目录
1.多线程爬虫Multiprocessing
1.1单线程爬虫vs多线程爬虫
1.2多线程爬虫知识点
1.3多线程爬虫库:多进程库multiprocessing
1.4开发多线程爬虫实例
2.爬虫常用搜索算法Search Algorithm
1.多线程爬虫Multiprocessing
1.1单线程爬虫vs多线程爬虫
单线程爬虫:爬虫只有一个进程、一个线程。单线程爬虫每次只访问一个页面,不能充分利用计算机的网络带宽。一个页面最多也就几百KB,所以爬虫在爬取一个页面的时候,多出来的网速和从发起请求到得到源代码中间的时间都被浪费了。
多线程爬虫:为了达到倍速爬取速度的目的,就需要使用多线程技术了。
1.2多线程爬虫知识点
Python的全局解释器锁(Global Interpreter Lock, GIL)导致Python的多线程都是伪多线程,即本质上还是一个线程,但是这个线程每个事情只做几毫秒,几毫秒以后就保存现场,换做其他事情,几毫秒后再做其他事情,一轮之后回到第一件事上,恢复现场再做几毫秒,继续换……微观上的单线程,在宏观上就像同时在做几件事。
这种机制在I/O(Input/Output,输入/输出)密集型的操作上影响不大,但是在CPU计算密集型的操作上面,由于只能使用CPU的一个核,就会对性能产生非常大的影响。所以涉及计算密集型的程序,就需要使用多进程,Python的多进程不受GIL的影响。
爬虫属于I/O密集型的程序,所以使用多线程可以大大提高爬取效率。
1.3多线程爬虫库:多进程库multiprocessing
1.multiprocessing本身是Python的多进程库,用来处理与多进程相关的操作。
2.但是由于进程与进程之间不能直接共享内存和堆栈资源,而且启动新的进程开销也比线程大得多,因此使用多线程来爬取比使用多进程有更多的优势。
3.multiprocessing下面有一个dummy模块,它可以让Python的线程使用multiprocessing的各种方法。
4.dummy下面有一个Pool类,它用来实现线程池。这个线程池有一个map()方法,可以让线程池里面的所有线程都“同时”执行一个函数。
5.别用低效率的for循环!!!
计算自然数平方举例:
from multiprocessing.dummy
import Pool??
def calc_power2(num):?? # 定义函数计算平方 return num * num??
pool = Pool(3)??
