本博客是 论文 Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution 的翻译,由于作者本人水平有限,翻译难免有不准确的地方,还望读者不吝赐教,谢谢。
摘要
最近,卷积神经网络展示了其用于单图像超分辨率的高质量重建的用途。在本文中,我们提出了一种拉普拉斯金字塔超分辨率网络(LapSRN) ,该网络用于逐步重建高分辨率图像的子带残差。每个金字塔级别,我们的模型都将粗糙分辨率特征图作为输入,预测高频残差,并使用转置卷积向上采样到更精细的级别。我们的方法不需要双三次插值作为预处理步骤,因此可以大大降低计算复杂度。我们引入一种鲁棒的损失函数 (Charbonnier loss) ,在有监督的情况下训练 LapSRNA,得到了高质量的重建结果。此外,我们的网络通过渐进式重建的方式,在一次前馈中生成多尺度预测,从而促进了资源感知型应用。在基准数据集上进行的大量定量和定性评估表明,该算法在速度和准确性方面均与最新方法相比表现良好。
1、介绍
单图像超分辨率(SR)旨在从单个低分辨率(LR)输入图像中重建高分辨率(HR)图像。近年来,基于例子的SR方法通过使用大型图像数据库学习了从LR到HR图像补丁的映射,展示了最新的性能。许多学习算法已经被应用来学习这种映射,包括字典学习[37,38],局部线性回归[30,36]和随机森林[26]。
最近,董等人,提出了一种超分辨率卷积神经网络(SRCNN) [7] 来学习肥西那行的 LR 到 HR的映射。 该网络被扩展为嵌入基于稀疏编码的网络[33]或使用更深的结构[17]。虽然这些模型显示出令人鼓舞的结果,但仍然存在三个主要问题。首先,现有方法使用预定义的上采样操作,例如:双三次插值,在应用网络进行预测之前,先将输入图像放大到所需的空间分辨率。该预处理步骤增加了不必要的计算成本,并且经常导致可见的重建伪像。几种算法通过对 LR 图像使用转置卷积(或者反卷积,去卷积) 代替预定义的上采样操作来加速 SRCNN。但是,这些方法使用相对较小的网络,并且由于网络容量有限而无法很好地学习复杂的映射。其次,现有方法使用 L2L_2L2? 损失优化网络,因此不可避免的生成模糊的预测。由于 L2L_2L2? 损失不能捕获 HR补丁的基本多模态分布(即,同一LR补丁可能有许多相同的HR补丁) 重建的HR图像通常过于光滑,并且与自然图像上的人类视觉感知不接近。此外,大多数方法在一个上采样步骤中重建HR图像,这增加了训练较大比例因子(例如8倍)的难度。此外,现有方法无法在多个分辨率下生成中间SR预测。这样,就需要针对具有不同期望的上采样比例和计算负载的应用来训练各种各样的模型。
为了解决这些缺点,我们提出了基于级联卷积神经网络(CNN)的拉普拉斯金字塔超分辨率网络(LapSRN)。我们的网络将LR图像作为输入,并以从粗糙到精细的方式逐步预测子带残差。在每个级别上,我们首先应用级联的卷积层来提取特征图。然后,我们使用转置卷积层将特征图上采样到更高的级别。最后,我们使用卷积层来预测子带残差(在各个级别上的上采样图像和真实HR图像之间的差异)。每个级别的预测残差用于通过上采样和加法运算有效地重建HR图像。虽然LapSRN由一组级联的子网组成,但我们以端到端的方式(即没有阶段优化)训练具有鲁棒 Charbonnier 损失函数的网络。如图一所示,我们的网络架构自然地可以进行深度监督(即可以在金字塔的每个级别上同时应用监督信号)

