1. 事务
首先,我们先说一下事务,大家都不陌生,事务就是多条对数据库增删改的SQL要么一起成功,要么一起失败。
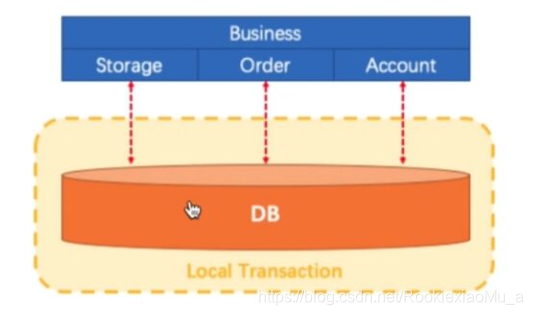
如上图:比如我们下订单,订单模块、库存模块、账户模块都是同一个系统使用的同一个DB,同一个数据库Connect,在这个基础上去保存订单、减库存、减账户余额,那么可以保证是同一个事务,可以保证事务的一致性。
注:这里强调的是同一个数据库Connect,如果上图使用的是同一个DB,但不是同一个Connect(订单一个Connect、库存一个Connect、账户一个Connect),那也不能属于同一个事务。
总结:事务是属于同一个数据库Connect。
2. 分布式事务
刚开始上图三个业务可能是属于同一个项目,但是随着业务量变大,你的用户数变多,你很有可能要去改造你的系统,你很可能改造成下面这个样子:
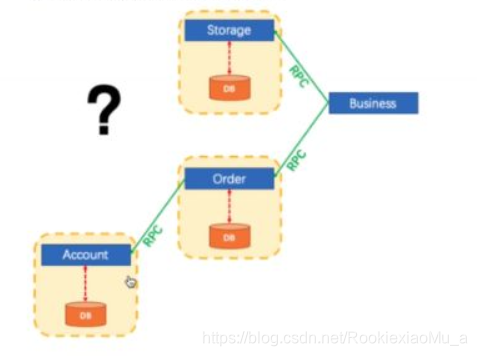
订单、库存、账户各拆分成一个独立的服务,他们分别有一个自己的DB。
对于电商的用户来说,他可能感受不到什么改变,下单还是照常下单,但是对于我们后台内部人员来说,现在下一个订单就和以前很不一样了,库存系统就只能有一个Connect去连自己的DB,你要去操作账户余额那就只能由订单系统发一个请求去单独操作我们的账户系统。
这个时候你还想要去保证事务的一致性,应该怎么办?你还用LocalTransactional(数据库的本地事务)是不能解决这个问题的;
那么这个时候就要用到我们的分布式事务了。
3. 案例
比如:现在有两个服务:server1、:server2,两个服务方法上都添加事务。
在server1中,我们会保存一条server1的数据到数据库里面,紧接着调用server2,server也会在数据库中保存一条server2的数据,调用完server2之后,紧接着server1出现异常,这个时候数据库中会有几条数据?是谁的数据?
Server1:
public class Server1 {
@Transactionalpublic void test() {
Server1Dao.insert(new Order(UUID.randomUUID()));HttpClient.get("http://localhost:8082/server2/test");int i = 1/0;}}
Server2:
public class Server2 {
@Transactionalpublic void test() {
Server2Dao.insert(new Order(UUID.randomUUID()));}}
答案:对了,是一条server2 的数据。
那么为什么呢?我明明两个方法上都加了事务的啊,这就是我们说的,我们使用的不是同一个数据库Connect。
结合到实际:我的订单系统报错rollBack了,但是我的库存系统还是减库存了,并没有rollBack,这就是一个非常大的问题。