# 初始化3个线程的线程池。这3个线程负责计算10个数字的平方,谁先计算完手上的这个数,
# 谁就先取下一个数继续计算,直到把所有的数字都计算完成为止。
origin_num = [x for x in range(10)]??
result = pool.map(calc_power2, origin_num)??
# 线程池的map()方法接收两个参数,第1个参数是函数名,第2个参数是一个列表。
# 注意:第1个参数仅仅是函数的名字,是不能带括号的。第2个参数是一个可迭代的对象,
# 这个可迭代对象里面的每一个元素都会被函数clac_power2()接收来作为参数。
# 除了列表以外,元组、集合或者字典都可以作为map()的第2个参数。print(f'计算0-9的平方分别为:{result}')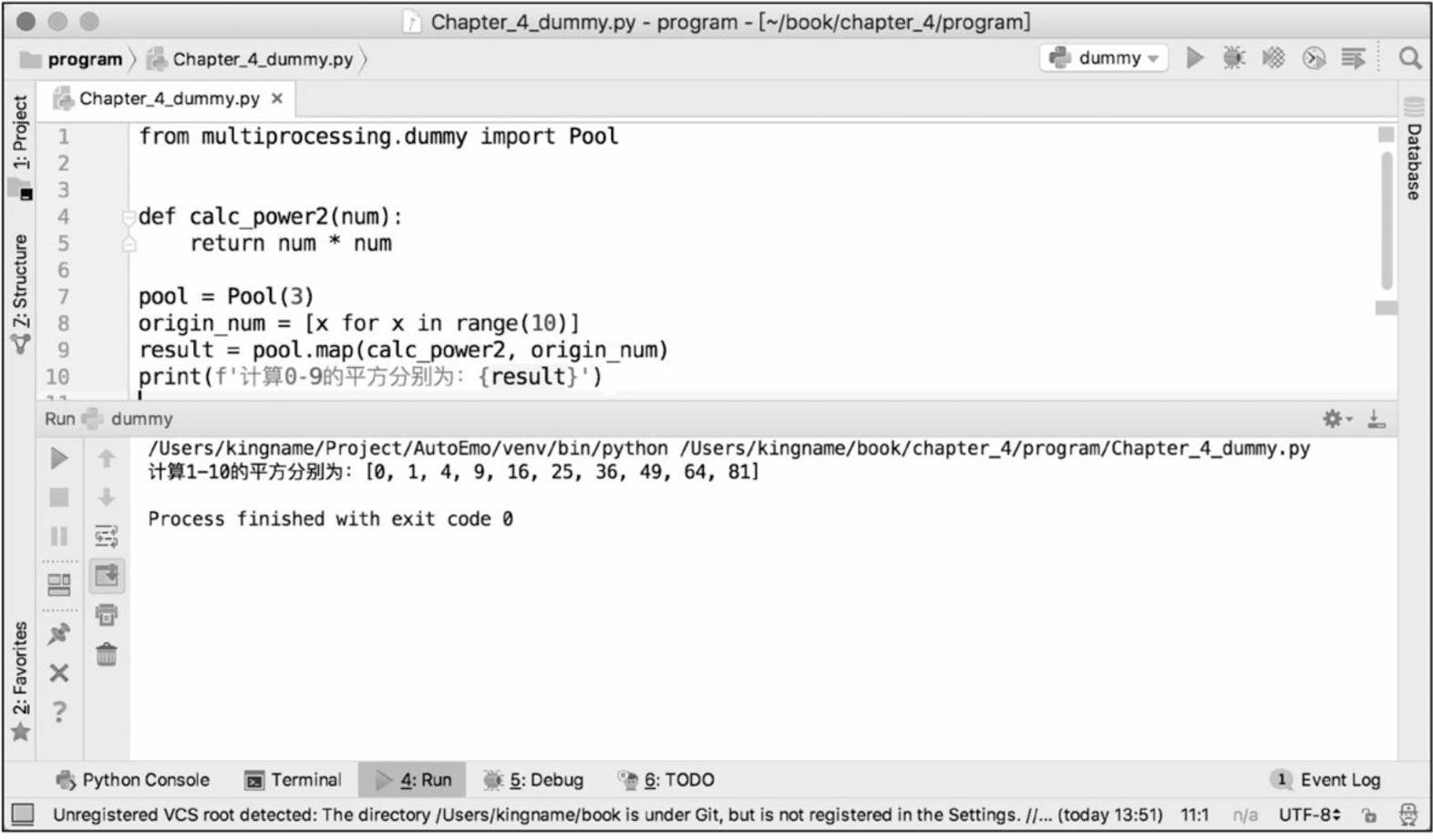
注意:由于这个例子不涉及I/O操作,所以在Python GIL的影响下,使用3个线程并不会使代码的运行时间小于单线程的运行时间。
1.4开发多线程爬虫实例
多线程和事件驱动的异步模型的差异:每时每刻都检查vs一件事做完提醒你做相应的动作。
在需要操作的动作数量不大的时候,这两种方式的性能没有什么区别,但是一旦动作的数量大量增长,多线程的效率提升就会下降,甚至比单线程还差。而到那个时候,只有异步操作才是解决问题的办法。
现在我们通过两段代码,来对比单线程爬虫和多线程爬虫爬取百度首页的性能差异:具体代码见博主github:WebSpider/multiprocessThread.py at main · zjw001210/WebSpider · GitHub

在导入书中multiprocessing 的包的时候,我发现这个import 导致了报错,在查过相关问题后,重新在PyCharm里搜索了multiprocess 的包,该package的介绍是:
multiprocess is a fork of multiprocessing, and is developed as part of pathos: https://github.com/uqfoundation/pathos
multiprocessing is a package for the Python language which supports the spawning of processes using the API of the standard library's threading module. multiprocessing has been distributed in the standard library since python 2.6.