图片1:SRCNN [7],FSRCNN [8],VDSR [17],DRCN [18]和 LapSRN的网络体系结构。 红色箭头表示卷积层,蓝色箭头表示反卷积(上采样) 。绿色箭头表示逐元素假发运算符,橙色箭头表示递归层。
我们的方法在以下三个方面与现有的基于 CNN的方法不同:
(1) 准确度. 提出的LapSRN直接从LR图像提取特征图,并联合优化具有深卷积层的上采样过滤器,以预测子带残差。由于可以更好的处理离群值(outlier) 使用Charbonnier 损失的深度监督提高了性能。结果,我们的模型具有学习复杂映射的能力,并有效地减少了不必要的视觉伪像。
(2) 速度 我们的LapSRN包含快速处理速度和高容量的深度网络。实验结果表明,我们的方法比基于SCN的超分辨率模型更快,例如SRCNN [7],SCN [33],VDSR [17]和DRCN [18]。类似于FSR-CNN [8],我们的LapSRN在大多数评估数据集上均达到了实时速度。另外,我们的方法提供了明显更好的重建精度。
(3) 渐进式重建 我们的模型通过使用拉普拉斯金字塔进行渐进式重建,在一次前馈中生成多个中间SR预测。此特性使我们的技术适用于需要资源感知适应性的广泛应用。例如,取决于可用的计算资源,可以使用同一网络来增强视频的空间分辨率。对于计算资源有限的情景,我们的8x模型仍然可以通过在更精细的级别上简单地绕过残差的计算来执行2x或4xSR。但是,现有的基于CNN的方法不提供这种灵活性。
2、相关工作和问题
文献中已经提出了许多单图像超分辨率方法。在这里,我们将讨论重点放在最近的基于示例的方法上。
基于内部数据库的SR。 几种方法[9,12]充分利用了自然图像中的自相似性,并基于低分辨率输入图像的尺度空间金字塔构造了LR-HR补丁对。尽管内部数据库比外部图像数据库包含更多相关的训练补丁,但LR-HR补丁对的数量可能不足以覆盖图像中的较大纹理变化。辛格等。 [29]将补丁分解为定向频率子带,并独立地确定每个子带金字塔中的更好匹配。黄等。 [15]扩展了补丁搜索空间,以适应仿射变换和透视变形。基于内部数据库的SR方法的主要缺点是,由于尺度空间金字塔中补丁搜索的大量计算成本,它们通常速度较慢。
基于外部数据库的SR。 许多SR方法使用监督学习算法,使用从外部数据库收集的图像对来学习LR-HR映射,例如最近邻居[10],流形嵌入[2,5],核岭回归[19]和稀疏表示[37,38,39]。代替直接在整个数据库上建模复杂补丁空间的方法,几种方法通过K-means [36],稀疏算法[30]或随机森林[26]对图像数据库进行分区,并为每个群集学习局部线性回归。
基于卷积神经网络的SR。 与在补丁空间中建模LR-HR映射相反,SR-CNN [7]联合优化了所有步骤,并学习了图像空间中的非线性映射。通过将网络深度从3个卷积层增加到20个,VDSR网络[17]展示了对SRCNN [7]的显着改进。为了便于以更快的收敛速度训练更深的模型,VDSR训练网络以预测残差而不是实际像素值。Wang等。 [33]将稀疏编码的领域知识与adeep CNN相结合,并训练级联网络(SCN),以逐步将图像上采样至所需的比例因子。Kim等。 [18]提出了一个具有深度递归层(DRCN)的浅层网络,以减少参数的数量。
为了实现实时性能,ESPCN网络[28]提取了LR空间中的特征图,并通过有效的去卷积替换了双三次上采样操作。FSRCNN网络[8]采用了类似的思想,并使用了沙漏状的CNN,其层数比ESPCN少,但参数却少。以上所有基于CNN的SR方法都会通过具有 L2L_2L2? 损失函数来优化网络,这通常会导致结果过于平滑,并且与人类的感知能力不完全相关。在SR的背景下,我们证明了 L2L_2L2? 损失对于学习和预测稀疏残差的效率较低。
我们在图1中比较了SRCNN,FSR-CNN,VDSR,DRCN和LapSRN的网络结构,并在表1中列出了现有基于CNN的方法以及我们提出的框架之间的主要差异。我们的方法基于现有的基于CNN的SR算法,但存在三个主要区别。首先,我们通过卷积和转置卷积层共同学习残差和上采样滤波器。使用学习到的上采样滤波器不仅可以有效地抑制由双三次插值引起的重建伪像,而且可以大大降低计算复杂度。其次,我们使用鲁棒的Charbonnier损失函数代替 L2L_2L2? 损失来优化深层网络,以处理异常值 (outlier) 并提高重建精度。第三,由于LapSRN逐步重建HR图像,因此可以通过将网络截断到一定级别,将相同的模型用于需要不同比例因子的应用程序。

