最近在关注数据相关的工作!主动学习是数据领域中一个方向,它的目的是用最少的标注样本实现最好的模型预测效果,能够减少人工标注的成本。本文将介绍《Learning loss for active learning 》一些基本的思想,不到之处还请指正!
这篇文章提出根据损失来选取前K个最有价值的数据(即损失最大的K个数据),将这K个数据由专家标注,放入有标签的训练集中,依次迭代多次直到模型达到预期的效果。本文最主要的思想是在目标网络上添加损失预测模块,它能预测模型的损失值。模型结构如下图所示:

a图就是模型的整体框架,由于损失预测模块与任务无关只与模型的损失有关。因此,这种方法可以应用到其他不同的任务中(比如训练时是分割任务得到的损失预测模型可应用于分类任务)当然这个过程必须保持模型不变。

GAP是指全局平均池化,训练过程就是联合优化目标模型与损失预测模型的损失函数。这里比较重要的一点就是损失预测模型的损失函数的设计,最直接的想法就是考虑损失预测模型的预测值与实际损失值之间的均方误差。这种做法显然是不合理的,因为迭代过程中的损失值是一个变化的过程,这就会导致损失预测模型的训练过程中对应的数据的标签不一致!导致预测效果很差。因此作者就提出数据对的思想来确定损失预测模型的损失函数。
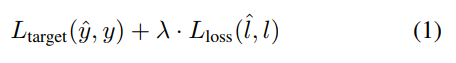
公式1为整个模型的损失函数为尺度常量,前面的是目标模型的损失函数(比如分类的交叉熵损失函数等),后面部分就是损失预测模型的损失函数。本文中用B表示最小的训练batch_size,它是一个偶数那么就能够组成B/2的数据对。那么就用公式2来度量
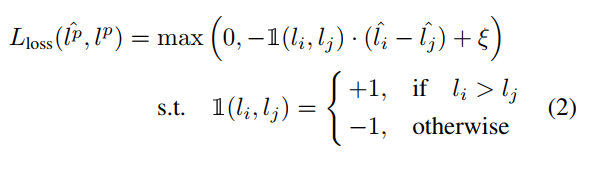
这个函数我们分析一下考虑第一种情况且模型预测的结果也满足
那么损失值加上一个ξ后小于0,那么loss取0说明模型的预测关系是对的,不进行权重更新。如果
但模型的预测的结果
.则损失函数值大于0进行权重更新。这个损失函数则说明损失预测模型的实际目的是得到对应数据的损失值的大小关系而不是确定的损失值。那么整个损失函数定义为公式3

接下来看看这种主动学习的提升效果包括分类,目标检测和人体姿态估计:

这里是在分类任务上的效果可以看出数据量较少的情况下,本文算法具有明显的优势,但是增长到10K以后本文算法的优势就不明显了。


从图6看出目标检测任务中本文算法的效果在小样本的情况下不如core-set的方法达到5k以后数据的超越了core-set 的方法。

图7的结果与图6类似,这里我猜想可能是训练样本很少的情况下,本文提出的损失预测模块的效果可能较差,导致预测的结果较差(如果损失预测模块是在其它任务上训练好的,且结果与图6与7一致那么就不是我猜想的原因)

通过比较预测的损失和真实的损失之间的相关性来说明方法的优越性,这点比较有意思!