基于循环一致Transformer的Few-Shot分割
论文地址
摘要
Few Shot分割的目的是训练一种能够快速适应样本较少的新类别的分割模型。传统的训练范式是促使模型学习根据支持图像的特征对查询图像进行预测的能力。以前的方法通常只利用支持图像的语义级原型作为条件信息,但这些方法不能利用所有像素级支持信息来进行查询预测,而这对于分割任务通常是非常重要的。在本文中,我们着重于利用支持图像和查询图像之间的像素级关系来促进Few-Shot语义分割任务。我们设计了一个新颖的循环一致Transformer模块(CyCTR),将像素级支持特征聚合到查询特征。CyCTR在来自不同图像(即支持和查询图像)的特征之间执行交叉关注。同时我们还观察到直接执行交叉关注可能存在意想不到的无关像素级特征,这么做将会从支持特征上聚合这些无关信息到查询中,导致查询图像的偏倚(bias)。因此,我们提出使用一种新颖的循环一致的关注机制来过滤掉可能有害的支持特征,并鼓励查询特征关注支持图像中信息量最大的像素。
存在的问题及解决方案
目前大多数Few Shot分割方法遵循“learning-to-learn”的范式,以支持图像的特征和标注为条件来预测查询图像。这种训练范式成功的关键在于如何有效地利用支持图像提供的信息。以前的方法从支持特征中提取语义级原型,并遵循从原型网络延伸的度量学习方案。根据支持特征的利用粒度,这些方法可以被分为如下几种:

- 如(a)所示的类别平均池化,不同类别的区域内的支持特征被平均作为原型,以便于查询像素的分类。
- 如(b)所示的聚类方案,这些基于聚类的方法需要将支持信息“压缩”到不同的原型中从而捕获类内变化信息,但这可能导致不同程度的有益支持信息的丢失,从而损害对查询图像的分割。
- 如(c)所示采用注意力机制从支持前景像素中提取信息,用于分割查询。然而,这种方法忽略了所有背景支持像素,而这对于分割查询图像是有益的。并且会错误地考虑与查询像素完全不同的部分前景支持像素,导致次优结果。
在本文中,我们着重于为每个查询像素配备来自支持图像的相关信息,以便于查询像素分类。受通过注意力机制聚合特征的Transformer的启发,我们设计了如(d)所示的一种循环一致Transformer模块,将像素级支持特征聚合到查询特征中。具体来说,我们的CyCTR由两种类型的Transformer模块组成:自对准模块(self-alignment block)和交叉对准模块(cross-alignment block)。自对准模块用于通过聚集查询图像本身的context信息来对查询图像特征进行编码,而交叉对准模块用于将支持图像的像素级特征聚集到查询图像的像素级特征中。与查询(Query)、关键字(Key)和值(Value)(Transformer概念)来自相同嵌入的自对准不同,交叉对准将来自查询图像的特征作为查询,将来自支持图像的特征作为关键字和值。这样,CyCTR为查询图像的像素特征提供了丰富的像素支持信息,以进行预测。
此外,我们观察到,由于支持图像和查询图像之间的差异,例如尺度、颜色和场景,只有一小部分支持像素可以有利于查询图像的分割。换句话说,在支持图像中,一些像素级信息可能会混淆Transformer中的注意力。图2提供了一个支持查询对和标签掩码的可视化示例。

迷惑性的支持像素可能来自前景像素和背景像素。例如,支持图像中的点p1p_1p1?位于远处的平面,它由支持mask指示为前景。然而,查询图像中的最接近的点p2p_2p2?(即p1p_1p1?与p2p_2p2?具有最大的特征相似性)实际上属于不同的类别,例如背景。这意味着不存在与p1p_1p1?具有高度相似性和相同语义标签的查询像素。因此。p1p_1p1?可能对分割“plane”有害,需要在进行attention时忽略。为了克服这个问题,在CyCTR中,我们建议给交叉对齐模块配备一个循环一致的注意力操作。具体来说,如图2所示,从支持特征的一个空间点开始,我们在查询特征中找到它的最接近点。反过来,利用这个最接近点找到最相似的支持特征。如果初始支持特征和反向查询的支持特征来自同一类别,则建立循环一致性关系。我们将这样的操作结合到注意力中,以强制查询特征只关注循环一致的支持特征来提取信息。这样就不考虑离查询像素较远的支持像素。同时,循环一致的关注使我们能够更安全地利用来自背景支持像素的信息,而不会在查询特征中引入太多偏差。
方法

