一、无监督学习
无监督学习是机器学习中的一种训练方式或者学习方式。
人工智能中机器学习有3中不同的训练方法,分别是监督学习、非监督学习、强化学习。
下面跟监督学习的对比来学习无监督学习。
- 监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
- 监督学习需要给数据打标签;而无监督学习不需要给数据打标签。
- 监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
简单总结一下:
无监督学习是一种机器学习的训练方式,它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。
它主要是具备3个特点:
- 无监督学习没有明确的目的
- 无监督学习不需要给数据打标签
- 无监督学习无法量化效果
下面用一些具体案例来告诉大家无监督学习的一些实际应用场景,通过这些实际场景,大家就能了解无监督学习的价值。
案例一:借助无监督学习发现异常数据
有很多违法行为都需要”洗钱”,这些洗钱行为跟普通用户的行为是不一样的,到底哪里不一样?
如果通过人为去分析是一件成本很高很复杂的事情,我们可以通过这些行为的特征对用户进行分类,就更容易找到那些行为异常的用户,然后再深入分析他们的行为到底哪里不一样,是否属于违法洗钱的范畴。
通过无监督学习,我们可以快速把行为进行分类,虽然我们不知道这些分类意味着什么,但是通过这种分类,可以快速排出正常的用户,更有针对性的对异常行为进行深入分析。
案例二:借助无监督学习细分用户
这个对于广告平台很有意义,我们不仅把用户按照性别、年龄、地理位置等维度进行用户细分,还可以通过用户行为对用户进行分类。
通过很多维度的用户细分,广告投放可以更有针对性,效果也会更好
案例三:借助无监督学习给用户做推荐
大家都听过”啤酒+尿不湿”的故事,这个故事就是根据用户的购买行为来推荐相关的商品的一个例子。
比如大家在淘宝、天猫、京东上逛的时候,总会根据你的浏览行为推荐一些相关的商品,有些商品就是无监督学习通过聚类来推荐出来的。系统会发现一些购买行为相似的用户,推荐这类用户最”喜欢”的商品。
最常见的两类无监督学习算法包括 聚类 和 降维
二、聚类(Clustering)
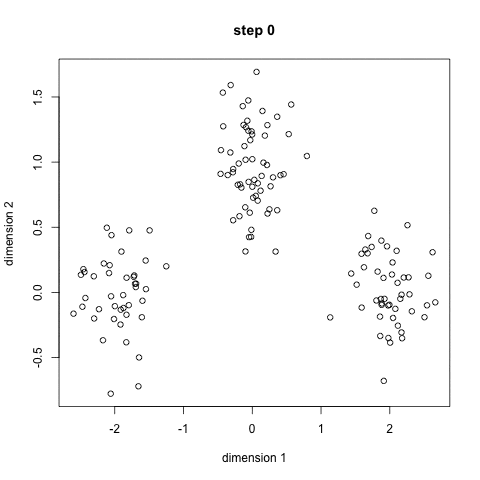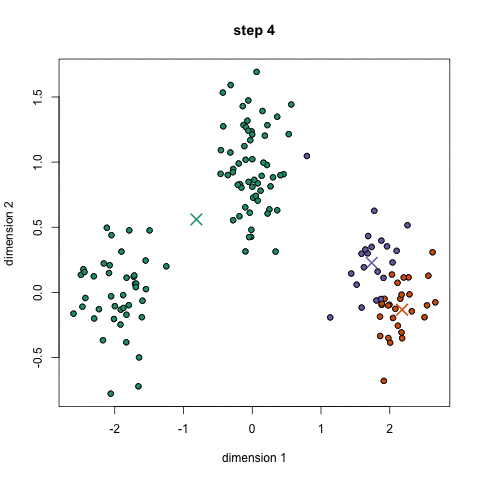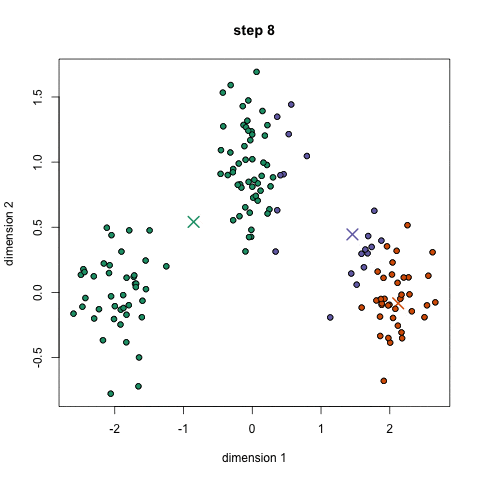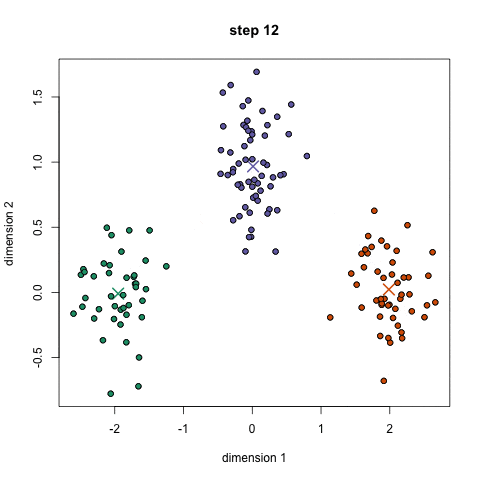
聚类算法中的 K - 均值算法(K-Means Algorithm )时最普及的聚类算法,算法接受一个未被标记的数据集,然后将数据类聚成不同的组。
K-均值是一个迭代算法,假设我们想要将数据聚类成 n 个组,其方法为:
- 定义 K 个重心。一开始这些重心是随机的(也有一些更加有效的用于初始化重心的算法)
- 寻找最近的重心并且更新聚类分配。将每个数据点都分配给这 K 个聚类中的一个。每个数据点都被分配给离它们最近的重心的聚类。这里的「接近程度」的度量是一个超参数――通常是欧几里得距离(Euclidean distance)。
- 将重心移动到它们的聚类的中心。每个聚类的重心的新位置是通过计算该聚类中所有数据点的平均位置得到的。
重复第 2 和 3 步,直到每次迭代时重心的位置不再显著变化(即直到该算法收敛)。
其过程如下面的动图:
1、K-Means的优化目标
在大多数我们已经学到的 监督学习算法中。 算法都有一个优化目标函数(代价函数),需要通过算法进行最小化 。
K均值的优化目标为:

从公式上不难理解,k均值的优化目标就是让每一个样本点找到最优的聚类中心。
找出使得代价函数最小的,
,...,
和
、
、......、
,即:

2、随机初始化
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点:
- 我们应该选择
,即聚类中心点的个数要小于所有训练集实例的数量;
- 随机选择
个样本点作为初始聚类中心。
K-均值的一个问题在于,不同的初始化位置会有不同的聚类结果,而且结果有可能会停留在一个局部最小值处,而这取决于初始化的情况。如下图三种随机初始化:

解决方法是多次初始化聚类中心,然后计算K-Means的代价函数,根据代价函数的大小选择最优解。

这种方法在较小的时候还是可行的,但是如果较大,这么做也可能不会有明显地改善。
3、选择聚类数
了解了算法原理后,面对实际问题时,我们怎么决定聚类数呢?
当人们在讨论,选择聚类数目的方法时,有一个会被谈及的方法叫做“肘部法则”。
效果较差的 ―― “ 肘部法则 ”
改变 K 值,获得不同 K值和代价函数最小值的关系曲线:
- 理想情况下我们可能会得到左下图中类似 “肘部” 的额曲线,该处的 K 值即为最佳聚类数。
- 但是实际情况却是像由下图那样,曲线较为平滑,无法判断哪里是 “肘部

因此,没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题需求,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
例如,我们的 T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成3个尺寸:S,M,L,也可以分成5个尺寸:XS,S,M,L,XL,这样的选择是建立在回答“聚类后我们制造的T-恤是否能较好地适合我们的客户”这个问题的基础上作出的。
三、降维(Dimensionality reduction)
简言之,降维就是降低特征的维数,例如每个样本点有1000个特征,通过降维,可以用100个特征来替代原来的1000个特征。
降维的好处在于:
- Data compression 数据压缩,可以提高运算速度和减少存储空间。
- Data Visualization 数据可视化,得到更直观的视图
如下图是一个将 3 维特征转换为 2 维特征的例子
1、主成分分析问题
主成分分析(PCA)是最常见的降维方法。
PCA是寻找到一个 低维的空间 对数据进行 投影 ,以便 最小化投影误差的平方( 最小化每个点 与投影后的对应点之间的距离的平方值 ),例如:
- 2维→1维:点到直线的垂直距离
- 3维→2维:点到平面的垂直距离

如上图所示,低维空间是由其中的特征向量 来确定的,因此PCA算法的核心就是寻找 低维空间的特征向量。
下面给出主成分分析问题的描述:
问题主要是将n维数据降至K维,目标是找到向量 使得总的投射误差最小。
下面给出主成分分析与线性回归的比较:
线性回归(Linear Regression,LR)与 2维PCA的区别:虽然都是找一条直线去拟合,但是计算 loss (损失/代价函数)的方式不同。
- PCA计算的是投影误差(垂直距离),而LR计算的是预测值与实际值的误差(竖直距离);
- PCA中只有特征没有标签数据y(非监督学习),LR中既有特征样本也有标签数据(监督学习)。

2、主成分分析算法
利用 PCA 将 n维 降到 k维 的步骤:
1、特征缩放(均值归一化),使得特征的数值在可比较的范围之内。
2、计算协方差矩阵(covariance matrix),用 Σ 表示(大写的Sigma,不是求和符号):