分布式事务要做的事情就是:在数据库中我们连server2的数据也不要存。
4. 分布式事务框架:Seata
在微服务架构中,分布式事务是一直是一个比较难实现的。通常对于我们对强一致性不做要求,通过消息队列来实现数据的最终一致性。
Seata是阿里提供的分布式事务解决方案,通过Seata可以实现对多个微服务之间的全局事务管理。
Seata解决分布式事务问题,有两个设计初衷
- 对业务无侵入:即减少技术架构上的微服务化所带来的分布式事务问题对业务的侵入 高性能:减少分布式事务解决方案所带来的性能消耗
seata中有两种分布式事务实现方案,AT及TCC - AT模式:主要关注多 DB 访问的数据一致性,当然也包括多服务下的多 DB 数据访问一致性问题 ;TCC 模式:主要关注业务拆分,在按照业务横向扩展资源时,解决微服务间调用的一致性问题
Seata 分为三个角色:
TC:事务协调器,用于控制全局事务以及Batch
TM:事务管理器,用于启动,回滚和提交事务
RM:资源管理器,用于注册本地资源为全局事务的一个Batch
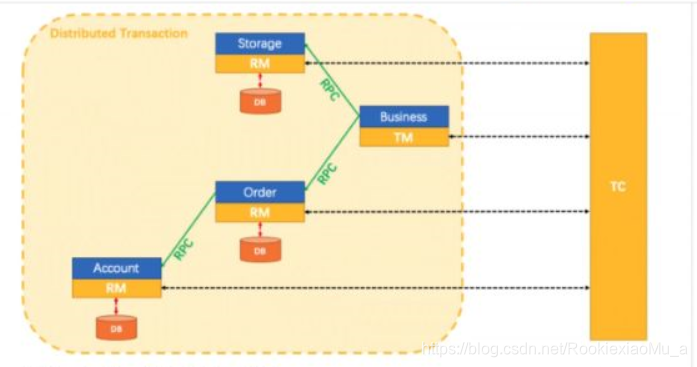
如图所示:
订单、库存、账户三个事务都是属于一个分布式事务的。你可以将TC理解为一个大的事务,订单、库存、账户都是TC的子事务,用来协调字子事务应该怎么做,到底是commit还是rollback;
但是注意:TC只是协调,具体子事务的commit、rollback操作还是由TM来操作的,TC只是告诉这些子事务到底应该怎么做。
5. seata工作流程
- TM向TC注册全局事务,TC开启全局事务,返回一个全局事务ID(XID)
- RM开启本地事务,同时将本地事务注册到TC(携带XID),将本地事务与全局事务进行绑定
- Feign远程调用时,会将XID进行传递,同时另一个RM开启本地事务并注册到TC,将本地事务与全局事务进行绑定
- 本地事务执行完毕之后往undo_log表插入一条数据,同时提交本地事务
- TM判断各个子事务是否全部执行成功
5.1. 二阶段提交,若各子事务都执行成功,TM通知TC整个事务成功,TC通知各RM(各分支事务)提交事务(删除之前插入的undo_log数据即可,因为本地事务执行完就已经提交了)
5.2. 二阶段回滚,若有子事务执行失败,TM通知TC事务回滚,TC通知各RM(各分支事务)回滚事务(根据undo_log数据回滚)
6. 分布式事务框架实现思路
想一想,如果我们要写一个分布式事务框架,我们应该怎么实现?
首先:我们之前的流程:不管是订单还是库存系统都是:
- 建立连接
- 开启事务
- 执行方法
- 提交/回滚
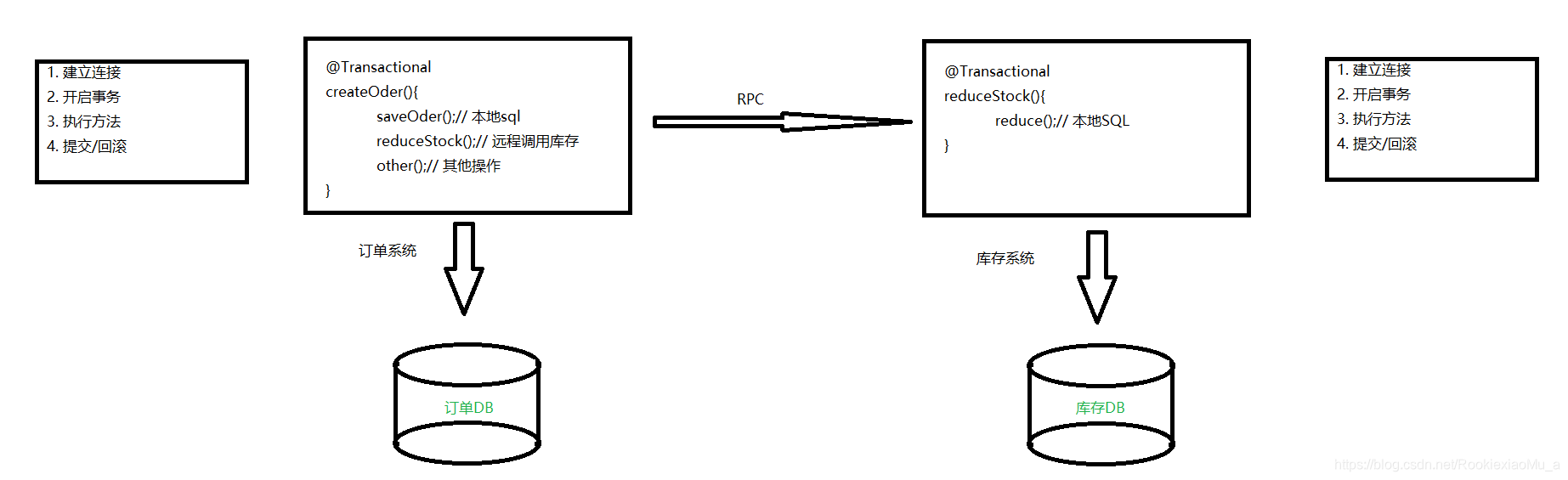
这样显然是不行的嘛。因为我们下面一个系统执行完之后直接就提交了,根本不知道上一个系统到底是成功还是失败了。
那么解决这个问题我们需要做什么呢?