表1: 基于CNN的SR算法的比较:SRCNN [7],FSRCNN [8],SCN [33],ESPCN [28],VDSR [17]和LapSRN。层数包括卷积和转置卷积。直接重建的方法会执行从LR到HR图像的一步式上采样(双三次插值或转置卷积),而渐进式重建则可以分多个步骤预测HR图像。
拉普拉斯金字塔 拉普拉斯金字塔已被广泛使用,例如图像融合[4],纹理合成[14],边缘感知过滤[24]和语义分割[11,25]。登顿等。 在[6]中提出了一个基于拉普拉斯金字塔框架(LAP-GAN)的生成模型来生成逼真的图像,这与我们的工作最相关。但是,LapSRN在三个方面与LAPGAN不同。
首先,LAPGAN是一种生成模型,旨在从随机噪声和样本输入中合成出各种自然图像。相反,我们的LapSRN是一种超分辨率模型,可以根据给定的LR图像预测特定的HR图像。LAPGAN使用交叉熵损失函数来鼓励输出图像尊重训练数据集的数据分布。相比之下,我们使用Charbonnier 惩罚函数对预测与真实子带残差的偏差进行惩罚。
其次,LAPGAN的子网是独立的(即没有权重共享)。结果,网络容量受到每个子网深度的限制。与LAP-GAN不同,LapSRN中每个级别的卷积层都是通过多通道转置卷积层连接的。因此,较高层次的残差图像将由具有较低层次共享特征的更深层网络来预测。较低级别的特征共享增加了精细卷积层的非线性,以学习复杂的映射。而且,LAP-GAN中的子网是独立训练的。另一方面,LapSRN中用于特征提取,上采样和残差预测层的所有卷积滤波器都以端到端,深度监督的方式联合训练。
第三,LAPGAN在上采样的图像上应用卷积,因此速度取决于HR图像的大小。相反,我们的LapSRN设计通过从LR空间提取特征有效地增加了接收场的大小并加快了速度。我们在补充材料中提供与LAPGAN的比较。
对抗训练。 SRGAN方法[20]使用感知损失[16]和逼真的SR的对抗损失来优化网络。我们注意到,我们的LapSRN可以轻松扩展到对抗训练框架。由于这不是我们的贡献,因此我们对补充材料中的对抗损失进行了实验。
3、超分辨率的拉普拉斯金字塔网络
在本节中,我们将描述所提出的拉普拉斯金字塔网络的设计方法,使用具有强大监督功能的鲁棒损失函数进行优化以及网络训练的细节。
3.1 网络架构
我们提出了基于拉普拉斯金字塔框架构建我们的网络,如图1(e)所示。我们的模型将LR图像作为输入(而不是LR图像的放大版本),并逐步预测 log2Slog_2Slog2?S 级别的残差图像,其中S是比例因子。例如,该网络由3个子网组成,用于以8的比例因子超分辨率LR图像。我们的模型有两个分支:(1)特征提取和(2)图像重建。
特征提取 在级别s上,特征提取分支由d个卷积层和一个转置的卷积层组成,以将提取的特征上采样2级。每个转置的卷积层的输出连接到两个不同的层:(1)一个用于重构在s级别残差图像的卷积层,(2)一个用于提取 s+1 级以上特征的卷积层。请注意,我们以较粗略的分辨率执行特征提取,并以更精细的分辨率生成仅具有一个转置卷积层的特征图。与以高分辨率执行所有特征提取和重构的现有网络相比,我们的网络设计显着降低了计算复杂性。请注意,较低级别的特征表示与较高级别共享,因此可以增加网络的非线性,以便在更精细的级别学习复杂的映射。
图像重建 在级别s,输入图像通过转置的卷积(上采样)层以2的比例进行上采样。我们使用双线性内核初始化该层,并允许将其与所有其他层一起进行优化。然后将上采样的图像与特征提取分支中的预测残差图像合并(使用逐元素求和),以生成高分辨率的输出图像。然后将s级别HR输出图像馈送到级别s+1的图像重建分支中。整个网络是在每个级别具有类似结构的CNN的级联。
3.2 损失函数
