1.ʲô��pacemaker?
Pacemaker��һ����Ⱥ��Դ��������
�����ü�Ⱥ����������OpenAIS ��heartbeat��corosync���ṩ����Ϣ�ͳ�Ա����������̽�Ⲣ�ӽڵ����Դ����Ĺ����лָ���
��ʵ��Ⱥ�����������Դ�����������ԡ�
�������������κι�ģ�ļ�Ⱥ��������һ��ǿ�������ģʽ���ù���Ա�ܹ�ȷ�ر���Ⱥ����Դ֮��Ĺ�ϵ������˳���λ�ã���
�����κο��Ա�д�Ľű�����������Ϊ����������Ⱥ��һ���֡�
��Ϊ��Ҫ����Pacemaker����һ��heartbeat�ķ�֧���ƺ��ܶ��˴�����������⡣
Pacemaker��CRM��Ŀ������V2��Դ��������������������Ŀ�����Ϊheartbeat����������Ŀǰ�Ѿ���Ϊ������Ŀ��
2.ʲô��corosync��
Corosync�Ǽ�Ⱥ��������һ���֣����ڴ�����Ϣ��ʱ�����ͨ��һ���������ļ���������Ϣ���ݵķ�ʽ��Э��ȡ�
Corosync�Ǽ�Ⱥ��������һ���֣�ͨ������������Դ������һ�����ʹ�����ڴ�����Ϣ��ʱ�����ͨ��һ���������ļ���������Ϣ���ݵķ�ʽ��Э��ȡ�����һ�����˵�������2008���Ƴ�������ʵ��������һ�����������ϵ�����������2002���ʱ����һ����ĿOpenais , �����ڹ�����Ϊ��������Ŀ�����п���ʵ��HA������Ϣ����Ĺ��ܾ���Corosync ,���Ĵ���60%������Դ��Openais. Corosync�����ṩһ��������HA���ܣ�����Ҫʵ�ָ��࣬�����ӵĹ��ܣ��Ǿ���Ҫʹ��Openais�ˡ�Corosync��δ���ķ�չ�������Ժ������Ŀ�һ�����Corosync����hb_gui�����ṩ�ܺõ�HA�������ܣ�����ʵ��ͼ�λ��Ĺ�����������ص�ͼ�λ���RHCS����luci+ricci����Ȼ���л���java������LCMC��Ⱥ�������ߡ�
pcs��Pacemaker/Corosync configuration system��:��Ⱥ��������pcs
pcs��������Ⱥ��ʾ��
һ������Ⱥ����[shell]# pcs cluster auth node1 node2 #����Ⱥ���ڵ����֤as the hacluster user[shell]# pcs cluster setup --name mycluster node1 node2 #����һ�������ڵ�ļ�Ⱥ[shell]# pcs cluster start --all #�������м�Ⱥ[shell]# pcs resource defaults resource-stickiness=100 #������ԴĬ��ճ��[shell]# pcs resource defaults[shell]# pcs resource op defaults timeout=90s #������Դ��ʱʱ��[shell]# pcs resource op defaults[shell]# pcs property set no-quorum-policy=ignore #�����ڵ�ʱ�����Խڵ�quorum����[shell]# pcs property set stonith-enabled=false #û��fencing�豸ʱ������STONITH������ܣ��� stonith-enabled="false" ������£��ֲ�ʽ�������� (DLM) ����Դ�Լ�����DLM �����з������� cLVM2��GFS2 �� OCFS2��������������[shell]# crm_verify -L -V #��֤Ⱥ��������Ϣ ����������Ⱥ��Դ1���鿴������Դ[shell]# pcs resource list ## �鿴֧����Դ�б���pcs resource list ocf:heartbeat[shell]# pcs resource describe agent_name ## �鿴��Դʹ�ò�����pcs resource describe ocf:heartbeat:IPaddr22����������IP[shell]# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 \ip="192.168.10.15" cidr_netmask=32 nic=eth0 op monitor interval=30s 3������Apache(httpd)[shell]# pcs resource create WebServer ocf:heartbeat:apache \httpd="/usr/sbin/httpd" configfile="/etc/httpd/conf/httpd.conf" \statusurl="http://localhost/server-status" op monitor interval=1min4������Nginx[shell]# pcs resource create WebServer ocf:heartbeat:nginx \httpd="/usr/sbin/nginx" configfile="/etc/nginx/nginx.conf" \statusurl="http://localhost/ngx_status" op monitor interval=30s5.1������FileSystem[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \device="/dev/sdb1" directory="/var/www/html" fstype="ext4"[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \device="-U 32937d65eb" directory="/var/www/html" fstype="ext4"5.2������FileSystem-NFS[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \device="192.168.10.18:/mysqldata" directory="/var/lib/mysql" fstype="nfs" \options="-o username=your_name,password=your_password" \op start timeout=60s op stop timeout=60s op monitor interval=20s timeout=60s
