引言
我们那一篇ACL2019的论文简单介绍了什么叫做Text-to-SQL任务,文本到SQL任务的目的是将自然语言语句映射为结构化的SQL查询。很多工作都是关注于如何生成一个SQL语句,而没有关注怎样可以更高效的利用数据库信息以及SQL模板来指导SQL的生成。前人有一个工作是Execution-Guided Decoding,核心思想是使用部分程序的执行结果来筛选过滤出无法完成的结果以获得正确答案(见下图)。我们在这次工作中在考虑知识库结构( knowledge bases )和SQL查询语法(syntax of SQL queries)的基础上,设计了一种新的评分方法来评价生成的SQL查询。
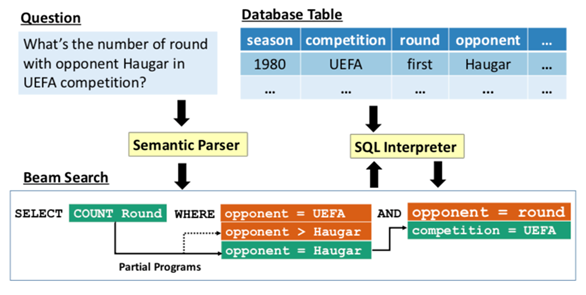
Syntax- and Execution-Aware SQL Generation with Reinforcement Learning(submit to EMNLP2019)
摘要
文本到SQL任务的目的是将自然语言语句映射为结构化的SQL查询。本文在考虑知识库结构和SQL查询语法的基础上,设计了一种新的评分方法来评价生成的SQL查询。为了改进SQL查询的生成,我们在序列到序列模型中使用这个分数作为强化目标。在wikiSQL数据集上的实验结果表明,我们提出的方法在所有指标上都显著提高了性能。新的分数优于现有系统中与强化学习一起使用的其他奖励,并且与通过与知识库交互来解码的执行是可比的。
动机
- 由于SQL查询是符合SQL语法的结构化对象,并且可以在知识库上执行,因此应该有更多的研究语法和执行感知的模型结构。
- 现有的一些工作包括利用生成查询执行的正确性作为奖励,通过强化学习训练的模型(Semantic Parsing with Syntax- and Table-Aware SQL Generation);还有利用部分生成的SQL查询的执行来修剪解码过程中的空间的模型(Robust Text-to-SQL Generation with Execution-Guided Decoding)。但是对于后者,如图1所示,语法有效的子查询可能无法执行,例如“Name=Sweden”的子查询;语法不正确的子查询可以执行,如“Nationality=Name”的子查询。
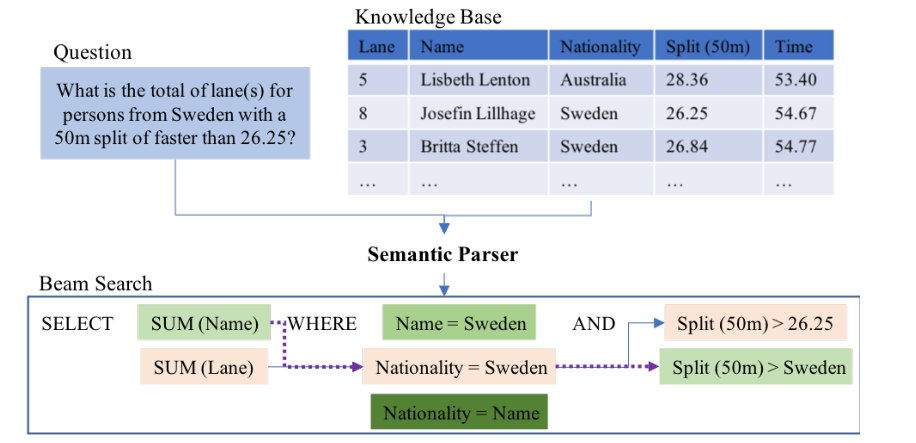