设置 x 为输入的 LR 图像,θ\thetaθ 为网络可以优化的参数。我们的目标是学习一个映射函数 f ,该函数生成一个高分辨率的图像 y^=f(x;θ)\hat{y}=f(x;\theta)y^?=f(x;θ) ,这个高分辨图像与真实的高分辨率图像 y 接近。我们设在级别 s ,残差图像为 rsr_srs? 放大的LR图像为 xsx_sxs? 对应的HR图像为 ysy_sys? 。 期待HR输出图像表示为: ys=xs+rsy_s=x_s + r_sys?=xs?+rs? 。我们使用双三次下采样来调整每个级别真实HR图像y 到 ysy_sys?的大小。我们提出了一个鲁棒的损失函数来处理异常值(outlier) ,而不是最小化 ysy_sys? 和 ys^\hat{y_s}ys?^? 的MSE损失。全局的损失函数为:
L(y^,y;θ)=1N∑i=1N∑s=1Lρ(ys^(i)?ys(i))=1N∑i=1N∑s=1Lρ((ys^(i)?xs(i))?rs(i))(1)L(\hat{y},y;\theta)=\frac{1}{N}\sum_{i=1}^{N}\sum_{s=1}^L\rho(\hat{y_s}^{(i)}-y_s^{(i)})=\frac{1}{N}\sum_{i=1}^N\sum_{s=1}^L\rho((\hat{y_s}^{(i)}-x_s^{(i)})-r_s^{(i)}) \quad (1)L(y^?,y;θ)=N1?i=1∑N?s=1∑L?ρ(ys?^?(i)?ys(i)?)=N1?i=1∑N?s=1∑L?ρ((ys?^?(i)?xs(i)?)?rs(i)?)(1)
这里 ρ(x)=x2+ε22\rho(x)=\sqrt[2]{x^2+\varepsilon^2}ρ(x)=2x2+ε2? 是 Charbonnier 惩罚函数(一个可微的L1L_1L1?正则的变体)[3] ,N是批大小,L是金字塔的级别总数。我们实验设置 ε\varepsilonε 为 1e-3 。
在提出的LapSRN中,每个级别s都有其损失函数和相应的真实HR图像 ysy_sys?。 这种多损失的结构类似于用于分类[21]和边缘检测[34]的深层监督网。但是,[21,34]中用于监督中间层的标签在整个网络中是相同的。深度监督指导网络培训,以预测不同级别的子带残差图像并生成多尺度输出图像。例如,我们的8×模型可以在一次前馈过程中产生2×,4×和8×超分辨率结果。此属性对于资源感知应用程序(例如移动设备或网络应用程序)特别有用。
3.3 实现和训练细节
在提出的LapSRN中,每个卷积层包含64个3×3大小的滤波器。我们使用He等人的方法初始化卷积滤波器。 [13]。转置卷积滤波器的大小为4×4,权重从双线性滤波器初始化。所有卷积层和转置的卷积层(除其中的构造层外)都跟随有负斜率为0.2的LeakRelu。在应用卷积之前,我们在边界周围填充零,以使所有特征图的大小与每个级别的输入相同。卷积滤波器的空间支持较小(3×3)。但是,我们可以实现高非线性度并增加具有深结构的接收场的大小。
我们使用了Yang等人的91张图像。 [38]和来自伯克利细分数据集[1]的训练集的200张图像作为我们的训练数据。[17,26]中也使用了相同的训练数据集。在每个训练批次中,我们随机采样64个色块,大小为128×128。一个epoch具有1000次迭代的反向传播。我们通过三种方式扩充训练数据:(1) 缩放比例:在[0.5,1.0]之间随机缩小。(2)旋转:将图片随机旋转90o,180o90^o,180^o90o,180o 或 270o270^o270o。(3) 翻转,水平或垂直翻转图像,可能性均为0.5。遵循现有模型[7,17]的规则,我们使用双三次降采样生成LR训练补丁。我们用MatConvNet工具箱[31]训练模型。我们将动量参数设置为0.9,权重衰减设置为1e?4。所有层的学习率均初始化为1e-5,每50个epoch减少2倍。
4 实验结果
我们首先分析提出的网络的不同组件的贡献。然后,我们将Lap-SRN与五个基准数据集上的最新算法进行比较,并演示了我们的方法在超分辨率真实照片和视频上的应用。
4.1 模型分析
残差学习 为了证明残差学习的效果,我们删除了图像重建分支,并直接预测每个级别的HR图像。图2显示了针对4×SR的SET14上的PSNR收敛曲线。“非残差”网络(蓝色曲线)的性能收敛缓慢且波动很大。另一方面,建议的LapSRN(红色曲线)在10个周期内的表现优于SRCNN。