6������Iscsi[shell]# pcs resource create WebData ocf:heartbeat:iscsi \portal="192.168.10.18" target="iqn.2008-08.com.starwindsoftware:" \op monitor depth="0" timeout="30" interval="120"[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \device="-U 32937d65eb" directory="/var/www/html" fstype="ext4" options="_netdev"7������DRBD[shell]# pcs resource create WebData ocf:linbit:drbd \drbd_resource=wwwdata op monitor interval=60s[shell]# pcs resource master WebDataClone WebData \master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \device="/dev/drbd1" directory="/var/www/html" fstype="ext4"8������MySQL[shell]# pcs resource create MySQL ocf:heartbeat:mysql \binary="/usr/bin/mysqld_safe" config="/etc/my.cnf" datadir="/var/lib/mysql" \pid="/var/run/mysqld/mysql.pid" socket="/tmp/mysql.sock" \op start timeout=180s op stop timeout=180s op monitor interval=20s timeout=60s9������Pingd�����ڵ���Ŀ���������Ч��[shell]# pcs resource create PingCheck ocf:heartbeat:pingd \dampen=5s multiplier=100 host_list="192.168.10.1 router" \op monitor interval=30s timeout=10s10��������Դclone����¡����Դ����ȫ���ڵ�����[shell]# pcs resource clone PingCheck[shell]# pcs resource clone ClusterIP clone-max=2 clone-node-max=2 globally-unique=true ## clone-max=2�����ݰ��ֳ�2·[shell]# pcs resource update ClusterIP clusterip_hash=sourceip ## ָ����Ӧ����ķ������Ϊ��sourceip����������Ⱥ��Դ1��������ԴԼ��[shell]# pcs resource group add WebSrvs����Դ�����ƣ� ClusterIP��������Դ�����ƣ� ## ������Դ�飬������Դ����ͬһ�ڵ�����[shell]# pcs resource group remove WebSrvs ClusterIP ## �Ƴ����е�ָ����Դ[shell]# pcs resource master WebDataClone WebData ## ���þ��ж��״̬����Դ���� DRBD master/slave״̬[shell]# pcs constraint colocation add WebServer ClusterIP INFINITY ## ������Դ�����ϵ[shell]# pcs constraint colocation remove WebServer ## �Ƴ���Դ�����ϵԼ������Դ[shell]# pcs constraint order ClusterIP then WebServer ## ������Դ����˳��[shell]# pcs constraint order remove ClusterIP ## �Ƴ���Դ����˳��Լ������Դ[shell]# pcs constraint ## �鿴��ԴԼ����ϵ�� pcs constraint --full2��������Դλ��[shell]# pcs constraint location WebServer prefers node11 ## ָ����ԴĬ��ij���ڵ㣬node=50 ָ�����ӵ� score[shell]# pcs constraint location WebServer avoids node11 ## ָ����Դ�ܿ�ij���ڵ㣬node=50 ָ�����ٵ� score[shell]# pcs constraint location remove location-WebServer ## �Ƴ���Դ�ڵ�λ��Լ������ԴID������pcs config��ȡ[shell]# pcs constraint location WebServer prefers node11=INFINITY ## �ֹ��ƶ���Դ�ڵ㣬ָ���ڵ���Դ�� score of INFINITY[shell]# crm_simulate -sL ## ��֤�ڵ���Դ score ֵ