自对准模块仅将展平的查询特征作为输入,以确保自对准。由于每个像素的上下文信息已经被证明有利于分割,我们采用自对准块来聚类查询图像像素级特征的全局context信息。我们不通过这个自对准块来处理支持图像,因为我们主要关注查询图像的分割性能,使用与查询掩码不协调的支持图像可能会对查询图像的自对准造成损害。
相比之下,交叉对齐模块在查询和支持像素级特征之间执行关注,以将相关支持特征聚合到查询特征中。使用这两个块,可以更好地对查询特征进行编码,以便于后续的像素分类。
Revisiting of Transformer
遵循一般的范式,Transformer公式表示如下:
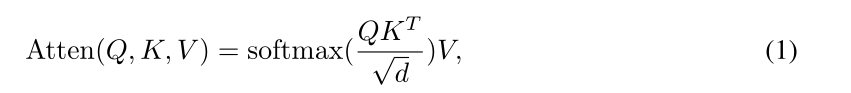
其中[Q;K;V]=[WqZq;WkZkv;WvZkv][Q ; K ; V]=\left[W_{q} Z_{q} ; W_{k} Z_{k v} ; W_{v} Z_{k v}\right][Q;K;V]=[Wq?Zq?;Wk?Zkv?;Wv?Zkv?],ZqZ_qZq?表示输入的查询序列(Query sequence),ZkvZ_{kv}Zkv?表示输入的键/值序列(Key/Value sequence),Wq,Wk,Wv∈Rd×dW_{q}, W_{k}, W_{v} \in \mathbb{R}^{d \times d}Wq?,Wk?,Wv?∈Rd×d为可学习的参数,ddd是输入序列的隐藏维数,默认情况下,我们假设所有序列都具有相同的维数ddd。注意力层通过将每个查询元素(Query element)加入到所有键元素(Key elements)中来计算归一化注意力权重AT=softmax?(QKTd)A T=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right)AT=softmax(d?QKT?),然后与值序列聚合得到Atten。当Zq=ZkvZ_q=Z_{kv}Zq?=Zkv?时,这一函数则可表示为自注意机制。
多头注意层是注意层的扩展,它执行hhh个注意操作并将结果连接在一起。具体地,它将输入维度ddd分成hhh组以获得
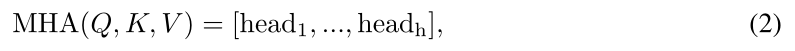
其中head?m=Atten?(Qm,Km,Vm)\operatorname{head}_{\mathrm{m}}=\operatorname{Atten}\left(Q_{m}, K_{m}, V_{m}\right)headm?=Atten(Qm?,Km?,Vm?)和输入[Qm,Km,Vm]\left[Q_{m}, K_{m}, V_{m}\right][Qm?,Km?,Vm?]表示来自[Q,K,V][Q,K,V][Q,K,V]的第m个group。
Cycle-Consistent Attention
根据前面的讨论,纯像素级的注意力可能会被过多的有害支持特征所混淆。为了缓解这个问题,如图3(b)所示,提出了一个循环一致的注意操作。通常,一个亲和图A=QKTd,A∈RHqWq×NsA=\frac{Q K^{T}}{\sqrt{d}}, A \in \mathbf{R}^{H_{q} W_{q} \times N_{s}}A=d?QKT?,A∈RHq?Wq?×Ns?首先计算以度量所有查询和支持tokens之间的对应关系。然后,对于支持特征中的单个token位置j(j∈{0,1,…,Ns})j\left(j \in\left\{0,1, \ldots, N_{s}\right\}\right)j(j∈{
0,1,…,Ns?}),其在查询特征中的最相似点i?i^{\star}i?通过如下公式获得:

其中i∈{0,1,…,HqWq}i \in\left\{0,1, \ldots, H_{q} W_{q}\right\}i∈{
0,1,…,Hq?Wq?}表示展平后查询特征的索引。由于查询掩码不可访问,token i?i^{\star}i?的标签未知。但是,我们可以以类似的方式将其映射回支持特征,以找到其在支持序列中最相似的特征点j?j^{\star}j?:

给定支持标签Ms∈RNsM_{s} \in \mathbb{R}^{N_{s}}Ms?∈RNs?,如果Ms(j)=Ms(j?)M_{s(j)}=M_{s\left(j^{\star}\right)}Ms(j)?=Ms(j?)?,我们便称之为建立循环一致性。为支持序列中的所有token都构建循环一致性关系,利用循环一致性的一种可能方法是最大化匹配点之间的相似性。然而,在Few-Shot分割中,目标是使模型快速适应新的类别,而不是改进模型以适合训练类别。因此,我们将循环一致性纳入注意操作,以鼓励循环一致性的交叉注意。首先,通过遍历所有支持token,一个额外的偏置B∈RNsB \in \mathbb{R}^{N_{s}}B∈RNs?通过如下公式获得:
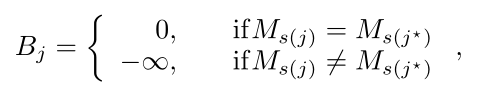
其中j∈{0,1,…,Ns}j \in\left\{0,1, \ldots, N_{s}\right\}j∈{
0,1,…,Ns?}。然后,对于一个单个在位置iii的查询token Zq(i)∈RdZ_{q(i)} \in \mathbb{R}^{d}Zq(i)?∈Rd,可以通过如下公式聚合支持信息:
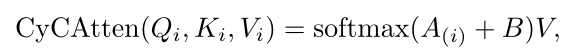
其中i∈{0,1,…,HqWq}i \in\left\{0,1, \ldots, H_{q} W_{q}\right\}i∈{
0,1,…,Hq?Wq?},AAA由QKTd\frac{Q K^{T}}{\sqrt{d}}d?QKT?获得。在前向计算过程中,BBB与对Zq(i)Z_{q(i)}Zq(i)?的亲和图A(i)A_{(i)}A(i)?按元素加来聚合支持特征。以这种方式,对于循环不一致支持特征的关注权重趋向于零,这意味着将不考虑这些不相关的信息。此外,循环一致性关注通过反向传播隐含地鼓励查询和支持特征之间最相关的特征之间的一致性,这可以增强模型以产生一致的特征表示。
此外,从支持到查询聚集最相关的支持特征会导致查询特征不一致。原因来自像素级聚合,不同的像素对于支持和查询有不同的亲和程度。虽然使用自注意操作(例如,在自对准块中)可以在一定程度上缓解这个问题,但是它也遭受类似的问题,即,在查询标记中融合背景特征和前景特征。受我们周期一致注意力的启发,从更可信的位置接收信息比从所有像素聚合更好。由于缺少查询掩码MqM_qMq?,无法为查询特征本身建立循环一致性关系。受到DeformableAttention启发,信用点(credit points)可以通过一种可学习的方法获得Δ=f(Q+\Delta=f(Q+Δ=f(Q+ Coord ))) and A′=g(Q+A^{\prime}=g(Q+A′=g(Q+ Coord ))),其中Δ∈RHpWp×P\Delta \in \mathbb{R}^{H_{p} W_{p} \times P}Δ∈RHp?Wp?×P表示预测的信用点,其中在Δ\DeltaΔ中的每个元素δ∈RP\delta \in \mathbb{R}^{P}δ∈RP表示每个像素的相对偏移量,并且PPP表示特征聚合点的数量。A′∈RHqWq×PA^{\prime} \in \mathbb{R}^{H_{q} W_{q} \times P}A′∈RHq?Wq?×P表示注意力权重。Coord ∈RHqWq×d\in \mathbb{R}^{H_{q} W_{q} \times d}∈RHq?Wq?×d表示位置编码来使预测感知绝对位置。f(?)f(\cdot)f(?) and g(?)g(\cdot)g(?)是预测偏移和注意力权重的两个全连接层,其中偏移被预测为2d坐标,并在展平序列中被转换为1d坐标。因此,自对准Transformer模块内的自注意机制表示如下:
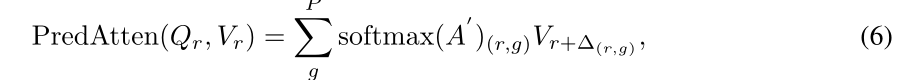
其中r∈{0,1,…,HqWq}r \in\left\{0,1, \ldots, H_{q} W_{q}\right\}r∈{
0,1,…,Hq?Wq?}表示展平查询特征的索引,QQQ和VVV都是通过将展平的查询特征乘以可学习参数获得的。
广义地说,周期一致的Transformer有效地避免了被可能的有害特征所偏置,从而便于Few-Shot分割的训练。
Mask-guided sparse sampling and K-shot Setting
我们提出的周期一致性Transformer可以很容易地扩展到K-shot设置,其中K > 1。唯一不同的是输入支持特征。当提供多个支持特征图时,所有支持特征将被展平并连接在一起作为输入。由于Transformer在像素级运行,因此需要一种采样策略来减少支持序列中的token数量。在这项工作中,我们应用一个简单的掩码引导采样策略来实现这个目标。具体来说,给定k-shot个支持序列Zs∈RkHsWs×dZ_{s} \in \mathbb{R}^{k H_{s} W_{s} \times d}Zs?∈RkHs?Ws?×d和展平的支持掩码Ms∈RkHsWsM_{s} \in \mathbb{R}^{k H_{s} W_{s}}Ms?∈RkHs?Ws?,通过均匀采样Nfg<=Ns2N_{f g}<=\frac{N_{s}}{2}Nfg?<=2Ns??得到采样支持序列,其中Ns≤kHsWsN_{s} \leq k H_{s} W_{s}Ns?≤kHs?Ws?,来自前景区域的token和其它的Ns?NfgN_{s}-N_{f g}Ns??Nfg?是从所有支持图像的背景区域中采样的。这降低了计算复杂度,使其独立于支持图像的空间大小。此外,该策略平衡了前景-背景比例,并且隐含地考虑了不同支持图像中每个对象区域的空间大小。
实验结果


总结
本文设计了一个CyCTR模块来处理Few-Shot分割问题。不同于以往采用支持图像的语义级原型或仅使用前景支持特征对查询特征进行编码的做法,我们的CyCTR利用了所有像素级支持特征,并能有效地消除聚集混淆和有害的支持特征,提出了新的循环一致注意力机制。我们在两个流行的基准上进行了广泛的实验,我们的CyCTR比以前的最先进的方法有很大的优势。我们希望这项工作能够激励研究人员设计更有效的算法来利用像素级支持特征来推进未来像素级Few-Shot学习的研究。