PyTorch Metric Learning�����ѧϰ�� Inference
- Install the packages
- Import the packages
- Create helper functions
- Create the dataset and load the trained model
- Create the InferenceModel wrapper
- Get nearest neighbors of a query ���Լ�����
- Compare two images of the same class ���Լ�����
- Compare two images of different classes ���Լ�����
- Get nearest neighbors of a query ���Լ�Ԥ��
����ѧϰ��Ϊһ�������������в��ٽ��ܵ����£�pytorch-metric-learning��Ĺٷ��ĵ�Ҳ�бȽ���ϸ��˵����demo. ������ѧϰ��pytorch-metric-learning��ʹ��
�ٷ� API �� PyTorch Metric Learning
�����ѧϰ���棬ʹ��ѧϰ�õ�ģ����Ԥ��Ĺ��̽�inference������龰�º�predict����һ����˼��
�ٷ��������ӣ�Inference
Install the packages
!pip install pytorch-metric-learning
!pip install -q faiss-gpu
!git clone https://github.com/akamaster/pytorch_resnet_cifar10
Import the packages
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
from pytorch_resnet_cifar10 import resnet
from torchvision import datasets, transformsfrom pytorch_metric_learning.distances import CosineSimilarity
from pytorch_metric_learning.utils import common_functions as c_f
from pytorch_metric_learning.utils.inference import InferenceModel, MatchFinder
Create helper functions
def print_decision(is_match):if is_match:print("Same class")else:print("Different class")mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]inv_normalize = transforms.Normalize(mean=[-m / s for m, s in zip(mean, std)], std=[1 / s for s in std]
) # normalisation��任def imshow(img, figsize=(8, 4)):img = inv_normalize(img)npimg = img.numpy()plt.figure(figsize=figsize)plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()
Create the dataset and load the trained model
����CIFAR10���ݼ��IJ��Լ���10000��ͼƬ
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)]
)dataset = datasets.CIFAR10(root="CIFAR10_Dataset", train=False, transform=transform, download=True
)
print(len(dataset.targets)) # 10000�����Լ�
labels_to_indices = c_f.get_labels_to_indices(dataset.targets)
����c_f.get_labels_to_indices�����е�label�������������ֵ��С����ӣ�

����ģ�ͣ�ȥ��ģ�����ķ����. �����ģ���DZ���ѵ���õģ�����ֱ��������������ѧϰ��embedding. ������ʹ��ʱӦ�ü��������Լ���trunkģ�ͣ�����Ҫ�ٸ����һ��.
labels_to_indices = c_f.get_labels_to_indices(dataset.targets)
model = torch.nn.DataParallel(resnet.resnet20())
checkpoint = torch.load("pytorch_resnet_cifar10/pretrained_models/resnet20-12fca82f.th")
model.load_state_dict(checkpoint["state_dict"])
model.module.linear = c_f.Identity()
model.to(torch.device("cuda"))
print("done model loading")
Create the InferenceModel wrapper
��һ���ǹؼ���utils.inference ����������Է�������������л��һ����в���ƥ��ԡ�
����һ�¶���ѧϰ�Ĵ������̣���ʹ�����ѧϰ���統�����ǵ�embedding����, Ҳ��������trunk�����ﻹ������д����һ���ǽ����һ��ķ������ֱ�Ӹ�Ϊembedding����������ʧ������ʹ�ø��ֶ���ѧϰ��loss����һ����ֱ�Ӱ����һ���Ϊembedding�㣨trunk����+Ƕ����������һ�ַ��������ӽ��鿴�ҵ�PyTorch Metric Learning�����ѧϰһ���ڶ���д�����鿴Kaggle�ľ�����ࡣ
Ȼ����������Ԥ��ʱ��ʹ��������ҳ�ÿ�����Լ���������ѵ��������ĵ㣬��������label��������Ԥ�������label��
from pytorch_metric_learning.utils.inference import InferenceModel
InferenceModel(trunk,embedder=None,match_finder=None,normalize_embeddings=True,knn_func=None,data_device=None,dtype=None)

