l,mn}\left( c \right)pl,mn?(c)���Ա�ʾΪ��
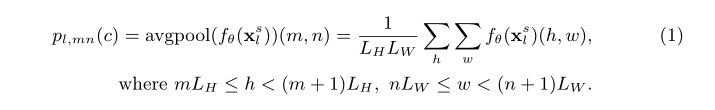
Ϊ�˾���ÿ��pl,mn(c)p_{l,mn}\left( c \right)pl,mn?(c)����ccc������ƽ���ػ�ǰ����cj^c^{\hat{j}}cj^?�Ķ�ֵ����yls(cj^)\mathbf{y}_{l}^{s}\left(c^{\hat{j}}\right)yls?(cj^?)����ͬ��С(HLH,WLW)\left(\frac{H}{L_{H}}, \frac{W}{L_{W}}\right)(LH?H?,LW?W?)����yl,mnay_{l,mn}^ayl,mna?��ʾyls(cj^)\mathbf{y}_{l}^{s}\left(c^{\hat{j}}\right)yls?(cj^?)��λ��(m,n)(m,n)(m,n)��ʹ��ƽ���ػ����ֵ��ccc����ֵΪ��
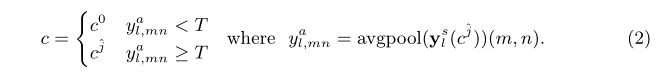
TΪǰ�����½���ֵ�����ݾ�������Ϊ0.95��
Ϊȷ��С�ڳػ���(LH,LW)(L_H,L_W)(LH?,LW?)��С������ܱ���������һ��ԭ�ͣ�����ͬ��ʹ������ƽ���ػ��������༶(class-level)��ԭ��plg(cj^)p_{l}^{g}\left(c^{\hat{j}}\right)plg?(cj^?)��
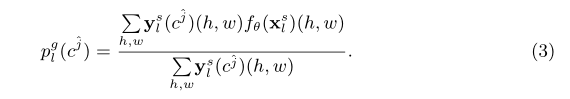
���Ϊ�˷��������pl,mn(cj)p_{l,mn}\left( c^j \right)pl,mn?(cj)��plg(cj^)p_{l}^{g}\left(c^{\hat{j}}\right)plg?(cj^?)���±�kkk�����������Ӷ����ԭ�ͱ�ʾ����P={pk(cj)}\mathcal{P}=\left\{p_{k}\left(c^{j}\right)\right\}P={
pk?(cj)}��ͨ������ͬ�ľֲ�������ʽ�ر�ʾΪ������ԭ�ͣ������˸�������ھֲ�����
�������ƵķָSimilarity-based segmentation��
��ƻ������ƶȵķ�����sim(?��?)sim(������)sim(?��?)������P\mathcal{P}P�еľֲ�ͼ����Ϣ�Բ�ѯ�����ܼ�Ԥ�⣬���Ƚ�ÿ��ԭ�����ѯ�е���Ӧ�ֲ��������ƥ�䣬Ȼ�ֲ��������ں���һ��
Ϊ���ڲ�ѯ�зָ�һ����ĸ��࣬�ڵ�һ�Σ�һ����ΪcL=liverc^L=livercL=liver�ľֲ�ԭ��pk(cL)p_k(c^L)pk?(cL)�����ػ������ڸ���Ҷ��ʱ���ᷢ��һ����������Ҷ������(����������������ƥ��)��Ȼ��Ҫ�õ�һ�������ĸ��࣬���Ҹκ�����ں���һ���γ�һ�����ࡣ
����أ�sim(?��?)sim(������)sim(?��?)�����ò�ѯ����f��(xq)f_{\theta}\left(\mathbf{x}^{q}\right)f��?(xq)��ԭ�ͼ���P={pk(cj)}\mathcal{P}=\left\{p_{k}\left(c^{j}\right)\right\}P={
pk?(cj)}��Ϊ��������������֮��ľֲ�����ͼSk(cj)S_k(c^j)Sk?(cj)����f��(xq)f_{\theta}\left(\mathbf{x}^{q}\right)f��?(xq)��Ӧ�Ŀռ�λ��(h,w)(h, w)(h,w)�ϵ�ÿ������Sk(cj)(h,w)S_k(c^j)(h,w)Sk?(cj)(h,w)�ɣ�
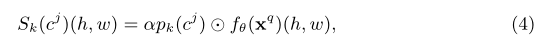