3、利用奇异值分解(SVD)来分解协方差矩阵,得到的特征向量 是一个具有与数据之间最小投射误差的方向向量构成的矩阵

4、取出 的前
个向量作为降维后的特征矩阵
,将原始样
转化为新的特征向量下的新样本点

3、 PCA反向压缩――原始数据重现
既然PCA可以将高维数据压缩到低维,那么反着使用PCA则可以将低维数据恢复到高维。
因为![]() ,那么反过来:
,那么反过来:![]()
注意这里的 只是近似值。

4、选择主成分的分量
在 PCA 算法中,我们把 维特征变量 降维到
维特征变量 。这个数字
也被称作 主成分的数量 或者说是我们保留的主成分的数量 。
首先来看看以下两个值:
1、PCA 的 投射平均均方误差 (Average Squared Projection Error) :

2、训练集的方差,它的意思是 平均来看 我的训练样本 距离零向量多远

3、我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 值:

我们把两个数的比值作为衡量PCA算法的有效性,例如比值小于 1 % 时,说明 PCA 算法保留了原始数据的99% 的差异性。(*一般保留90%即可)
因此我们可以先定义一个阈值,然后不断实验 k,直到获得满足阈值的最小值。
此外,还可以利用奇异值 来计算平均均方误差与训练集方差的比例。[ U , S , V ] = s v d ( Σ ),其中的
为对角矩阵;

5、重建的压缩表示
在PCA算法里我们可能需要把1000 维的数据压缩100 维特征,或具有三维数据压缩到一二维表示。所以,如果这是一个压缩算法,应该能回到这个压缩表示,回到原有的高维数据的一种近似。
所以,给定的?(?),这可能100 维,怎么回到你原来的表示?(?),这可能是1000 维的数组?
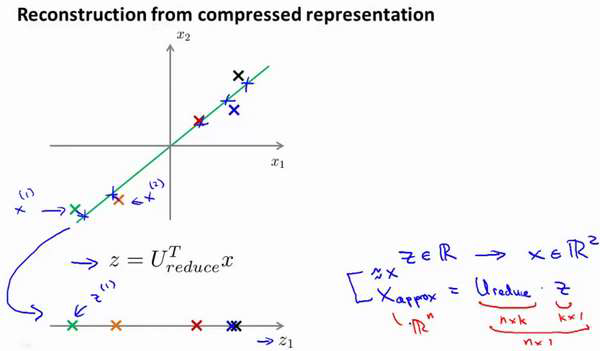
PCA 算法,我们可能有一个这样的样本。如图中样本?(1),?(2)。我们做的是,我们把这些样本投射到图中这个一维平面。然后现在我们需要只使用一个实数,比如?(1),指定这些点的位置后他们被投射到这一个三维曲面。给定一个点?(1),我们怎么能回去这个原始的二维空间呢??为2 维,z 为1 维,? = ???????? ?,相反的方程为:
![]()
把降维的数据还原回高维数据(会有损失):
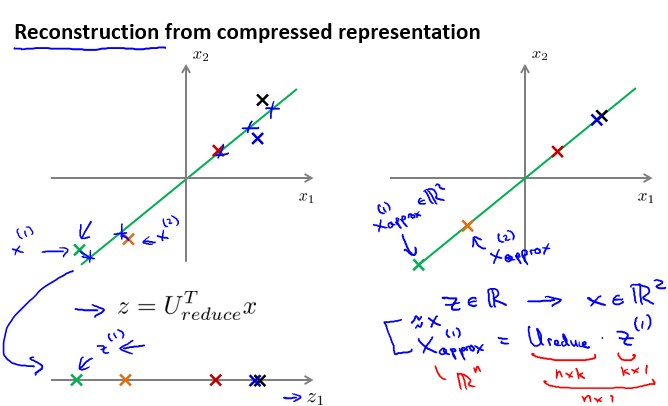
因为PCA仅保留了特征的主成分,所以PCA是一种有损的压缩方式,假定获得新特征向量为:
![]()
还原后的特征 为:
![]()
把这个过程称为重建原始数据。
6、主成分分析法的应用建议
PCA主要用在以下情况:
- 数据压缩,可以提高运算速度和减少存储空间。
- 数据可视化,得到更直观的视图
并注意:
- 有些人觉的PCA也可以用来防止过拟合,但是这是不对的。应该用正则化。正则化使用y标签最小化损失函数,使用了y标签信息。而PCA只单纯的看x的分部就删除了一些特征,损失了很多信息。
- 另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
由于 PCA 减小了特征维度,因而有可能带来过拟合的问题。
PCA 不是必须的,在机器学习中,一定谨记不要提前优化,只有当算法运行效率不尽如如人意时,再考虑使用 PCA 或者其他特征降维手段来提升训练速度。
降低特征维度不只加速模型的训练速度,还有助于在低维空间分析数据
例如,一个在三维空间完成的聚类问题,可以通过 PCA 将特征降低到二维平面进行可视化分析
例如有将近几十个特征来描述国家的经济水平,但很难直观的看出各个国家的经济差异:
借助于 PCA,将特征降低到了二维,并在二维空间进行观察,很清楚的就能发现美国和新加坡具有很高的经济水平等等。