3������Դ����[shell]# pcs resource update WebFS ## ������Դ����[shell]# pcs resource delete WebFS ## ɾ��ָ����Դ4������Ⱥ����Դ[shell]# pcs resource disable ClusterIP ## ������Դ[shell]# pcs resource enable ClusterIP ## ������Դ[shell]# pcs resource failcount show ClusterIP ## ��ʾָ����Դ�Ĵ������[shell]# pcs resource failcount reset ClusterIP ## ���ָ����Դ�Ĵ������ [shell]# pcs resource cleanup ClusterIP ## ���ָ����Դ��״̬���������ġ�����Fencing�豸������STONITH1����ѯFence�豸��Դ[shell]# pcs stonith list ## �鿴֧��Fence�б�[shell]# pcs stonith describe agent_name ## �鿴Fence��Դʹ�ò�����pcs stonith describe fence_vmware_soap2������fence�豸��Դ[shell]# pcs stonith create ipmi-fencing fence_ipmilan \pcmk_host_list="pcmk-1 pcmk-2" ipaddr="10.0.0.1" login=testuser passwd=acd123 \op monitor interval=60smark:
If the device does not support the standard port parameter or may provide additional ones, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
If the device does not know how to fence nodes based on their uname, you may also need to set the special pcmk_host_map parameter. See man stonithd for details.
If the device does not support the list command, you may also need to set the special pcmk_host_list and/or pcmk_host_check parameters. See man stonithd for details.
If the device does not expect the victim to be specified with the port parameter, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
example: pcmk_host_argument="uuid" pcmk_host_map="node11:4;node12:5;node13:6" pcmk_host_list="node11,node12" pcmk_host_check="static-list"3������VMWARE (fence_vmware_soap)�ر�˵��������ʵ����ʹ���˵�3�pcs stonith create vmware-fencing fence_vmware_soap�����ָ��pcmk���ò�����������ִ��Fencing������3.1��ȷ��vmware�������״̬��[shell]# fence_vmware_soap -o list -a vcenter.example.com -l cluster-admin -p -z ## ��ȡ�����UUID[shell]# fence_vmware_soap -o status -a vcenter.example.com -l cluster-admin -p -z -U ## �鿴״̬[shell]# fence_vmware_soap -o status -a vcenter.example.com -l cluster-admin -p -z -n3.2������fence_vmware_soap[shell]# pcs stonith create vmware-fencing-node11 fence_vmware_soap \action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \port="node11" shell_timeout=60s login_timeout=60s op monitor interval=90s[shell]# pcs stonith create vmware-fencing-node11 fence_vmware_soap \action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \uuid="421dec5f-c484-3d69-ddfb-65af46530581" shell_timeout=60s login_timeout=60s op monitor interval=90s[shell]# pcs stonith create vmware-fencing fence_vmware_soap \action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \pcmk_host_argument="uuid" pcmk_host_check="static-list" pcmk_host_list="node11,node12" \pcmk_host_map="node11:421dec5f-c484-3d69-ddfb-65af46530581;node12:421dec5f-c484-3d69-ddfb-65af46530582" \shell_timeout=60s login_timeout=60s op monitor interval=90sע���������fence_vmware_soap�豸ʱ��port=vm name�ڲ���ʱ����ʶ����ʹ��uuid=vm uuid���棻
����ʹ�� pcmk_host_argument��pcmk_host_map��pcmk_host_check��pcmk_host_list ����ָ���ڵ����豸�˿ڹ�ϵ����ʽ��pcmk_host_argument="uuid" pcmk_host_map="node11:uuid4;node12:uuid5;node13:uuid6" pcmk_host_list="node11,node12,node13" pcmk_host_check="static-list"4������SCSI[shell]# ls /dev/disk/by-id/wwn-* ## ��ȡFencing����UUID�ţ�������δ��ʽ��[shell]# pcs stonith create iscsi-fencing fence_scsi \action="reboot" devices="/dev/disk/by-id/wwn-0x600e002" meta provides=unfencing5������DELL DRAC[shell]# pcs stonith create dell-fencing-node11 fence_drac
