Rethinking SIMD Vectorization for In-Memory Databases �����Ķ��ʼ�
��������
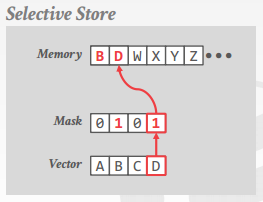
selective store
�� vector lane ��һ���֣����� mask��д�������ڴ�
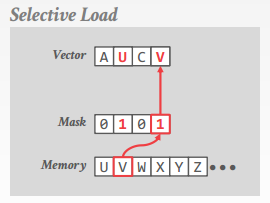
selective load
�������ڴ���뵽 vector lane ��һ���֣����� mask��
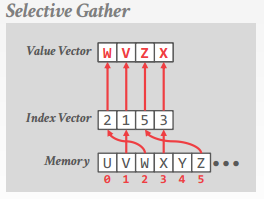
selective gather
�ӷ������ڴ棨���� index vector�����뵽 vector lane
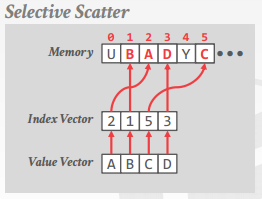
selective scatter
�� vector lane д�뵽�������ڴ棨���� index vector��
ע�� gather �� scatter ������1��ʱ�����������
Selection Scan

- W��SIMD vector ����
- j���������
- l��buffer B[] �����һ��Ԫ�صĺ��λ��
- B[]��buffer�����汻 selected �еı�ţ�û����˵����������Ϊ |B| �� W ����������
- r[]����ŵ� vector������Ϊ W������ selective store��mask m
- m��predicate �������һ�� mask vector
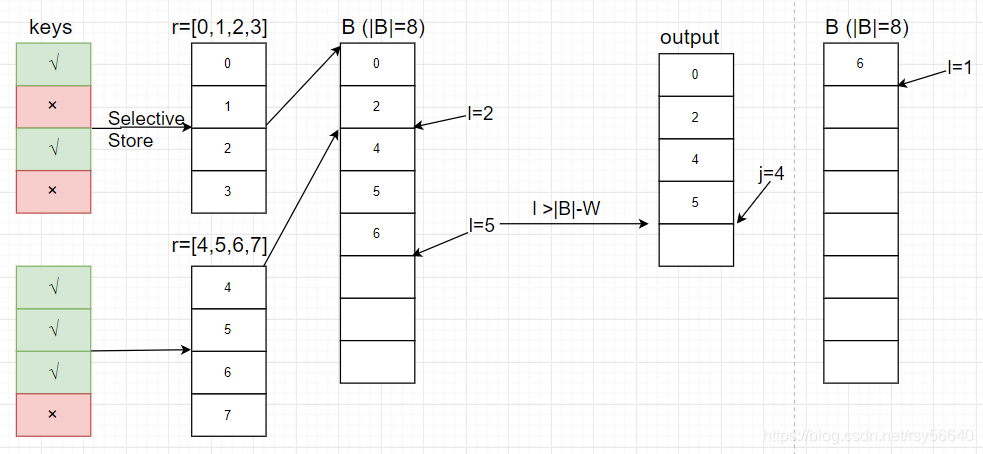
��˼����ÿ�δ���һ����Ȼ�������˾� output��
Hash Table
Linear Probing
Probe

�ο� Vectorization vs. Compilation in Query Execution �����Ķ��ʼ�
����һƪ�ʼ��е��㷨��һЩ����û�� match[]������ÿ��ѭ���б��ų����ľ�ȥ���µ� input��Algorithm5 ���һ�е� m ��ʾ�ų����ģ����� �Ѿ�ƥ��ɹ��� �� ƥ�������ж�ʧ�ܵ��������µ� input������ƥ��ľ� offset+1������������ bucket ��ƥ�䡣������ output ˳��� probe input ˳����ܲ�һ�¡���һƪ�ʼ�����㷨�ǰ�ÿ�� input check ��ż�����һ�֣�
Build

��Ȼû���� Rank and Permute �� group by key�������ο� A Vectorized Hash-Join �����Ķ��ʼ�
����ʹ�� Rank and Permute��Ȼ���ѯ next[] ������ probe������
�ҸĽ��� probe ���̣���� build ʱʹ�� rank and permute �� group by keys

Reference
- CMU 15-721 21 Vectorized Query Execution Part I (Spring 2018)
- DataBase Partitioning Techniques