以SQL查询为例,这里显示多个子查询,正确的解析结果用实线连接。这里,“Nationality=Name”不满足SQL语法,因为条件的子查询是“column operator cell”的模式,其得分为0.33;“Name=Sweden”违反了KBs结构,因为“Sweden”不属于“Name”列,其得分为0.67;其他子查询(如“SUM(Name)”)不符合KBs的语义约束,因为聚合器需要对数值进行操作。
总的来说,前者的在SQL加入奖励的强化学习模型,只是将结果和ground truth比较,如果答案正确给1分,答案错误给-1分,语法不正确-2分。这种方法只是最后将一个总的query进行强化学习指导,没有考虑到SQL query的语法结构(层次结构,我们将SQL是为树结构),所以效果有限。
后者的修建解码空间方法,从它是效果来看是一个比较好的模型。它存在以下不足:首先,它只考虑了知识库执行结构,却没有考虑到SQL语法结构;其次,它只是粗暴的筛选过滤出错误解码结果,并没有利用这种信息去指导这个模型更好的学习,让这个模型可以自己学习到数据库结构和SQL语法结构,这样的模型迁移性和鲁棒性容可能会存在缺陷。
贡献
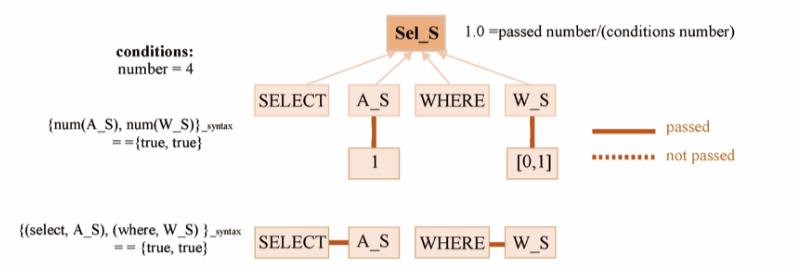
为了满足SQL的语法和数据库执行,我们设计了一个名为SEA score(standing syntax-and execution aware score)的分数来估计生成的SQL查询有效和可执行的概率,根据数据库和SQL语法的结构。SQL查询可以表示为基于语法的解析树(如图2所示),叶节点是SQL语句的元素,分支节点由SQL语法生成。我们根据每个分支节点的子节点满足语法和知识库结构的程度为每个分支节点分配SEA分数。
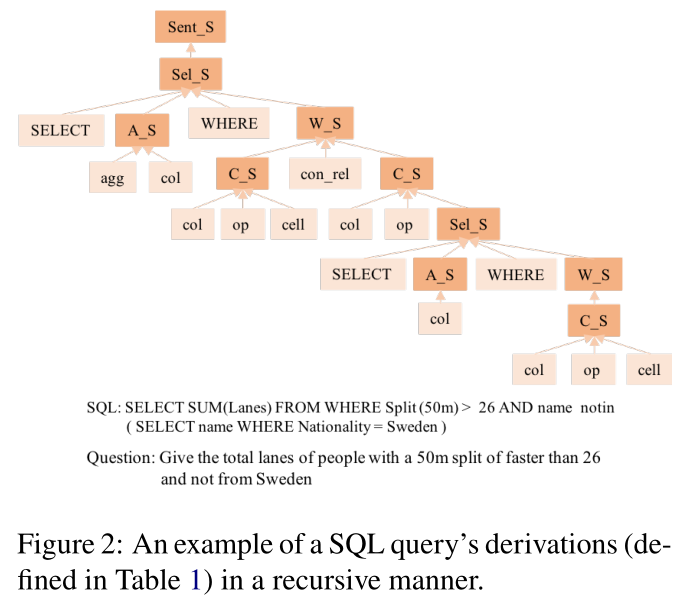
然后自下而上( from bottom to up)计算查询的分数,并评估整个查询的有效性和可执行性。对于图1中的示例,实线连接的查询的分数为1,虚线连接的查询的分数为0.77。我们将此分数作为强化目标来指导模型的训练。提出的分数至少有三个优点。
- 首先,这个分数评估生成的查询的可执行性,在解析过程中可以利用数据库的结构信息和语义约束来保证查询的执行。