���У���\odot����ʾ�������ƣ�����a��b=?a,b?��a��2��b��2a\odot b=\frac{\langle a, b\rangle}{\|a\|_{2}\|b\|_{2}}a��b=��a��2?��b��2??a,b?? a,b��RD��1��1a, b \in \mathbb{R}^{D \times 1 \times 1}a,b��RD��1��1������һ���˷�������������ѵ���е��ݶȷ�����
Ȼ��Ϊ�˵õ�ÿ����cjc^jcj���������ͼ(δ��һ��)�����ֲ�����ͼSk(cj)S_k(c^j)Sk?(cj)�ֱ��ںϵ�ÿ�����г�Ϊclass-wise������S��(cj)S'(c^j)S��(cj)��
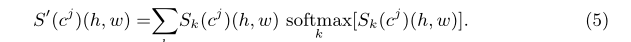
softmax?k[Sk(cj)(h,w)]\operatorname{softmax}_{k}\left[S_{k}\left(c^{j}\right)(h, w)\right]softmaxk?[Sk?(cj)(h,w)]��ʾ�Ƚ�����S��(cj)(h,w)S'(c^j)(h,w)S��(cj)(h,w)��ͨ���ߴ���ӣ��ټ�����ͨ����softmax������
Ϊ�˵õ����յij���Ԥ�⣬���������ƶȹ�һ��Ϊ����:
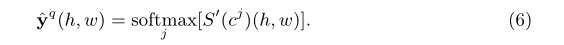
���ڳ����ص��Լලѧϰ��Superpixel-based Self-supervised Learning��

Ϊ�˻��ȷ��³���Ľ�����������ƶȵķ�������Ҫ�������ԡ�����ÿ���࣬���ʾӦ���Ǿ���ģ�����Ϊ�������ƶ�����ӵ���б��ԣ�ͬʱ����Щ��ʾ��ͼ��֮��Ӧ���Dz���ģ������ǵ���������ָ֧�ֺͲ�ѯ���κ���ϣ�����ȷ��Ԥ���³���ԡ�
�����������ܵ��˻��ڳ����ص����Ҽලѧϰ(SSL)�Ĺ�����������ʵ�������ע�Ͳ����ã�SSL����α��ǩ�ڳ����ؼ�ǿ�Ƽ�Ⱥ������ͨ�������������ƶȵķ����������ָ���ʧ��Ȼʵ�ֵġ�����������ؼ��ľ������Կ���ת�Ƶ���ʵ�������࣬��Ϊһ����������ͨ���ɼ�����������ɡ����⣬Ϊ�˹���ͼ�������ռ��ʾ��ͼ��֮�����״��ǿ�Ȳ��챣�ֲ��䣬������֧�ֺͲ�ѯ֮��ִ�м��κ�ǿ��ת����������Ϊ��״��ǿ����ҽѧͼ��仯�������Դ��
Unspervised pseudolabel generation��
Ϊ�˻��α��ǩ�ĺ�ѡ����ÿ��ͼ��xix_ixi?���ɳ����ؼ���Yi=F(xi)\mathcal{Y}_{i}=\mathcal{F}\left(\mathbf{x}_{i}\right)Yi?=F(xi?)��ʹ��F\mathcal{F}F��ʾ���ල�㷨������Ч��������һ�㡣
Online episode composition��
����ÿһ��episodeiii��һ��ͼ��xix_ixi?��һ�����ѡ��ij�����yir(cp)��Yi\mathbf{y}_{i}^{r}\left(c^{p}\right) \in \mathcal{Y}_{i}yir?(cp)��Yi?�����γ�֧�ּ�Si={(xi,yir(cp))}\mathcal{S}_{i}=\left\{\left(\mathbf{x}_{i}, \mathbf{y}_{i}^{r}\left(c^{p}\right)\right)\right\}Si?={
