����Ŀ¼
- ǰ��
- Abstract��ժҪ��
- Introduction�����ԣ�
- General Design Principles��ͨ�����ԭ��
-
- ԭ��һ
- ԭ���
- ԭ����
- ԭ����
- Factorizing Convolutions with Large Filter Size���ֽ������� ��
-
- �ֽⷽ��һ��
- �ֽⷽ������
- Utility of Auxiliary Classifiers��������������
- Efficient Grid Size Reduction(��Сfeature map�ߴ�)
- Inception-v2
- Model Regularization via Label Smoothing��LSR��
- Performance on Lower Resolution Input��С�ֱ����������ܣ�
- Experimental Results and Comparisons��inceptionV3��¯��
- С�ܽ�
inceptionϵ�У�
- inceptionV1 & GoogleNet ����
- inceptionV2 & BN ����
- inceptionV3 ����
- inceptionV4 ����
- xception ����
ǰ��
���쿴һ��inception-V3�����������½�Ŀ¼��ʼ~
������Ŀ��Rethinking the Inception Architecture for Computer Vision
���ĵ�ַ:https://arxiv.org/pdf/1512.00567.pdf
֮ǰ�����汾:
- InceptionV1 ����
- InceptionV2 & BN ����
ǿ�ҽ��鰴˳����������ƪ����֮ǰ�ȿ�V1��V2��
��ƪ����ʵ����Ӧ����inceptionV3�� inceptionV2�� BN����һƪ���������Ҳ����ϵ�ʱ��Ҳ�м�������˵inceptionV2��V3������һƪ���ģ�����û�£�google����ƪ���Ķ���ţ�������Ǹ���V2���������ˡ�
Abstract��ժҪ��
������ժҪ�����ᵽ��2014����������翪ʼ�����ִ�������ﲻ���ǰ�ʾ2014���imagenet�������Ǿ� VGG���Լ��ҵ�googleV1����������Ȼ����VGG����� ˭����VGG�����ӣ�����̲�VGGʵ���ˡ�
�ᵽ�˿����������ʹ�㣬���㸴�Ӷȸߣ������ƶ�����(��Ե����)�ʹ����ݳ�����ʹ�á�
֮��˵����ƪ���ĵ���ּ:ͨ���ֽ����+���������Ч��
Introduction�����ԣ�
��һ��һ�仰�ܽ�: ����ģ�Ϳ���Ӧ���ڸ�������
�ڶ���һ�仰�ܽ�: �õ�ѧϰģ����������������Ǩ��ѧϰ�����ߵõ�һ�������������ѧϰ��Ŀ�����е���ȡ��ѡ������
������һ�仰�ܽ�ڲ����϶Ա�����ģ��չ��googlenet������(������-Alexnet��6000W��Googlenet��500W��VGG16��1.3E)
���Ķ�һ�仰�ܽģ�ͼ�������PRelu�ͣ��������ƶ��豸�ʹ����ݳ�����ʹ�ã��Ҹ��ּ����Ż���������������inception�ϣ��Ͼ�inceptionģ���������һ�ѵľ����ͳػ�����
���һ��һ�仰�ܽһζ�Ķѵ�inceptionģ�齫ʹ�ü�������ը�������ľ��Ȳ������㣬ͬʱ˵��һ���Լ��ҵ�V1�汾û��˵�����ȷ�ʵľ���ԭ�����ԡ����ѧϰ=����¯ ��ѧ��~
General Design Principles��ͨ�����ԭ��
��һ����Ҫ�ǽ����������뵽���������ԭ��ͷ��ʱ������Ҳ˵�ˣ��⼸�����ԭ����Ҫ���������أ���Ȼû���ϸ��֤������ʵ��ӳ֣����ǿ��Ա������ǣ�����㱳���⼸��ԭ��̫�࣬���Ȼ����ɽϲ��ʵ��������˳���߲�������������
ԭ��һ
������ȵĽ�ά������������ ����������dz�㡣
- ǰ�������൱��һ��������ͼ�ṹ��
- feature map ������СӦ������������С�������ͼ�����
- ���ȵĽ�ά�����������������һ���̶ȵ���Ϣ��ʧ����Ϣ����Զ�ʧ����
ԭ���
����Խ�࣬����Խ�졣
- �����������Խ�࣬������Ϣ�ֽ��Խ���ס�
- ����inceptionV1��˵���Ǹ��ղ����ۡ�
ԭ����
3 * 3��5 * 5�ľ����˾���֮ǰ������1 * 1 �ľ����˽�ά����Ϣ���ᶪʧ��
- ��ͷ�ĵ��� Spatial aggregation���ռ�ۼ���Ҳ�����ô�ĸ���Ұ���ܸ������Ϣ���ۼ���һ�𣬼�ʹ�ô�ߴ�ľ����ˡ�
- ʹ��1 * 1 �������Խ���ά�ȣ����ͼ�����������ѵ����
- inceptionV1��ʹ�õ�ģ������ 3 * 3 �� 5 * 5�ľ���������������֮ǰ��ʹ��1 * 1 �ľ����������Ľ�ά���������ڽ���Ԫ��ǿ���������ʧ��������Ϣ���١�
ԭ����
���������е���ȺͿ��ȡ�
- ��Ⱦ���ָ�����Ķ��٣�����ָÿһ���о����˵ĸ�����Ҳ������ȡ������������
- ����ȺͿ��Ȳ����������ɱ�������������������ܺͼ���Ч�ʡ�
- �����ü�������ÿһ���Ͼ��ȷ��䣬VGG�ǵ�һ��ȫ���Ӳ�����ݶѻ������ڲ����ȷ���������
Factorizing Convolutions with Large Filter Size���ֽ������� ��
֮ǰ��Googlenet�����Ѿ�������inceptionģ��ʹ��1 * 1 �ľ������ˡ�����Ҳ�������ᵽGooglenet��inception�ɹ�ԭ��ֵ�����ʹ��1 * 1 �ľ����ˣ�1 * 1 �����˿��Կ���һ������Ĵ�����˷ֽ���̣������������˼�������������������ı���������
�������ԭ����Ҳ֪���ˣ���ʹ�ô������֮ǰ����1 * 1�����ˣ�feature map��Ϣ���ᶪʧ�ܶ࣬��Ϊ����Ұ���ڵ�Ԫ������Ժ�ǿ�������ھ����Ĺ������غ϶Ⱥܸߣ������һ������������feature map�����ϲ��ᶪʧ������Ϣ(Ԫ����������Բ���)��
inceptionģ��Ϊȫ��������(�����гػ��㣬��û��ȫ���Ӳ�)������Ȩ�ظ���Խ�࣬������Խ�����Ծ� -ʹ��С�����˨C��ά�C���������٨C��������С�C��Լ�ڴ�C����ѵ���C��ʡ���������ڼ������ľ������顣��
�ֽⷽ��һ��
��˵һ�������е���ҳ��ͷ����������ͼ��

��ͼ��֮ǰ���ĸ�����˵���ö���ˣ���ʵ���ǽ��������С����������Ĺ��̡�
�������ԭͼ5 * 5 ʹ�� 5 * 5�ľ�����ȥ����(�൱��һ��ȫ����)��ֻ�ܵõ�һ��1 * 1��feature map�����������ͼ��ԭͼΪ5 * 5 ����ʹ��3 * 3 �Ⱦ���һ��(����Ϊ1)���õ�һ�� 3 * 3 ��feature map,Ȼ����ʹ��һ��3 * 3 �ľ����˶ԸղŻ�õ�feature map���о�������ͬ���õ���һ��1 * 1��feature map��
5 * 5 �����ֽ������ 3 * 3�����ˡ�ͬ��7 * 7�ֽ������ 3 * 3�����ˡ�
������3.1С�����ᵽ:��ͬ�����˸�����feature map�ߴ������£�5 * 5 �����˱�3 * 3�����˼���������2.78����
���ڸ���Ұ��Ȩֵ���������������ˣ����������ڵ���ֵ����һ���ģ���ͬһ�������ˣ������Լ����˺ܶ��������
�ٸ�����
��5 * 5�ľ������У� ��H* W C�� (5 * 5 * C) = 25 HWC2HWC^2HWC2
��3 * 3�ľ������У� 2 * ��H* W C�� (3 * 3 * C) = 18 HWC2HWC^2HWC2
�ɴ����ߵõ��� 28%�IJ��������١�
���ڷֽ��ļ����������ͨ��ʵ��֤������������ԭͼ�ĵ�һ��3 * 3�����ļ�����нϺ�Ч����һ�������������ˣ������˷����Ա任����ǿģ�ͷ����Ա�������������BN��Ч�����á�
1 * 1�������Relu������Ч����(�Ͼ�1 * 1 ����Ҳ��һ��������)��
ԭ��GoogleNet���inceptionV1�ṹ:

�Ľ�֮���inception�ṹ:

�ֽⷽ������
�����һ�������� 5 * 5�ֽ���� ����3* 3������
3.2��һС�ڷ����ǣ���3*3�ľ����ֽ�� 1 * 3�� 3 * 1���������Գƾ���(�ռ�ɷ������)��
����������������и�����ͼ:

����һ�������ͼ������ԭʼΪ3 * 3��ͼ��ʹ��3 * 1�ľ�����ȥ�������õ�һ��feature map��Ȼ������ 1* 3 �ľ����˶Ըղŵõ���feature map�������õ�1 * 1��feature map��
ʵ��������ֱ�����ߴ���ľ���˷��������⣬��������������ͼ��
����3 * 3����ķֽ⣺�ֽ�� 3 * 1 ��1 * 3��������
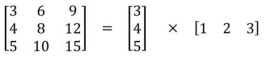
ʵ�����ڵ���֮ǰ�Ҿ����룬Ϊɶ�������ֽ�3 * 3������ɸ�С�ģ�����5 * 5 �ֽ������ 3 * 3������3 * 3Ҳ���Էֽ������2 * 2������Ϊɶ��ҪŪ������ 3* 1 ��1 * 3�IJ��Գƾ�����
�����ں��������ԭ��ͨ��ʵ����㣬��3 * 3 �ֽ������2 * 2���Լ���11%�IJ����������ֽ��3 *1 ��1 * 3 ���Լ���33%�IJ����������������5 * 5 �ֽ�Ҳ����ʹ�÷ǶԳƷֽ�ඣ�����
����С���ۣ�
- ���ַֽ� (n *n �ֽ���� n * 1 ��1 * n) n Խ���ʡ��������Խ��
- ���ַֽ���ǰ��IJ�Ч�����ã�ʹ��feature map��С��12-20֮�䡣
��3 * 3�ò��ԳƷֽ�֮��Ľṹ�������������

����һ�����֣�������������������������Ϸֽ⣬������������ڿ����Ϸֽ⡣
Ӧ����������������֮ǰ���ø�ģ����չ����ά�����ɸ�άϡ��������������������������ԭ�������

Utility of Auxiliary Classifiers��������������
���Ȼع�һ����GooglenetV1����ĸ�����������

�������������ĸ�������������dz���ʱ��ֱ�����һ����������Ϊ������dz��ʹ����������������(��dz��ѧ�������Ե�����)��������������ֹ�ݶ���ʧ������������һ����dz��һ�����в㣬���ս��:L=L�����+0.3xL����1��+0.3xL����2�������Խ�ȥ��������������
Ȼ������ƪ�����У���һ������ֱ��˵�� ������������û�м����������������ʾ�����и��������������羫��ȷʵ��û�и����������ĸߣ�ֻ��һ�㣬�Ƴ���dz��ķ�����������û��ʲô̫���Ӱ�졣
Efficient Grid Size Reduction(��Сfeature map�ߴ�)
����������Ҫ�����˸���Ч���²���������
��ͳ�����ַ�����Сfeature map�ķ���:�ȳػ�����ά����ʧ�˹�����Ϣ������ά�ٳػ�������������Ӷȱ��
Ϊ�˽����������⣬�����inception�IJ���ģ�顣
inception����ģ��ṹͼ:
�����·�������ұ߳ػ�������ٵ��ӣ������ڲ���ʧ��Ϣ������¼�С��������

Inception-v2
���ڿ�ͷ��ʱ��˵������ƪ����Ӧ����inceptionV3��V2��BN��һƪ������д��ƪ���ĵ�ʱ�����߾��ǰ����г�V2�ˣ�������һ������������ô�����⡣
��һ����Ҫ���ǻ������������еĸĽ�����ģ�顣
��һ�����߸��������磺
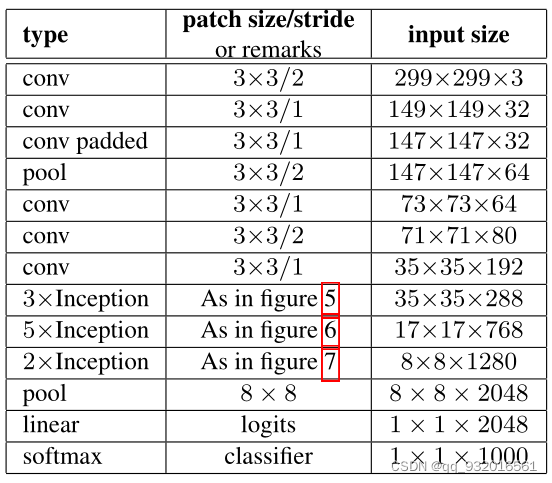
�������
- figure 5 ------ 5 * 5 �����ֽ������3 * 3 ����
- figure 6------ Ӧ�õ��Ǹ����Գƾ���
- figure 7------ �����������ǰ���Ǹ���չ���
����˵��������Ƿ�������˵����Ƶ��Ĵ�ԭ��ģ� ������42�����������googlenet��2.5��(�Ա�VGG��Ч)��
Model Regularization via Label Smoothing��LSR��
���������������һ�������� LSR���ҳ��Կ���һ����һ�£��κ�ˮƽ������ֻ�ܴӱ�������û������ԭ����
Label Smoothing Regularization��LSR����ǩƽ������,����ѧϰ�е�һ������������һ��ͨ�������y������������ʵ�ֶ�ģ�ͽ���Լ��������ģ����ϣ�overfitting���̶ȵ�һ��Լ��������regularization methed����
Performance on Lower Resolution Input��С�ֱ����������ܣ�
��������Ҫ������һЩѵ��ϸ�ڣ��Ͳ�˵�ˡ�
�ھ�������˼����һ��ģ����С�ֱ���ͼ�������ʱ������ܡ�
����˵��һ��ģ���ڴ�ֱ���ͼ�������¸���Ч��ԭ��һ����dz��ĸ���Ұ����Ϊ����ֱ��ʴ����Ծ����˴�
�ڶ���ԭ����ģ�͵���ȴ�
Ȼ�����߱���ģ���ӶȲ��䣨��С�ֱ���ͼ���Сǰ����IJ����������Ƴ���һ���ػ��㣩����������������ͼ��ֱ�����ʵ��õ����:
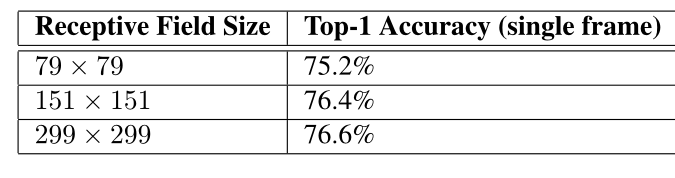
���Կ������ֱ������֮����ȷ��ȷʵ����ˣ�������ߵ��������������������ƽ���Ҳ��ܸ�������ķֱ��ʱ�С����������Ĵ�С��������������ܻ��úܲ
Experimental Results and Comparisons��inceptionV3��¯��
inceptionV3��¯����ֱ�ӿ�����ͼ:

�������½�������ĵ�inceptionV2�ṹ��ʼ�Ľ�:
- inceptionV2 ����RMSProp(һ�ּ����ݶȵķ���,��ϸԭ��)
- ������Ļ����ϼ���Label Smoothing(LSR,��ǩƽ������)
- ������Ļ������ټ��� 7 * 7�ľ����˷ֽ�(�ֽ��3 * 3)
- ������Ļ������ټ��뺬��BN�ĸ���������
���Ա������������inceptionV3 = inceptionV2+RMSProp+LSR+BN-aux
����˵��inceptionV2�DZ������е�inceptionV2������BN��һƪ��
С�ܽ�
- �Ĵ����ԭ��
- ��dz�㲻Ҫ���Ƚ�ά����������
- ����Խ�࣬����Խ�졣
- �������֮ǰ��1 * 1������ά����Ϣ����ʧ
- ���������е���ȺͿ���
- ���Գƾ����˷ֽ�
- ֱ�Ӵ���V1�еĸ������������������µĴ�BN�ĸ���������
- ʹ���µ� inception����ģ�����˴�ͳ�����������
- inceptionV3 = inceptionV2+RMSProp+LSR+BN-aux