- 第二,这个分数在多个粒度上评估SQL语法,在生成过程中,子查询和查询的语法满意度都得到了保证(和先前工作的区别)。
- 第三,在训练过程中以该分数作为强化目标,不需要额外的运算进行预测。
在我们的框架中,我们使用基于指针网络的Seq2Seq模型为基本生成模型,并将其与强化学习(RL)相结合,以SEA分数作为奖励。SEA-score被用来评估生成的SQL查询,并给出反馈来指导生成模型的学习。将最大似然交叉熵损失与策略梯度法的奖励相结合的新目标函数作为训练目标。综上所述,我们主要做出以下贡献:
- 我们设计了一个称为SEA-score的新score来评估生成的SQL查询,同时考虑到KB结构和SQL语法。
- 以SEA评分为强化目标,指导基本模型的学习。实验结果表明,与以往的系统相比,该方法具有更好的性能。
SEA score(standing syntax-and execution aware score)
我们发现SQL query 有两个特征:
SQL查询是一种基于底层形式或语法的结构意义表示。
可以在KBs上执行SQL查询以输出答案。一个可执行的SQL查询应该符合KBs的结构和语义约束,每个子查询都应该是可执行的。
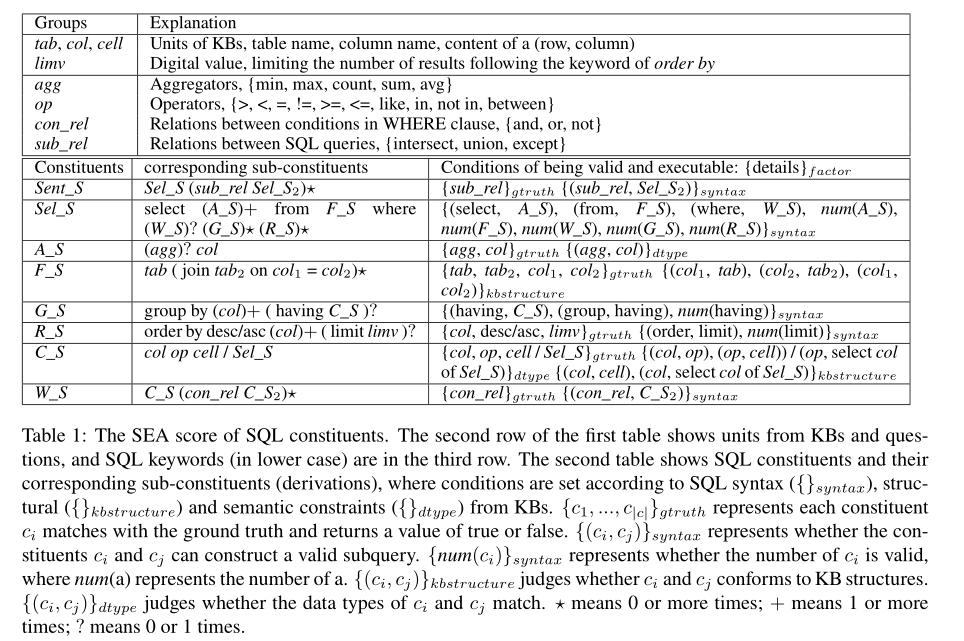
根据这些特点,我们在设计SEA评分时考虑了三个因素:SQL语法、KBs的结构和语义约束,具体如下:
SQL语法:一个SQL查询是由多个子查询或成分以递归方式组成的,每一个子查询都由一个SQL关键字引入,或者由其他子查询组成(如图2所示)。我们总结了可以从中派生SQL查询的SQL语法,如表1底部所述。第一列和第二列显示子查询的派生,第三列显示条件。为了简化派生过程,我们根据SQL关键字和KB单元的功能对它们进行分组,如表1顶部所示。
知识库结构:知识库中有表列和列单元格关系,分别表示一列属于表,一个单元格属于一列。SQL查询只有在符合KB结构时才可执行。
知识库语义约束:我们定义了两种数据类型:数字和字符串对于KB单元和SQL关键字。SQL查询只有在其SQL关键字和KB单位的数据类型匹配时才可执行。
SQL查询的SEA score是所有成分得分的平均值,计算如下:
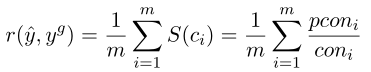
我们举个例子,例如,图1中错误查询(虚线)的SEA分数为0.77,其计算下图所示:
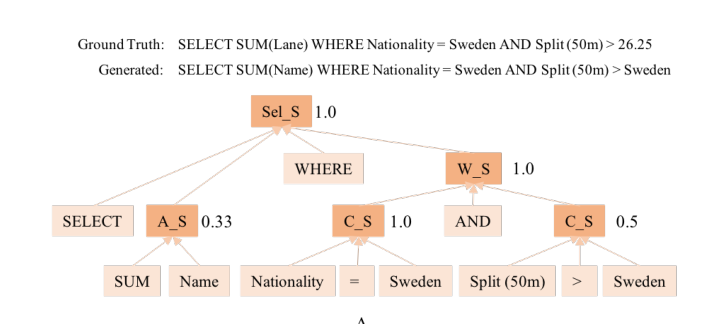
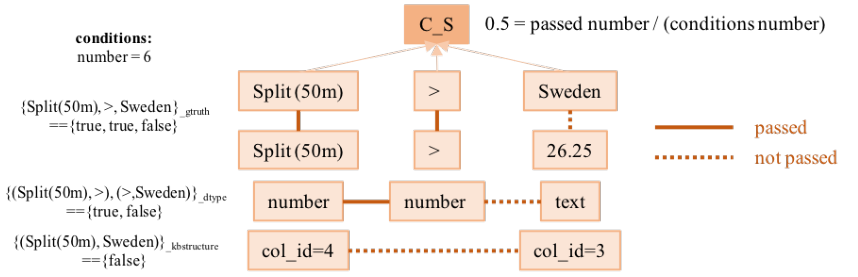
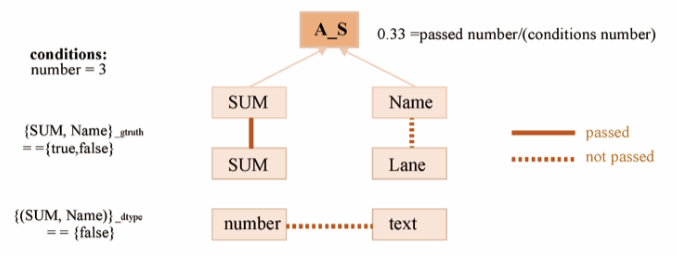
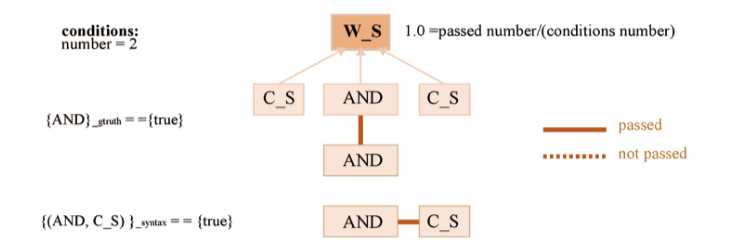
得分计算的一个例子。图A显示了一个查询的计算过程,其分数为(0.33+1+0.5+1+1)/5≈0.77。下面显示了四个成分C的计算,条件({}gtruth,{}dtype,{}kbstructure)的说明见表1。
具体SEA计算的算法如下:

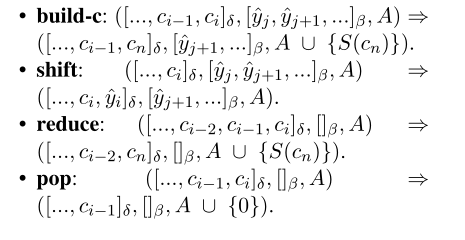
模型
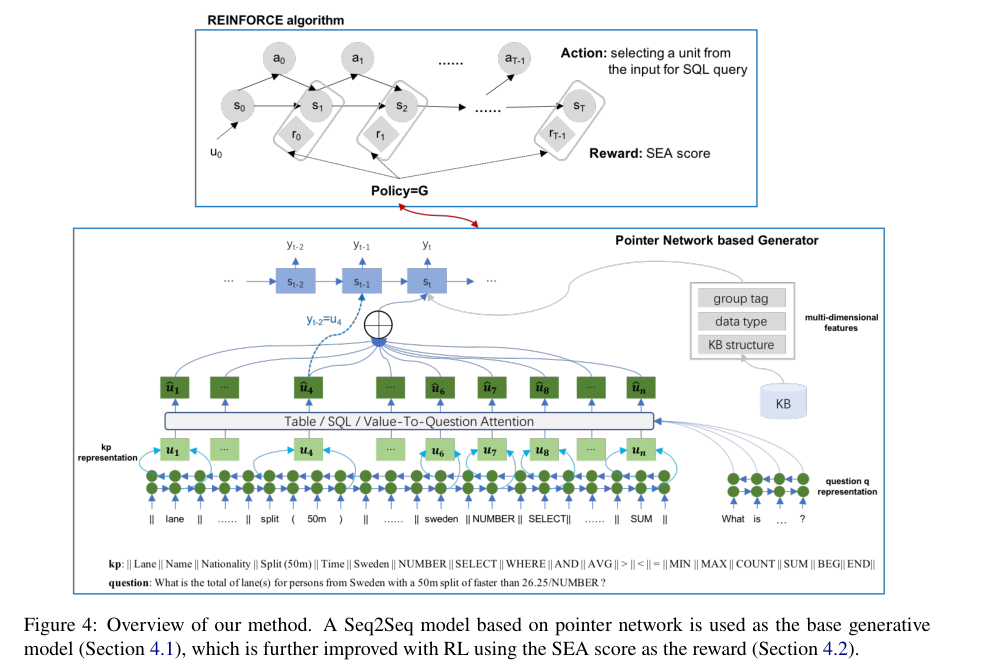
我们探索使用SEA分数作为强化目标来训练生成模型的方法,如图4所示。整个体系结构主要由两个子模块组成:
- SQL查询生成器:基于自然语言问题和知识库系统,生成SQL查询。我们使用Seq2Seq模型作为生成器。
- 用RL改进:训练时将标准监督预测与RL相结合,以SEA分数作为奖励。用长期模拟的方法对策略进行优化。
SQL查询生成器
如图4底部所示,Seq2Seq模型被用作生成器的主干。文本到SQL任务的模型类似于具有增强输入的指针网络,因为生成的SQL查询的输出空间仅限于SQL关键字和KB单元。我们的生成器还在解码器中使用了一个指针
我们的输入是Table-Aware Input,我们使用特殊的标记“| |”来连接KB单元和SQL关键字,以获得一个新的输入序列kp,KB单位由所有列和通过搜索KBs获得的相关单元格组成,在我们的例子中,有两个输入序列,一个是自然语言问题qqq,另一个是输出空间kpk_pkp?。
为了改进SQL查询的生成,根据SEA分数收集特征,包括组标记、数据类型和来自KB结构的关系(见第3节)。它们被用作编码器和解码器的附加信息,并在接下来的实验中被证明是有效的。
编码端是BiLSTM Encoder,解码端是LSTM Decoder.,这里不是该任务的重点,不再赘述。
用RL改进
SEA-score被设计用来在多个粒度上评估SQL查询的语法和执行。我们将决策中的RL方法与Seq2Seq模型相结合,改进了SQL查询的生成。我们工作的策略、操作和奖励功能如图4的顶部所示。实例期望奖励计算如下:
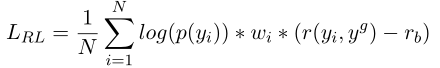
其中yiy_iyi?是生成的SQL查询,ygy_gyg?是基本事实,p(yi)p(y_i)p(yi?)是模型生成yiy_iyi?的概率。NNN是抽样的SQL查询的数量(我们使用beam中具有标准化概率的top?Ntop-Ntop?N生成的序列)。r(yi,yg)r(y_i,y_g)r(yi?,yg?)是奖励函数,即等式1中的SEA得分。rbr_brb?是基线奖励,其目标是强制模型生成产生奖励r>rbr>r_br>rb?的查询,并阻止那些有奖励r的查询<rb<r_b<rb?。
训练策略
训练目标是使交叉熵(CE)损失最小化:
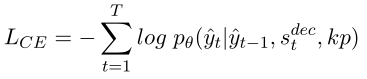
用交叉熵损失对生成器进行几个epoch的预训练,然后缓慢切换到增强损失,如算法1所述。然后,利用策略梯度更新译码器的参数,在RL训练过程中对编码器的参数进行固定。

用RL改进。我们通过两种方式将标准监督预测和RL结合起来:
- 我们使用CE损失函数对模型进行预训练,直到在验证集上获得最佳性能。然后我们使用强化算法来重新训练模型(如算法1所述)。
- 我们使用ηηη来处理从使用CE损失函数到强化损失函数的过渡,Lmixed=ηLRL+(1?η)LCEL_{mixed}=ηL_{RL}+(1?η)L_{CE}Lmixed?=ηLRL?+(1?η)LCE?。当epoch≤30时,ηηη等于epoch×0.03epoch×0.03epoch×0.03;当epoch≥30时,ηηη等于1。
实验
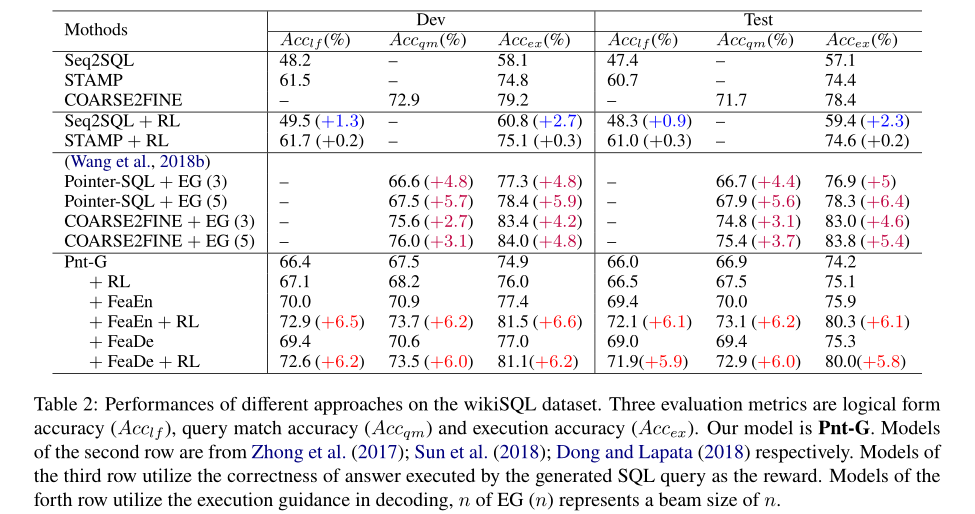
Pnt -G指针网络,类似于STAMP、Seq2SQL和PointerSQL(Wang等人,2018a)。STAMP和PointerSQL都使用多个通道作为输入,包括问题、列名和SQL关键字。条件值是从问题中复制而来的,但不保证可以连续生成多个单词的值。与之不同的是,我们首先得到可以作为条件值的相关单元,并将其作为kp的单位。因此Pnt-G保证了多字值的完整性,并优于STAMP和PointerSQL。
