2019 ICME
《PANet: A Context Based Predicate Association Network for Scene Graph Generation》
文章目录
-
-
- 《PANet: A Context Based Predicate Association Network for Scene Graph Generation》
-
- 针对问题
- 本文创新
- 网络结构
- 谓词预测(关系预测)
- 实验结果
-
针对问题
以前的工作(IMP、MotifNet等等)利用了上下文信息,空间位置信息(LinkNet等),但是在最终预测relation时都是按照分类的方法处理的,即认为relation与relation之间是互斥的,但并不是(例如on和ride在一些情况下是等同的),这些文章都没有利用relation与relation之间的关系,文中称为 谓词与谓词之间的关系
本文创新
基于RNN提出了新的框架来提取上下文信息、位置信息,并在预测谓词的时候结合了谓词与谓词之间的关系信息(这一模块也是基于RNN实现),并且在最终引入了注意力机制(通过加权系数来实现)
网络结构
与近几年的其他算法类似,都引入了目标的 视觉特征、位置信息、上下文信息、类别信息
1. 类别信息编码E_bi
作者提到有两种方式:①词向量嵌入 ②class distribution(类别分布)
当有目标的GT类别标签时,推荐使用词向量嵌入的形式。作者提到词向量嵌入能反映词与词之间的关系。
2. 空间位置编码S_bi
对于一个目标bi的编码方式如下所示:
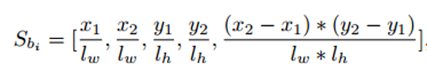
3. 上下文信息F_g
上下文信息与LinkNet中的方式有点类似,直接将整张图的特征向量拼接在目标特征Υ_bi的后面
网络结构
Proposal同样通过RPN提取,对于每一个目标,都使用 [ 视觉特征+类别编码+位置编码 ] 拼接成的特征向量来表示,然后依次输入到RNN中进行处理(这里应该是参考了IMP的消息传递机制),而后每一个目标都会对应产生一个特征向量Υ_bi,此时再引入全局上下文信息,即将整张图的特征拼接在Υ_bi后面得到G_bi来表示目标bi:
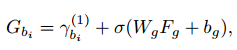
G_bi后面一方面会用于目标的分类器与定位回归
一方面用于与其他目标的关系预测。

谓词预测(关系预测)
如果要预测目标bi与bj之间的关系谓词,这里首先将G_bi与G_bj按元素乘积操作,然后与二者的union区域的特征进行拼接得到关系向量Us,o
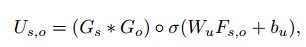
而后将Us,o分别与每个谓词的embedding拼接,依次输入到RNN中再进行一次消息传递(对应创新点中 结合谓词与谓词之间的关系)
最后作者考虑到不同的谓词与最终的结果相关程度不同,因此添加了可计算的权重(相当于引入了注意力)
实验结果
比MotifNet提升了很多,和LinkNet的结果接近