# multiprocess 是 multiprocessing 的一个分支,是作为 pathos 的一部分开发的:https://github.com/uqfoundation/pathos multiprocessing 是 Python 语言的包,它支持使用标准库线程模块的 API 生成进程。从 python 2.6 开始,multiprocessing 已经在标准库中分发。
因此可以直接将multiprocessing 换成multiprocess 即可。
Tips:
并不是说线程池设置得越大越好,5个线程运行的时间其实比一个线程运行时间的五分之一要多一点。这多出来的一点其实就是线程切换的时间。
这也从侧面反映了Python的多线程在微观上还是串行的。因此,如果线程池设置得过大,线程切换导致的开销可能会抵消多线程带来的性能提升。
线程池的大小需要根据实际情况来确定,并没有确切的数据。需要我们在具体的应用场景下设置不同的大小进行测试对比,找到一个最合适的数据。
2.爬虫常用搜索算法:深度/广度优先搜索
2.1概念定义
例:某网站课程分类
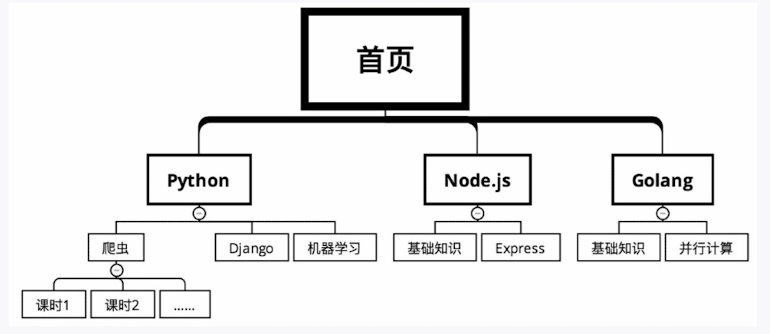
深度优先搜索:一次只领取一个任务,把这个任务做完,再去领下一个任务。
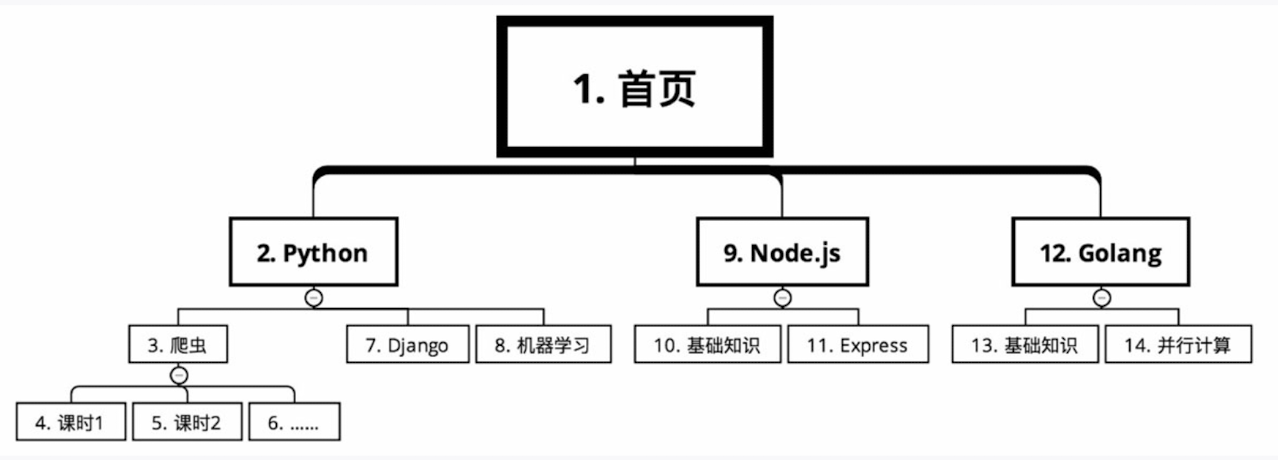
广度优先搜索:先把能够领取的所有任务一次性领取完,然后去慢慢完成,最后再一次性把任务奖励都领取了。
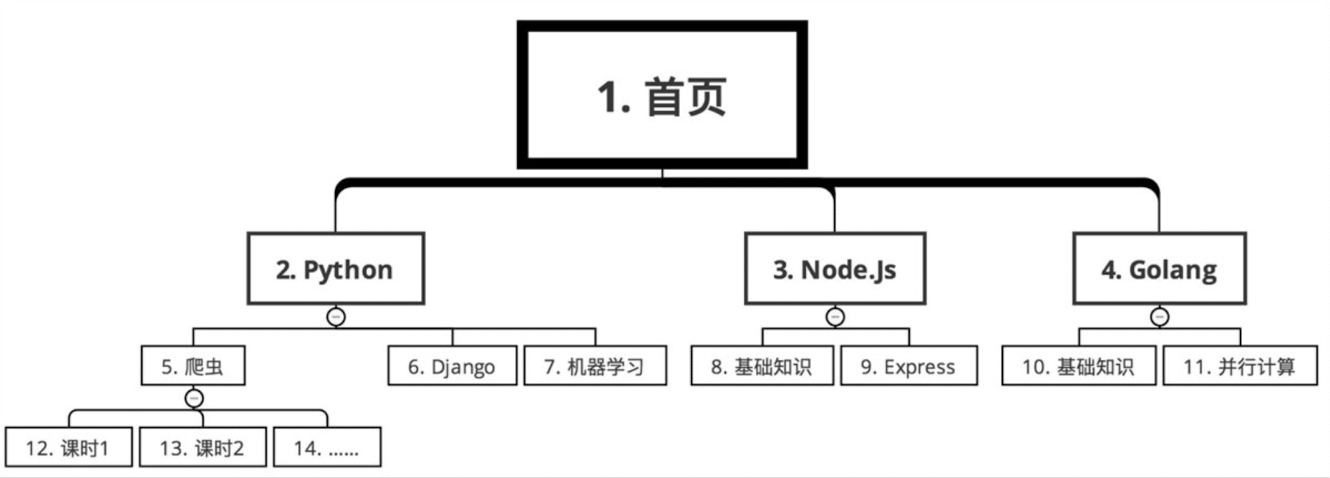
数字就是搜索顺序。
2.2算法选择依据
在爬虫开发的过程中,应该选择深度优先还是广度优先呢?这就需要根据被爬取的数据来进行选择了。