我们的模型利用SEA-score作为强化目标来改进SQL查询的语法和执行。如表2所示,我们的模型(+FeaEn+RL)在测试集中获得了最好的性能,所有指标提高了6%。它已经优于使用其他奖励的模型(在第二部分中提到),并且可以与使用执行指导的模型相媲美(在第三部分中提到)。
- (+RL)模型:SEA评分作为RL的强化目标,用于指导基线的培训。
- (+FeaEn)模型:特征的编码通过连接到kp的最终表示作为编码器中的附加信息。
- (+FeaEn+RL)模型:(+RL)模型和(+FeaEn)模型相结合
- (+FeaDe)模型:通过注意机制,在解码器中使用特征编码作为附加信息。
- (+FeaDe+RL)模型:(+RL)模型和(+FeaDe)模型相结合。
(+RL)模型的结果表明,在没有附加信息的情况下,SEA评分的影响不明显,因为RL模型的学习没有获得有用的信息。和(+FeaDe)模型表明,我们提出的特征有助于改进编码器和解码器中SQL查询的生成。将特征与RL相结合的模型结果表明,SEA评分能有效地从特征中提取出有用的信息,并给出有效的反馈,指导生成器的培训。这种组合显著提高了模型的性能,并最大限度地发挥了RL的作用。
在其他模型之后,我们还报告了对SQL查询组成部分更细粒度的评估指标(如表3所示)。SELECT和WHERE子句的改进与我们设计语法和执行感知分数的主要直觉一致。

RL训练的目标是使期望回报最大化(如等式3所示)。关于我们的RL实验的细节如图5所示。我们可以看到,在训练期间奖励会增加:

我们进行了一个案例研究,以说明Pnt-G与SEA评分的结果,并与Pnt-G进行了比较。在第一个例子中,(+FeaEn+RL)模型从知识库结构中得知“roman kreuziger”的单元格属于“young rider classification”列;在第二个例子中,(+FeaEn+RL)模型更符合SQL语法,它学习了具有“column operator cell”模式;在第三个例子中,(+FeaEn+RL)模型利用知识库语义约束排除max(最大城市)的子查询,因为”max“和"largest city"的数据类型不匹配。

这个任务的亮点
关键词:两个准则,三个约束,多粒度。
两个准则。首先当我们考虑对SQL进行奖励时,应该从两个方面来考虑。首先SQL作为一个结构意义的表示,那么应该有一定的语法规则;其次,SQL语言是要求在KBs上可执行输出的,所以应该是可执行,符合数据库KBs的结构。