图片2 :金字塔结构,损失函数和残差学习的收敛性分析。我们的LapSRN收敛速度更快,并且可以提高性能。
损失函数 为了验证 charbonnier 损失函数的效果,我们使用 L2损失函数训练提出的网络。我们使用更大的学习率(1e?4),因为L2损失的梯度幅度较小。如图2所示,使用 L2损失优化的网络(绿色线) 需要更多的迭代才可以实现与SRCNN相当的性能。在图3(d)中,我们显示以 L2损失训练的网络会生成带有更多伪像的SR结果。相反,通过所提出的算法(图3(e))重建的SR图像包含相对干净和清晰的细节。

图片3:提议的网络中不同组件的贡献。 (a)HR图像。 (b)没有金字塔结构(c)没有残余学习(d)没有鲁棒损失(e)完整模型(f)真实情况。
金字塔结构 通过删除金字塔结构,我们的模型可以退回到类似于FSRCNN的网络,但具有残差学习能力。为了使用与LapSRN相同数量的卷积层,我们训练了一个具有10个卷积层和一个转置卷积层的网络。表2中的定量结果表明,金字塔结构导致适度的性能改进(例如,SET5为0.7dB,SET14为0.4dB)。
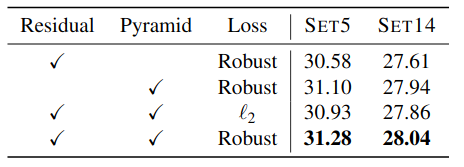
表2:金字塔结构,损失函数和残差学习的消融研究。我们用现有方法中使用的组件替换每个组件,并观察SET5和SET14的性能(PSNR)下降。
网络深度 我们在每个级别上用不同的深度d = 3,5,10,15训练提出的模型,并在表3中显示性能和速度之间的权衡。通常,深层网络性能更好,而浅层网络则以增加的计算成本为代价。我们为2×和4×SR模型选择= 10,以在性能和速度之间取得平衡。我们证明,深度d = 10的LapSRN 速度比大多数现有的基于CNN的SR算法要快(请参见图6)。对于8×模型,我们选择d= 5是因为我们没有通过使用更多的卷积层观察到显着的性能增益。
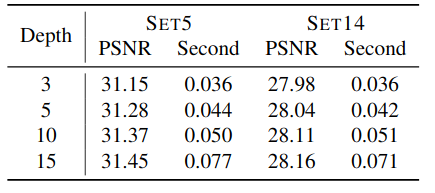
表3:在提议的网络的每个级别的深度上,都要在性能和速度之间进行权衡。

图6 : 速度和准确性之间的权衡。在SET14上以4倍比例因子评估结果。LapSRN可以高效,准确地生成SR图像。
4.2 与最新技术的比较
我们将提出的LapSRN与8种最新的SR算法进行了比较: A+ [30], SRCNN [7], FSRCNN [8],SelfExSR [15], RFL [26], SCN [33], VDSR [17] 和 DRCN [18]. 我们使用5个数据集进行了广泛的实验:SET5 [2],SET14 [39],BSDS100 [1],UR-BAN100 [15]和MANGA109 [23]。这些数据集之间,SET5,SET14和BSDS100包含自然场景;UR-BAN100包含具有挑战性的城市场景图像,其中包含不同频段的详细信息;MANGA109是日本漫画的数据集,我们训练LapSRN直到学习率降低到1e-6,并且在Titan X GPU上的训练时间约为三天。
我们用三种常用的图像质量指标评估SR图像:PSNR,SSIM [32]和IFC [27]。表4显示了2x,4x和8xSR的定量比较。我们的LapSRN与大多数数据集上的现有方法相比表现出色。特别是,我们的算法获得了更高的IFC值,这已被证明与人类对图像超分辨率的感知[35]有着很好的关联。我们注意到,通过使用特定比例因子(我们的 2x和 4x)进行训练可以达到最佳效果。由于训练了中间卷积层来最小化相应级别和更高级别的预测误差,因此我们的8x模型的中间预测稍逊于我们的2x和4x模型。但是,我们的8x模型在2x和4xSR方面提供了与最新方法相当的性能。
在图4中,我们显示了比例因子为4x的URBAN100,BSDS100和MANGA109的视觉比较。我们的方法可以准确地重建平行的直线和网格图案,例如窗户和条纹蛇形。我们观察到使用双三次上采样进行预处理的方法产生的结果具有明显的特征[7,17,26,30,33]。相比之下,我们的方法通过逐步重建和强大的损失函数有效地抑制了此类伪像。

