目录
1、摘要
2.相关工作
3.Siamese RNN
3.1 Bidirectional RNNs 以及 LSTM模型:
3.2 Siamese network 孪生网络
3.3 Contrastive loss function 相对损失函数
4.实验部分
4.1.n-gram matcher
4.2 数据增强
4.2.1、Typo and spelling invariance 增加拼写错误
4.2.2、Synonyms 同义词替换
4.2.3、Extra words 增加多余信息
4.2.4、Feedback 人工反馈(工业应用)
5. 总结
创新点
启发点
文章: Learning Text Similarity with Siamese Recurrent Networks
来源:ACL 2016
介绍:论文提出了一种学习变长字符序列相似性度量的深层结构。该模型将字符级双向LSTM与Siamese体系结构相结合。模型将可变长度的字符串投影到固定维度的嵌入空间中。模型不仅能学到不同词之间的语义差异性与语义不变性,应用于基于人工标注的分类任务。
1、摘要
论文提出一种模型用于解决职位归一化问题,将输入字符串映射到外部预定义的类别中去,可视为高度多类别的的分类任务。例如,字符串“software architectural technician Java/J2EE”可能映射为“Java developer”。
本文采用的方法着重于学习字符串的表示形式,使得具有相同含义的职位的表达能够紧密地联系在一起。优点:灵活性比较高,即字符串的表示可以作为后续分类器的输入,也可以用于查找密切相关的职位或者将职位进行聚类,模型的架构可以让我们在有限的监督学习下学习到有用的表示。
主要讲解本篇论文提出一个基于字符级别变长序列的双向LSTM网络结构,并且文中提出多种文本增强的思路,模型不仅能学到不同词之间的语义差异性与语义不变。
2.相关工作
神经网络以及词表示在NLP任务中的发展,以及孪生网络的发展和应用。
 ?
?
3.Siamese RNN
主要讲解孪生网络的模型输入数据、相关参数矩阵介绍、对比损失函数公式介绍
3.1 Bidirectional RNNs 以及 LSTM模型:


?
3.2 Siamese network 孪生网络
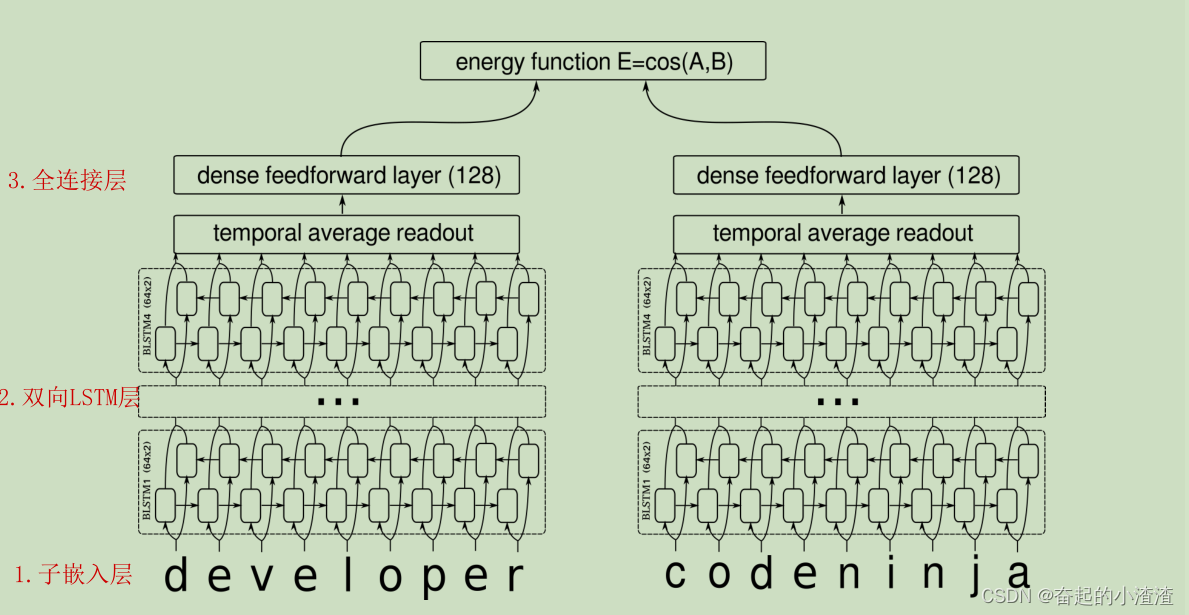
孪生网络是共享权重的双分支网络,它包括两部分相同的网络,然后最后通过一个energy function合并在一起。图1是本文研究的网络的结构。孪生网络的数据集由三元组 组成,其中
是字符序列,
表示
? 是否相似 ( y=1)或不相似( y=0 )【y只是个标志量,相似为1,不相似为0】)。训练的目标是最小化嵌入空间中相似度之间的距离,最大化不同对之间的距离。
3.3 Contrastive loss function 相对损失函数
该网络包含四层双向LSTM节点,最后一个BiLSTM层的每个时间步的激活值被平均化,从而产生一个固定维度的输出。这个输出再通过一个densely connected前馈层进行投影。
设 和
是由网络函数
计算出的嵌入空间中
和
的投影。我们将模型的energy functionE
定义为嵌入向量
和
的余弦相似度:
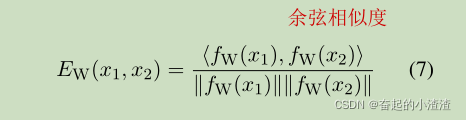
损失函数的自变量为全体数据集,是数据集中每一个数据损失的累加。
简洁起见,我们将用表示
。数据集
的总的损失函数由下式给出(上标中的 i 表示数据集中的第 i 个元素):