三个约束。我们在设计SEA评分时考虑了三个因素:SQL语法、KBs的结构和语义约束。
多粒度。一个SQL查询是由多个子查询或成分以递归方式组成的,每一个子查询都由一个SQL关键字引入,或者由其他子查询组成。基于此,SQL查询可以表示为基于语法的解析树(如图2所示),叶节点是SQL语句的元素,分支节点由SQL语法生成。我们根据每个分支节点的子节点满足语法和知识库结构的程度为每个分支节点分配SEA分数。计算分数时自下而上( from bottom to up)计算查询的分数,并评估整个查询的有效性和可执行性。通过多个粒度上评估SQL语法,因此在生成过程中,子查询和查询的语法满意度都得到了保证。
这个任务的难点
分数设计
我们将SQL查询可以表示为基于语法的解析树,叶节点是SQL语句的元素,分支节点由SQL语法生成。我们根据每个分支节点的子节点满足语法和知识库结构的程度为每个分支节点分配SEA分数。计算分数时自下而上计算查询的分数,这样更好的利用了SQL的结构特点。
以前工作过于简单粗暴。此外当我们设计分数时,非常的全面,包括ground_truth得分、number得分、dtype得分以及kbstructure得分,进行了最全面的约束。
我们的分数就是一种多粒度多层次多维度的得分,因此生成过程中可以保证查询和子查询各个语义的满意度。
如何将分数更好的指导模型
其实当我们开始简单的进行强化学习时效果比较差,然后我们想的是或许这个分数在这个解码模型过于隐式,需要我们加入一些显示特征。将特征与RL相结合的模型结果表明,SEA评分能有效地从特征中提取出有用的信息,并给出有效的反馈,指导生成器的培训。这种组合显著提高了模型的性能,并最大限度地发挥了RL的作用。
强化学习如何训练
其实强化学习是一个可能比较“玄学”的东西,所以说如何训练需要自己去做大量的超参实验验证。在这里一开始我们发现加入RL指导训练后,模型扰动比较大。我们开始尝试fix一定的层,经过一定的试验后,发现固定encoder效果比较好。
这次任务的不足
这个任务总体来看,是一个比较偏制定规则的任务。制定了很多计算人为的规则。比如在哪些节点计算得分,以及如何计算总得分,各个层次,各个粒度的得分比例并没有深究,统一求平均做的。
所以总体来看可能有点糙,往细了做的话,可以尝试不同粒度、不同语义因素或者训练不同阶段给与不同的分数权重,再好一点的话,可以自适应的加入权重。