�������ǵ���������������������ǵ�һ��д����ֻ������û��Ƕ������
match_finder = MatchFinder(distance=CosineSimilarity(), threshold=0.7)
inference_model = InferenceModel(model, match_finder=match_finder)# cars 1 and frogs 6
classA, classB = labels_to_indices[1], labels_to_indices[6]
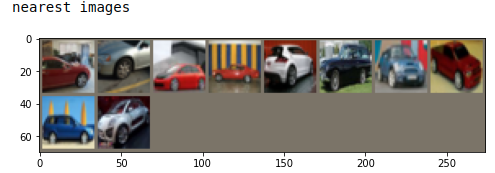
Get nearest neighbors of a query ���Լ�����
# pass in a dataset to serve as the search space for k-nn
inference_model.train_knn(dataset)
# get 10 nearest neighbors for a car image
for img_type in [classA, classB]:img = dataset[img_type[0]][0].unsqueeze(0)print("query image")imshow(torchvision.utils.make_grid(img))distances, indices = inference_model.get_nearest_neighbors(img, k=10)nearest_imgs = [dataset[i][0] for i in indices.cpu()[0]]print("nearest images")imshow(torchvision.utils.make_grid(nearest_imgs))

Compare two images of the same class ���Լ�����
# compare two images of the same class
(x, _), (y, _) = dataset[classA[0]], dataset[classA[1]]
imshow(torchvision.utils.make_grid(torch.stack([x, y], dim=0)))
decision = inference_model.is_match(x.unsqueeze(0), y.unsqueeze(0))
print_decision(decision)
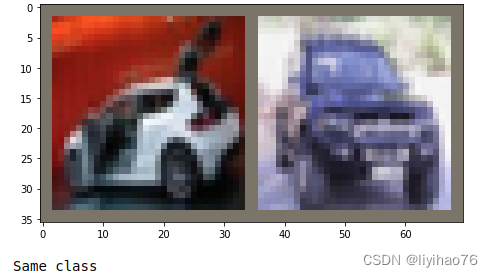
Compare two images of different classes ���Լ�����
# compare two images of a different class
(x, _), (y, _) = dataset[classA[0]], dataset[classB[0]]
imshow(torchvision.utils.make_grid(torch.stack([x, y], dim=0)))
decision = inference_model.is_match(x.unsqueeze(0), y.unsqueeze(0))
print_decision(decision)

Get nearest neighbors of a query ���Լ�Ԥ��
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)]
)train_dataset = datasets.CIFAR10(root="CIFAR10_Dataset", train=True, transform=transform, download=True
)
test_dataset = datasets.CIFAR10(root="CIFAR10_Dataset", train=False, transform=transform, download=True
)labels_to_indices = c_f.get_labels_to_indices(test_dataset.targets)
model = torch.nn.DataParallel(resnet.resnet20())
checkpoint = torch.load("pytorch_resnet_cifar10/pretrained_models/resnet20-12fca82f.th")
model.load_state_dict(checkpoint["state_dict"])
model.module.linear = c_f.Identity()
model.to(torch.device("cuda"))
print("done model loading")match_finder = MatchFinder(distance=CosineSimilarity(), threshold=0.7)
inference_model = InferenceModel(model, match_finder=match_finder)# cars and frogs
classA, classB = labels_to_indices[1], labels_to_indices[6]
# pass in a dataset to serve as the search space for k-nn
inference_model.train_knn(train_dataset)img = test_dataset[classA[0]][0].unsqueeze(0)
print("query image")
imshow(torchvision.utils.make_grid(img))distances, indices = inference_model.get_nearest_neighbors(img, k=10)print(distances) #tensor([[0.0468, 0.0584, 0.0600, 0.0613, 0.0621, 0.0630, 0.0632, 0.0644, 0.0657,0.0676]], device='cuda:0')
print(indices) #tensor([[26404, 27238, 38183, 36848, 19181, 7221, 49221, 36721, 10748, 8571]],device='cuda:0')nearest_imgs = [train_dataset[i][0] for i in indices.cpu()[0]]
print("nearest images")
imshow(torchvision.utils.make_grid(nearest_imgs))