(xi?,yir?(cp))}������yir(cp)\mathbf{y}_{i}^{r}\left(c^{p}\right)yir?(cp)��ʾ������r=1,2,3,��,�OYi�Or=1,2,3, \ldots,\left|\mathcal{Y}_{i}\right|r=1,2,3,��,�OYi?�O�Ķ�ֵ���룬cpc^pcp��ʾα��ǩ(pseudolabel)�ࣨ��Ӧ�ı�������yir(c0)\mathbf{y}_{i}^{r}\left(c^{0}\right)yir?(c0)��1?yir(cp)1-\mathbf{y}_{i}^{r}\left(c^{p}\right)1?yir?(cp)��ʾ����ͬʱ����ѯ��Qi={(Tg(Ti(xi)))},Tg(yir(cp)))\left.\mathcal{Q}_{i}=\left\{\left(\mathcal{T}_{g}\left(\mathcal{T}_{i}\left(\mathbf{x}_{i}\right)\right)\right)\right\}, \mathcal{T}_{g}\left(\mathbf{y}_{i}^{r}\left(c^{p}\right)\right)\right)Qi?={
(Tg?(Ti?(xi?)))},Tg?(yir?(cp)))ͨ����֧�ּ�Ӧ��������κ�ǿ�ȱ任������������ÿһ��(Si,Qi)(S_i,Q_i)(Si?,Qi?)���γ���1-way 1-shot�ָ����⡣��ʵ���У�Tg(?)\mathcal{T}_g\left( \cdot \right)Tg?(?)��������任�͵��Ա任��Ti(?)\mathcal{T}_i\left( \cdot \right)Ti?(?)��gamma�任��
End-to-end training��
�������Ƕ˵��˵�ѵ��������ÿ�ε���iii��һ��episode(Si,Qi)(S_i,Q_i)(Si?,Qi?)��Ϊ���롣���ý�������ʧ��ÿ�ε����ķָ���ʧLsegi\mathcal{L}^i_{seg}Lsegi?Ϊ:
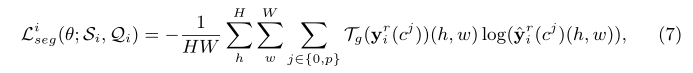
����y^ir(cp)\hat{\mathbf{y}}_{i}^{r}\left(c^{p}\right)y^?ir?(cp)��ʾ��ѯα����Tg(yir(cp))\mathcal{T}_{g}\left(\mathbf{y}_{i}^{r}\left(c^{p}\right)\right)Tg?(yir?(cp))��Ԥ�⣬���ǻ�ʹ����ԭ�Ͷ���������Ԥ�ⷴ������Ϊsupport��Ҳ����S��=(Tg(Ti(xi)),y^ir(cp))\mathcal{S}^{\prime}=\left(\mathcal{T}_{g}\left(\mathcal{T}_{i}\left(\mathbf{x}_{i}\right)\right), \hat{\mathbf{y}}_{i}^{r}\left(c^{p}\right)\right)S��=(Tg?(Ti?(xi?)),y^?ir?(cp))����Ӧ����ȷ�ָ�ԭʼ֧��ͼ��xix_ixi?������������ʾ�ģ�
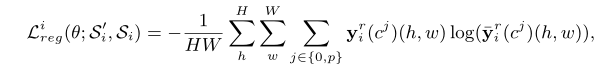
����y?ir(cp)\overline{\mathbf{y}}_{i}^{r}\left(c^{p}\right)y?ir?(cp)��ʾ��xix_ixi?Ϊ��ѯ��yir(cp)\mathbf{y}_{i}^{r}\left(c^{p}\right)yir?(cp)��Ԥ�⡣
�ܵ���˵��ÿ��epioside����ʧ����Ϊ��
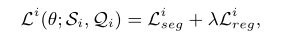
ʵ����


�ܽ�
��������У����������һ���Լල���پ�ͷҽѧͼ��ָ��ܡ��÷����ڲ���Ҫ�κ��ֹ����ѵ��������£��ɹ��س�Խ���Լලѧϰ���پ�ͷҽѧͼ��ָ��е�SOTA������
���⣬�����ǵ�ʵ���У���֤���˶Կ��������������ǿ���������⣬������Ļ��ڳ����ص����Ҽල����Ϊͼ���ʾѧϰ�ṩ��һ����Ч�ķ�����Ϊδ����ල���ලͼ��ָ���������µĿ����ԡ