.....6������ STONITH[shell]# pcs resource clone vmware-fencing ## clone stonith��Դ������ڵ�����[shell]# pcs property set stonith-enabled=true ## ���� stonith �������[shell]# pcs stonith cleanup vmware-fencing ## ���Fence��Դ��״̬��������[shell]# pcs stonith fence node11 ## fencingָ���ڵ�7������tomcat[shell]#pcs resource create tomcat ersweb statusurl=http://127.0.0.1 java_home=/usr/java/jdk1.6.0_12/ catalina_home=/usr/local/Ers/tomcat/ op monitor interval=30s�塢Ⱥ����������1����֤Ⱥ����װ[shell]# pacemakerd -F ## �鿴pacemaker�����ps axf | grep pacemaker[shell]# corosync-cfgtool -s ## �鿴corosync���[shell]# corosync-cmapctl | grep members ## corosync 2.3.x[shell]# corosync-objctl | grep members ## corosync 1.4.x2���鿴Ⱥ����Դ[shell]# pcs resource standards ## �鿴֧����Դ����[shell]# pcs resource providers ## �鿴��Դ�ṩ��[shell]# pcs resource agents ## �鿴������Դ����[shell]# pcs resource list ## �鿴֧����Դ�б�[shell]# pcs stonith list ## �鿴֧��Fence�б�[shell]# pcs property list --all ## ��ʾȺ��Ĭ�ϱ�������[shell]# crm_simulate -sL ## ������Դ score ֵ3��ʹ��Ⱥ���ű�[shell]# pcs cluster cib ra_cfg ## ��Ⱥ����Դ������Ϣ������ָ���ļ�[shell]# pcs -f ra_cfg resource create ## ����Ⱥ����Դ��������ָ���ļ��У����DZ������������ã�[shell]# pcs -f ra_cfg resource show ## ��ʾָ���ļ���������Ϣ����������[shell]# pcs cluster cib-push ra_cfg ## ��ָ�������ļ����ص�����������4��STONITH �豸����[shell]# stonith_admin -I ## ��ѯfence�豸[shell]# stonith_admin -M -a agent_name ## ��ѯfence�豸��Ԫ���ݣ�stonith_admin -M -a fence_vmware_soap[shell]# stonith_admin --reboot nodename ## ���� STONITH �豸5���鿴Ⱥ������[shell]# crm_verify -L -V ## �������������[shell]# pcs property ## �鿴Ⱥ������[shell]# pcs stonith ## �鿴stonith[shell]# pcs constraint ## �鿴��ԴԼ��[shell]# pcs config ## �鿴Ⱥ����Դ����[shell]# pcs cluster cib ## ��XML��ʽ��ʾȺ������6������Ⱥ��[shell]# pcs status ## �鿴Ⱥ��״̬[shell]# pcs status cluster[shell]# pcs status corosync[shell]# pcs cluster stop [node11] ## ֹͣȺ��[shell]# pcs cluster start --all ## ����Ⱥ��[shell]# pcs cluster standby node11 ## ���ڵ���Ϊ��standby״̬��pcs cluster unstandby node11 [shell]# pcs cluster destroy [--all] ## ɾ��Ⱥ����[--all]ͬʱ�ָ�corosync.conf�ļ�[shell]# pcs resource cleanup ClusterIP ## ���ָ����Դ��״̬��������[shell]# pcs stonith cleanup vmware-fencing ## ���Fence��Դ��״̬��������3.�ʵ�黷��
ʵ�黷����rhel7.5
| ������Ϣ | ������ |
|---|---|
| server1(mfsmaster+corosync+pacemaker) | 172.25.8.1 |
| server2��mfschunker�� | 172.25.8.2 |
| server3��mfschunker�� | 172.25.8.3 |
| server4�� mfsmaster+corosync+pacemaker �� | 172.25.8.4 |
��ʵ��������һƪ���µĻ����Ļ����Ͻ��е�
(1���������ĸ����ղ��ҿ���
[root@foundation8 images]# qemu-img create -f qcow2 -b rhel7.5-1.qcow2 mfs4
��2����������ӵ��ĸ������
[root@foundation8 images]# ssh root@172.25.8.4
(3)��server4����master����


��4��������������


��5����дϵͳ�������ļ�����ֹ�����쳣�ر�


��6����������

#1 mfsmaster�ĸ߿���
(1)����mfsmaster���Ȼ�ȡ�߿��ð�װ��
ResilientStorage:�Ǹ߿����е�һ�������



#1 ��server1��װpacemaker��corosyncy,pcs

(2) ��server1��server1��server4��ssh���ܷ���
��Ϊ����vipƯ�Ƶ�ʱ�����û��ssh ���ܷ�����ô����Ҫ�������֤�������������vipƯ��
#������Կ����������

����server4���Լ�������



(3)��������
[root@server1 ~]# systemctl start pcsd
[root@server1 ~]# systemctl enable pcsd
[root@server1 ~]# passwd hacluster Changing password for user hacluster. # �������룬����������ͬ New password: Retype new password: passwd: all authentication tokens updated successfully.


- (2) ����bankup-mfsmaster
����yumԴ




#��װpacemaker��corosync��pcs

��������

#�����û�
[root@server4 ~]# useradd hacluster #�����û�
[root@server4 ~]# id hacluster
[root@server4 ~]# passwd hacluster Changing password for user hacluster. # �������룬����������ͬ New password: Retype new password: passwd: all authentication tokens updated successfully.
-
(4)��sevrer1�ϴ���mfs��Ⱥ��������
������Ⱥ�����ҽ�����֤

���ü�Ⱥ����
[root@server1 ~]# pcs cluster setup --name mycluster server1 server4 #��Ⱥ���ƣ�mycluster ��server1��server4�Ǽ���mycluster��Ⱥ��

[root@base2 ~]# pcs status nodes # �鿴��Ⱥ״̬���б���������Ϊ�в��ַ���û�п���
Error: error running crm_mon, is pacemaker running?
[root@base2 ~]# pcs cluster start --all # �������м�Ⱥ�ķ���
[root@base2 ~]# pcs status nodes # �ٴβ鿴�ڵ���Ϣ
������Ⱥ���з������óɿ���������


�鿴��Ⱥ״̬

# ��֤corosync�Ƿ���������status������ʾ��no faults��ʾһ������

#�鿴corosync״̬

-
����������Ⱥ
#������ã��б���

#�������ԣ�����STONITH

#�ٴμ�飬û�б���


#�鿴������Դ����

#����Ⱥ���洴����Դvip�Լ���֤�߿���

#�鿴��Ⱥ��״̬�����Կ���Ŀǰserver1��server4����master�ڵ㶼����



#�鿴�����ɹ�,���Կ���Ŀǰvip��server1����

-
ִ�й���ת��
�ر�server1�ļ�Ⱥ���鿴���vip���Զ�Ư�Ƶ�server4��




[root@server1 ~]# pcs cluster start server1 # ��master���¿���ʱ
�ٴβ鿴��Ⱥ��״̬


����vip��Ȼ��server4����ģ������Ϊ�����������û�����ȼ����趨���������¿�������,vipû�н���Ư�ƣ�

�������е�ʵ������ʵ���˸߿��ã���master���ֹ���ʱ��backup-master�����̽���master�Ĺ�������֤�ͻ��˿��������õ�����
[root@server1 ~]# pcs resource standards # ��ȡ������Դ���б�
[root@server1 ~]# pcs resource providers # �鿴��Դ�ṩ�ߵ��б�
[root@serve1 ~]# pcs resource agents ocf:heartbeat # �鿴�ض��Ŀ�����Դ����

#2 ����Ⱥ������apache����
#��server1��server4��װhttpd����



#����apache�ķ���ҳ�������


#����server1�ļ�Ⱥ�����Ҹ���Ⱥ�д���apache��Դ



#�ر�server1�ļ�Ⱥ,apache�ļ�Ⱥֱ��Ư�Ƶ�server4��



#���Է���

#���¿���server1�ļ�Ⱥ���ر�server4�ļ�Ⱥ


#�鿴��Ⱥ״̬

#vipҲ�Զ�Ư�Ƶ�server1��

#���Է���
#3 �洢����������vip�ķ�ʽ��ʵ�ֹ�����
�Ȼָ�������д�ý���
[root@foundation8 ~]# umount /mnt/mfs #��ж�ص�ʱ����ʾ��æ������ʹ��fuder -kvm /mnt/mfs�������ɱ�����ٽ���ж��
[root@foundation8 ~]# umount /mnt/mfsmeta
[root@foundation8 ~]# vim /etc/hosts
172.25.78.100 mfsmaster



��server1/2/3/4������������








#�Կͻ��˽�����������
[root@foundation8 ~]# vim /etc/hosts
#�ر�server1��server4�ϵ�mfsmaster�����Լ��ر�server2��server3��mfschunkserver�ķ��ر���Щ��������Ϊϵͳ�Զ�����mooser-master/moosefs-chunkserver����




#�ochunkserver(server2)��chunkserver(server3)�ֱ�����һ�����
#server2��֮ǰ�Ѿ����ӹ�����


[root@server3 ~]# fdisk -l

[root@server3 ~]# yum install -y targetcli # ��װԶ�̿�洢�豸
[root@server3 ~]# systemctl start target # ��������
[root@server3 ~]# targetcli # ����iSCSI����
���Ӵ���block
/> backstores/block create my_disk1 /dev/vda
/> iscsi/ create iqn.2019-10.com.example:server3
port 3260:����˿���Ĭ�ϵģ������豸luns
/> iscsi/iqn.2019-10.com.example:server3/tpg1/luns create /backstores/block/my_disk1 �����ͻ���
/> iscsi/iqn.2019-10.com.example:server3/tpg1/acls create iqn.2019-10.com.example:client
/> exit


#�鿴�˿ڣ�3260����

��master�ϰ�װiscsi�ͻ�������


#����Զ���豸

#��½

# ���Բ鿴��Զ�̹��������Ĵ���

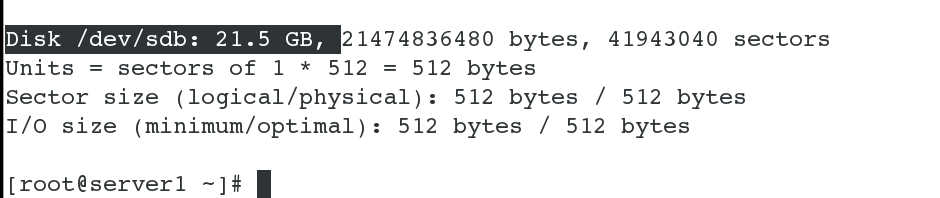
[root@server1 ~]# fdisk /dev/sda # ʹ�ù������̣���������
Command (m for help): n
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-16777215, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-16777215, default 16777215):
Using default value 16777215
Command (m for help): p




[root@server1 ~]# mkfs.xfs /dev/sda1 # ��ʽ������

#�������ķ������й���
[root@server1 ~]# cp -p /var/lib/mfs/* /mnt #��Ȩ����/var/lib/mfs�����������ļ���/dev/sdb1��
[root@server1 ~]# chown mfs.mfs /mnt # ��Ŀ¼����mfs�û�����ʱ����������ʹ��


[root@server1 ~]# mount /dev/sda1 /var/lib/mfs/ # ʹ�÷����������Ƿ����ʹ�ù�������

[root@server1~]# systemctl start moosefs-master # �������ɹ�����˵�������ļ������ɹ����������̿�������ʹ��,ֻ��Ϊ����֤