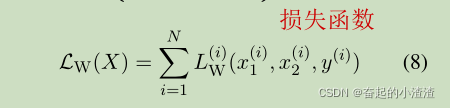
每一个实例的损失函数 是一个Contrastive loss function,由相似度
情况下的损失函数
和相似度
情况下的损失函数
组成:
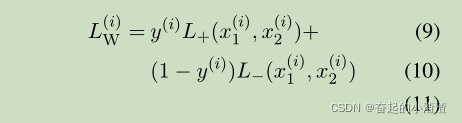
相似和不相似情况下的损失函数如下:
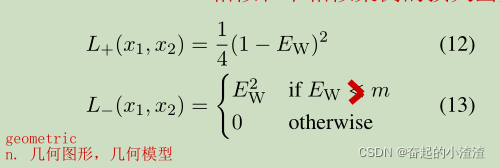
其中,
表示为文本相似度,范围是{0,1}。
句子对越相似,
越小。
如果数据集中标签为1的两文本模型输出的余弦相似度很小,需要进一步优化返回一个较大的损失函数值。
输入标签为负值。输入标签为负余弦相似度值很小,即小于给定的阈值m,则可以认为模型已经可以分出为负样例,则让损失为0.如果模型返回的相似度值大于m,则需要优化。模型计算出的余弦相似值越大,说明模型越不好,需要返回的损失值越大。
下图是损失函数的几何图,分别显示了正和负分量。需要注意的是按比例缩小,以补偿正负样本的采样比例。
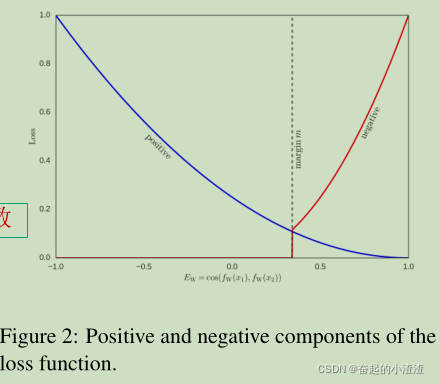
上图中的图像蓝色表示标签为正的增长损失,红色表示标签为负的增长损失。
网络包含4层BiLSTM(64-d hidden),最后一层的BiLSTM的hidden state和cell state进行concat,然后在timestep维度进行average处理,并接一个Dense层(激活函数为tanh),得到的两个Embedding Space进行Cosine sim计算,得到的相似度分数E用于损失函数计算,损失函数使用对比损失函数,计算方法为,损失函数正例:1/4(1-E)^2,负例:E^2(如果E<m),否则0。
4.实验部分
主要首先讲解了baseline模型n-gram matcher,然后介绍了文本数据增强的方法,主要有随机替换字符和一定比例的拼写错误、同义词替换、添加多余信息可以增加鲁棒性、以及人工反馈情况。
4.1.n-gram matcher
将模型与基准n-gram匹配器的性能进行比较。给定输入字符串,此匹配器通过最大化相似性评分功能从基本分类法中查找最接近的邻居。匹配器随后使用该邻居的组标签来标记输入字符串。相似度评分函数定义如下。令Q =?q1,...,qM?是作为字符序列的查询,而C =?c1,。 。 。 ,cN?是分类法中的候选匹配。
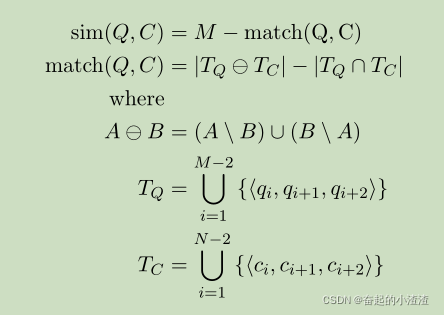
其中,Q和C为文本,M、N分别为Q、C的文本长度。
举例子说明匹配器:
Q: I love you C:l hate you 假设使用3-gram匹配器则:
M= 8,N=8
TQ= {llo, lov, ove, vey, eyo, you}
TC= {lha, hat, ate, tey,eyo, you}
TQ-TC={llo, lov, ove, vey, lha, hat, ate, tey} , TQ
TC={eyo,you}
|TQ-TC| = 8, |TQ
Match(Q,C) = 8-2 =6 ,Sim(Q,C)=8-6=2
4.2 数据增强
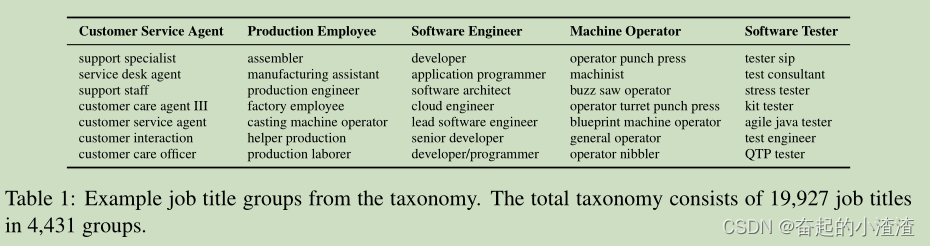
工作职称分类法。该分类法将一组19,927个作业标题划分为4,431个组Group内包含job。
title数量与group数量之间的分布:含有上百条title的group是很少的,通常一个group只含几个title.