图片4:BSDS100,URBAN100和MANGA109上4×SR的视觉比较。

表4:先进SR算法的定量评估:比例因子2x,4x和8x的平均PSNR / SSIM / IFC。红色表示最佳,蓝色表示次佳。
对于8×SR,我们使用公开代码重新训练A +,SRCNN,FS-RCNN,RFL和VDSR的模型,SelfExSR和SCN方法都可以使用渐进重建来处理不同的比例因子。我们在图5中显示了BSDS100和URBAN100的8×SR结果。对于8×SR,从双三次上采样的图像[7、17、30]或使用一步上采样[8]来预测HR图像具有挑战性。最先进的方法不能很好地超分辨精细结构。相反,LapSRN以相对较快的速度重建高质量的HR图像。我们介绍了由补充材料中所有评估方法生成的SR图像。

图片5:BSDS100和URBAN100上8×SR的视觉比较。
4.3 处理时间
我们使用最先进方法的原始代码来评估在配备3.4GHz Intel i7 CPU(64G RAM)和NVIDIA Titan X GPU(12G内存)的同一台计算机上的运行时间。由于SRCNN和FSRCNN的测试代码基于CPU实现,因此我们在MatConvNet中使用相同的网络权重重构这些模型,以测量GPU的运行时间。图6显示了SET14上4×SR的运行时间与性能(以PSNR表示)之间的权衡。我们班提出的LapSRN的速度比除FS-RCNN之外的所有现有方法都快。我们在补充材料中介绍了对所有评估数据集运行时间的详细评估。
4.4 超高分辨率的真实照片
我们演示了使用JPEG压缩伪像超分辨历史照片的应用。在这种情况下,真实图像和下采样内核均不可用。如图7所示,与最新方法相比,我们的方法可以重建更清晰,更准确的图像。

图片7: 4×SR与真实照片比较。我们注意到在这些情况下,真实HR图像和模糊内核不可用。在左图上,我们的方法精确地超分辨了字母“ W”,而VDSR错误地将笔画与字母“ O”连接起来。在正确的图像上,我们的方法重建了没有振铃伪影的轨道。
4.5 超分辨率视频序列
我们对[22]中的两个视频序列进行基于帧的SR实验,这些视频序列的空间分辨率为1200×800像素。我们将每个帧下采样8倍,然后分别对2倍,4倍和8倍逐帧应用超分辨率。由于我们从LR空间提取特征,因此计算成本取决于输入图像的大小。相反,SRCNN和VDSR的速度受到输出图像大小的限制。FSRCNN和我们的方法均在所有上采样比例下实现了实时性能(即每秒30帧以上)。相反,在8×SR上,SRCNN的FPS为8.43,VDSR的FPS为1.98。图8在一个代表帧上可视化了8×SR的结果。

图片8:在8×SR的空间分辨率为1200×800的视频帧上进行视觉比较。与现有方法相比,我们的方法可提供更干净,更清晰的结果。
4.6 局限性
尽管我们的模型能够以较大的比例(例如8倍)生成清晰,清晰的HR图像,但它无法“半透明”地显示细节。如图9所示,在8倍缩小的LR图像中,建筑物的顶部明显模糊。除SelfExSR [15]之外,所有SR算法都无法恢复精细的结构,SelfExSR [15]明确检测3D场景几何并使用自相似性使规则结构产生幻觉。这是参数SR方法共享的常见限制[7、8、17、18]。拟议网络的另一个限制是模型尺寸相对较大。为了减少参数的数量,可以用递归层替换每个级别的深度卷积层。

图片9:8×SR的故障案例。如果LR输入图像没有足够的结构量,我们的方法就无法产生幻觉。
5 结论
在这项工作中,我们提出了一个在拉普拉斯金字塔框架内的深度卷积网络,以实现快速准确的单图像超分辨率。我们的模型可以从粗到精的方式逐步预测高频残差。通过用学习的转置卷积层替换预定义的三次三次插值并使用健壮的损失函数优化网络,LapSRN缓解了带有不希望的伪影的问题并降低了计算复杂性。在基准数据集上进行的广泛评估表明,在视觉质量和运行时间方面,所提出的模型与最新的SR算法相比具有良好的性能。
参考文献