- ����backup-master����֮Ҳ����ʹ�ù�������

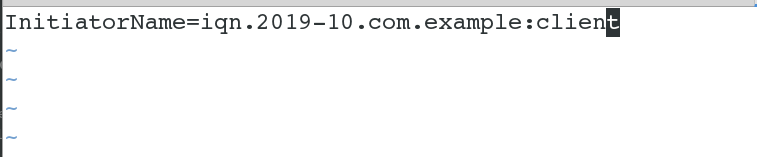



[root@server4 ~]# mount /dev/sda1 /var/lib/mfs/ # �˴�ʹ�õĴ��̺�master��ͬһ�飬��Ϊmaster�Ѿ����������ˣ���������ֻ��Ҫʹ�ü��ɣ������ٴ�����
[root@server4 ~]# systemctl start moosefs-master # ���Դ����Ƿ��������ʹ��
[root@server4 ~]# systemctl stop moosefs-master

#�鿴server1�ϵ�mfs�û�gid��groups�Ƿ�һ�£���һ�¾ͻ�������⣬

#�鿴��Ⱥ�ϵ���Դ

#�鿴��Ⱥ�Ƿ��

- ��master �ϴ���mfs�ļ�ϵͳ
[root@server1 mfs]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sdb1 direcrtory=/var/lib/mfs fstype=xfs op monitor interval=30s #����mfsdata�ļ�ϵͳ�����ش��̷��������ҽ��г�ʼ����op monitor:���м�����;interval:ʱ����
[root@server1 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min #����mfsdϵͳ��systemd:moosefs-master(��������) systemd�ķ�������
[root@server1 ~]# pcs resource group add mfsgroup vip mfsdata mfsd #������Դ�飬vip mfsdata mfsd:�����������ӵķ������ƣ�mfsgroup������
[root@server1 ~]# pcs cluster stop server1 # ���ر�master֮��master�ϵķ���ͻ�Ǩ�Ƶ�backup-master��
#�鿴��أ������и����⣬����apache,��û����server1��Ⱥ��


#�ر�master�ļ�Ⱥ����ȫ��Ư�Ƶ�server4�ϣ�����ʱû��ȷ�����ȼ���


���ڴ���һ�����⣺
������ر�sevrer1��Ⱥ����server4��Ⱥ��vip��Ư�Ƶ�server4�����ǵ���������server1��vip���Զ�Ʈ�ص�server1������Ϊʲô��
��� ��������£���������Ⱥserver1��server4��һ��server1down ����ת�Ƶ���һ��server4����������һ��server1�������Dz�Ӧ�÷���ת�Ƶģ���Ϊserver4��û��down�����������ת�ƵĻ����ᷢ����Դ��ռ�ã�
�������ԣ�
#1����apacheҲ���ӵ���Դ��mfsgroup�Ͳ��ᷢ�����������⣬�ٴ�����server1��Ⱥ����Դ�鶼����server4��
#2���apache����Դ�Ƿֿ��ģ���ô�ͻ�������������⣬�ҵ���������Ϊ����û��ȷ�������Ե��µ�����Ʈ��
-
fence�Զ��ϵ�����(Ҳ����fence�����������)
��1�����ڿͻ��˲��Ը߿���
- ��chunkserver
[root@server2 ~]# systemctl start moosefs-chunkserver
[root@server3 ~]# systemctl start moosefs-chunkserver
- �鿴vip��λ��
[root@server4 ~]# ip a - ����master
[root@server1 ~]# pcs cluster start server1 - �ڿͻ��˽��зֲ�ʽ�洢����
[root@foundation8 ~]# mfsmount # ���أ�����ʧ�� ��������������
[root@foundation8 ~]# vim /etc/hosts
172.25.8.100 mfsmaster
[root@foundation8 ~]# cd /mnt/mfs
[root@foundation8 mfs]# ls # ��Ϊ��Ŀ¼�²��ǿյ�
dir1 dir2
[root@foundation8 mfs]# rm -fr * # ɾ����Ŀ¼�µ������ļ�
[root@foundation8 mfs]# ls
[root@foundation8 ~]# cd
[root@foundation8 ~]# mfsmount # ���Գɹ�����
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:root
[root@foundation8 ~]# cd /mnt/mfs/dir1