数据集采样:按照4:1的采样方式,其中4为between-class (negative) pairs,1为within-class (positive) pairs。
分类数据集的建设:分为四个stage,每个stage又分为两步:
- 使用特殊属性来进行数据扩充
- 对模型进行与该特殊属性相关的行为测试(存疑)四个stage环环相扣,每次augmentation都是基于之前augmentation的基础上
4.2.1、Typo and spelling invariance 增加拼写错误
针对正类样本,随机替换20%字符并删除5%字符,操作之后额外生成大量训练数据。
再取19928条作为测试数据,这些测试数据中被替换或删除的字符占比5%,符合正常人类拼写错误。同时构建了N=19928的Typos测试集,5%的字母被随机替换或者删除。
4.2.2、Synonyms 同义词替换
1、人工构建的同义词词库
2、归纳:在同一个group内,如果两个job title都有某一个或两个词,如“C++ developer”和“C++ programmer”都有“C++”,那么就推断developer和programmer就被认为是同义词(candidate),只要满足:1 两者不出现在isolation(可能是指其他group或者人为设置的排除域),2 不包含特殊字符如“&”,3 包含最多两个词,那么两者就会被认为是同义词(组)
同时构建了N=7909的Composition测试集,构建方法为同义词替换。
4.2.3、Extra words 增加多余信息
实际文本看上去往往不是那么精简,有一些无用信息,加入后不影响语义。
实验共构造了1949条测试数据。

4.2.4、Feedback 人工反馈(工业应用)
实际生产中,数据样本并非每一条都是人工录入,程序自动导入的数据可能出现标签错误,这个时候要求人工可以接入修改标签,测试模型是否能改正之前的错误。
实验设置了1000个测试样例。
实验结果:
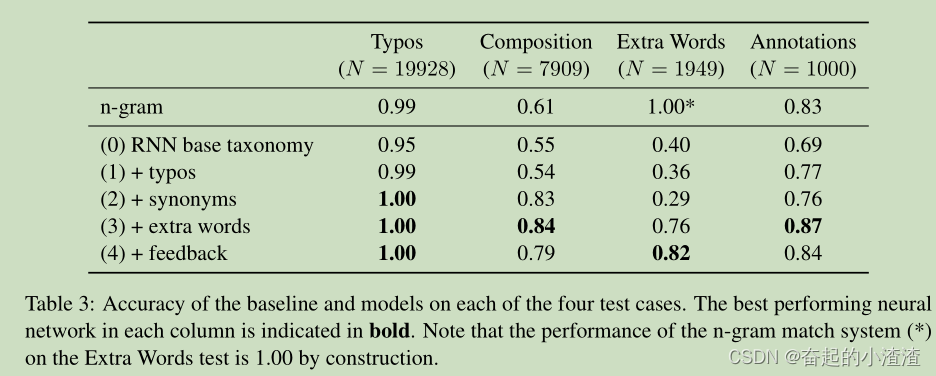
5. 总结
创新点
- 运用孪生神经网络 接收输入数据
- 利用双向LSTM网络 提取文本特征
- 利用对比损失函数 优化模型
- 通过对同类job titles的各种变体(多种spell、错别字、同义词、额外词汇)的学习获得了invariant,对不同类别的学习获得了selectivity
启发点
- 循环神经网络结构对于处理文本、语义特征的强大表现;
- 分层结构是深度学习的基本结构(嵌入层、RNN层、全连接层、预测层)
- 可以考虑对网络output的位置使用attention而不是直接对每个时刻的输出求均值
- 可以考虑采用triplet loss function替换余弦相似度
- 可以考虑CNN与RNN结合
- 仅仅在job titles这个task上效果出众,但是其他标准的文本similarity尚未验证
- 用于对比的baseline较弱
- 负样本的采样方法需要改进,原本是直接在其他类中随机采样,例如负样本可以是在距离较小的group之间采集,加大难度从而进行明确区分
6、实现代码 (待实现)