例如要爬取某网站全国所有的餐馆信息和每个餐馆的订单信息。假设使用深度优先算法,那么先从某个链接爬到了餐馆A,再立刻去爬餐馆A的订单信息。由于全国有十几万家餐馆,全部爬完可能需要12小时。这样导致的问题就是,餐馆A的订单量可能是早上8点爬到的,而餐馆B是晚上8点爬到的。它们的订单量差了12小时。而对于热门餐馆来说,12小时就有可能带来几百万的收入差距。这样在做数据分析时,12小时的时间差就会导致难以对比A和B两个餐馆的销售业绩。
相对于订单量来说,餐馆的数量变化要小得多。所以如果采用广度优先搜索,先在半夜0点到第二天中午12点把所有的餐馆都爬取一遍,第二天下午14点到20点再集中爬取每个餐馆的订单量。这样做,只用了6个小时就完成了订单爬取任务,缩小了由时间差异致的订单量差异。同时由于店铺隔几天抓一次影响也不大,所以请求量也减小了,使爬虫更难被网站发现。
又例如,要分析实时舆情,需要爬百度贴吧。一个热门的贴吧可能有几万页的帖子,假设最早的帖子可追溯到2010年。如果采用广度优先搜索,则先把这个贴吧所有帖子的标题和网址都获取下来,然后根据这些网址进入每个帖子里面以获取每一层楼的信息。可是,既然是实时舆情,那么7年前的帖子对现在的分析意义不大,更重要的应该是新的帖子才对,所以应该优先抓取新的内容。
相对于过往的内容,实时的内容才最为重要。因此,对于贴吧内容的爬取,应该采用深度优先搜索。看到一个帖子就赶紧进去,爬取它的每个楼层信息,一个帖子爬完了再爬下一个帖子。
当然,这两种搜索算法并非非此即彼,需要根据实际情况灵活选择,很多时候也能够同时使用。
这P结束啦,接下来会介绍具体的肚复杂网页多线程爬虫以及html网页解析方式~