第一:在我们执行第三步之后、第四步之前,我们先wait一下,等人告诉我到底是应该commit还是rollBack。
1. wait…
即:
- 建立连接
- 开启事务
- 执行方法
// wait… - 提交/回滚
第二:我们的案例调用链上现在是两个系统,可以订单一同告诉库存系统成功还是失败,那如果调用链上是几十几百个服务岂不是很复杂。
那么这个时候就会出现一个事务管理者,现在我们叫做是事务管理者。
我们的订单、库存系统 ,把自己的事务注册到事务管理者这里。
注册时带两个参数:
type:commit/rollBack
因为我们在wait的时候,其实已经知道我们的方法是提交还是回滚了;
groupId:事务是属于哪一个组。
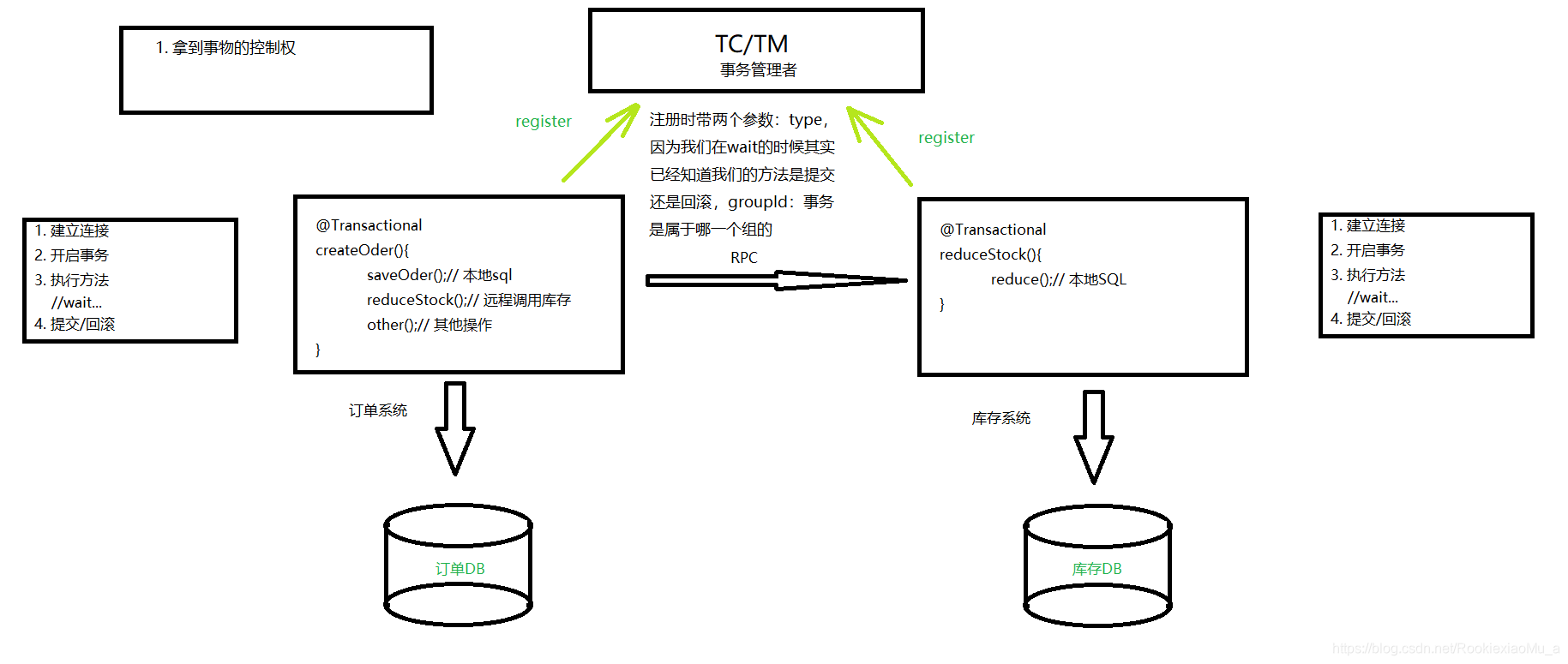
2. 拿到事务的控制权,控制commit/rollBack
第三:现在我们的事务管理者其实已经可以根据各个子事务的状态来判断我们的分布式事务到底是应该commit/rollBack了。
所以最后:
3. 告诉我们的子事务最后的操作:提交/回滚
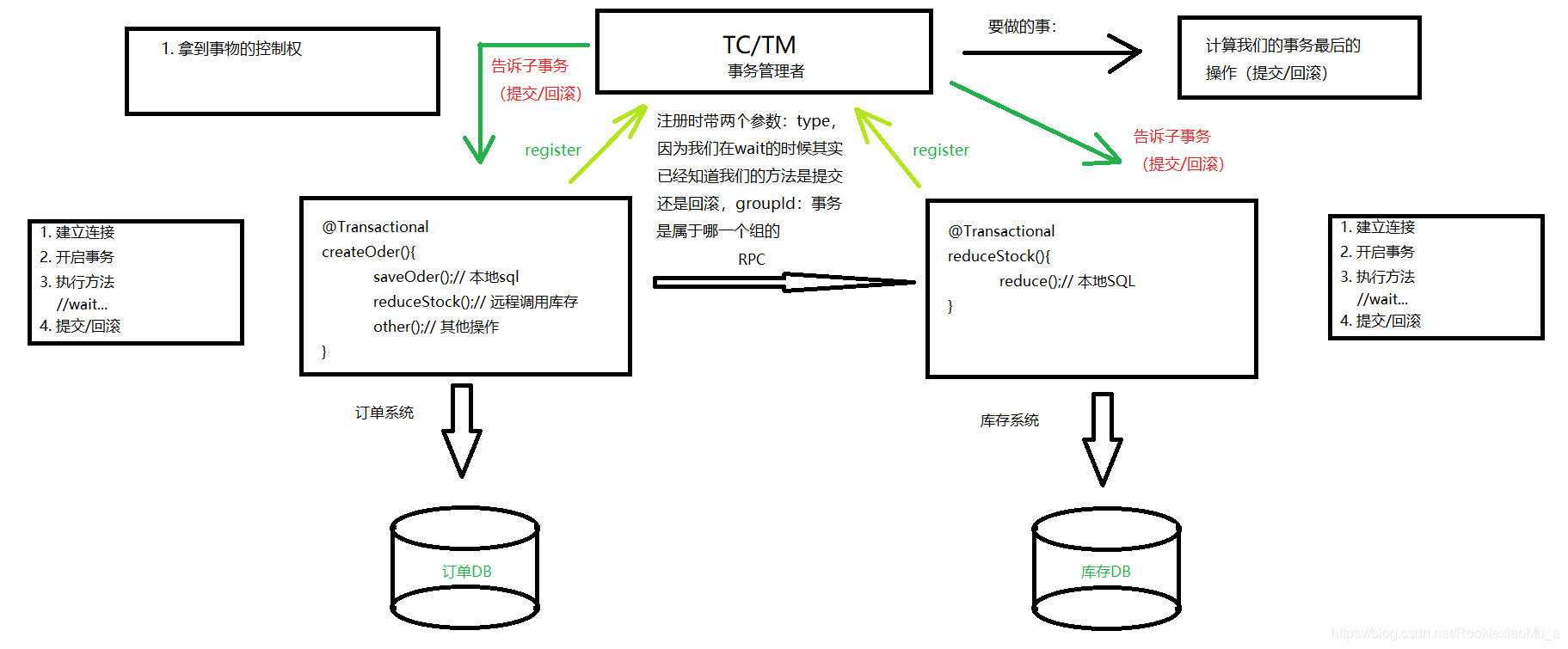
整体的思路就是这样的了…
Seata的基本思路也是这样子的…
7. Seata架构得与失
7.1 亮点
相比与其它分布式事务框架,Seata架构的亮点主要有几个:
应用层基于SQL解析实现了自动补偿,从而最大程度的降低业务侵入性;
将分布式事务中TC(事务协调者)独立部署,负责事务的注册、回滚;
通过全局锁实现了写隔离与读隔离。
分布式事务框架还有其他:TCC、ICN…
但TCC框架是侵入式的,而Seata不是侵入式的。
这些特性的具体实现机制其官网以及github上都有详细介绍,这里不展开介绍。
7.2 性能损耗
我们看看Seata增加了哪些开销(存内存运算类的忽略不纯计):
一条Update的SQL,则需要全局事务xid获取(与TC通讯)、before image(解析SQL,查询一次数据库)、after image(查询一次数据库)、insert undo log(写一次数据库)、before commit(与TC通讯,判断锁冲突),这些操作都需要一次远程通讯RPC,而且是同步的。另外undo log写入时blob字段的插入性能也是不高的。每条写SQL都会增加这么多开销,粗略估计会 增加5倍响应时间 (二阶段虽然是异步的,但其实也会占用系统资源,网络、线程、数据库)。
前后镜像如何生成? 通过druid解析SQL,然后复用业务SQL中的where条件,然后生成Select SQL执行。