�ڿͻ����ϴ����ļ��ر�server4�ļ�ȺҪͬʱ���У�Ҫ��server4��Ⱥ�ȹرգ�����������ѵ�����
mfsĬ��һ��50M
[root@foundation8 dir1]# dd if=/dev/zero of=file2 bs=1M count=2000 # �����ϴ�һ�ݴ��ļ�
[root@server4 ~] # pcs cluster stop server4
[root@foundation78 dir1]# mfsfileinfo file2 # ���Dz鿴���ļ��ϴ��ɹ�����û���ܵ�Ӱ��



ͨ������ʵ�����Ƿ��֣���master�ҵ�֮��backup-master�����̽���master�Ĺ�������֤�ͻ��˿��Խ����������ʣ����ǣ���master��������ʱ�����Dz��ܱ�֤master�Ƿ�������Լ��Ĺ������Ӷ�����master��backup-masterͬʱ��ͬһ�������ļ��Ӷ��������ѣ���ʱfence�������ó���
- ��װfence����
[
[root@server1 ~]# yum install -y fence-virt
[root@server1~]# mkdir /etc/cluster
[root@server4 ~]# yum install -y fence-virt
[root@server4 ~]# mkdir /etc/cluster



#�����װfence����
[root@foundation8 kiosk]# yum install -y fence-virtd
[root@foundation8 kiosk]# yum install fence-virtd-libvirt -y
[root@foundation8 kiosk]# yum install fence-virtd-multicast -y
[root@foundation8 kiosk]# fence_virtd -c #��ʼ��
Listener module [multicast]:
Multicast IP Address [225.0.0.12]:
Multicast IP Port [1229]:
Interface [virbr0]: br0 # ע��˴�Ҫ�Ľӿڣ������뱾��һ��
Key File [/etc/cluster/fence_xvm.key]:
Backend module [libvirt]:









[root@foundation8 kiosk]# mkdir /etc/cluster # ���Ǵ����Կ���ļ�����Ҫ�Լ��ֶ�����
[root@foundation8 cluster]# ls
fence_xvm.key

[root@foundation78 cluster]# scp fence_xvm.key root@172.25.8.1:/etc/cluster/
[root@foundation78 cluster]# scp fence_xvm.key root@172.25.8.4:/etc/cluster/

[root@foundation8 cluster]# systemctl start fence_virtd
[root@foundation8 cluster]# netstat -anulp | grep 1229

[root@foundation8 ~]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1

[root@foundation8 cluster]# virsh list # �鿴��������
[root@server1 ~]# cd /etc/cluster
[root@server1 cluster]# pcs stonith create vmfence fence_xvm pcmk_host_map="server1:haproxy1;server4:haproxy4" op monitor interval=1min #server1:haproxy1 �����������������

[root@server1 cluster]# cd
[root@server1 ~]# pcs resource show #�鿴������Դ
[root@server1 ~]# pcs property set stonith-enabled=true
[root@server1 cluster]# crm_verify -L -V #������֤


#������ԴĬ��ճ�ԣ���ֹ��Դ���У�
#����server4���ó����ȼ�����server1�� server4���master








#��ᷢ�����ϵ���Դ��������������û�з��������Ư��
[root@server4 cluster]# fence_xvm -H server4��Ҳ�����������������haproxy4�� # ʹserver4�ϵ�����

[root@server1 cluster]# crm_mon # �鿴��أ�server4�ϵķ���Ǩ�Ƶ�serve1����

[root@server1 cluster]# echo c > /proc/sysrq-trigger # ģ��server1(master��)�ں˱��� ,�鿴��أ�server4�����̽ӹ�server1(master�ˣ������з���

��server1�ϵ������ɹ�������ռ��Դ����֤�������ѣ�

- �鿴���:���룺crm_mon������server1(master)�����ɹ�֮��������ռ��Դ������������server4(backup-master��)�������У�˵��fence��Ч
С֪ʶ
pcs cluster cib:�鿴��Ⱥ��Դ����ϸ��Ϣ
stonith_admin -I :��ǰ֧��fence�ķ�ʽ
fence_xvm -H node1(���������)��ָ��fence
pcs stonith fence server1(��������)��