Ŀ¼
1. ����
1.1.Ϊʲô��Ĭ�ϰ汾��ʹ����
2. ���ݽṹ
3. ���̷���
3.1 CMA����
3.1.1 ��ʽһ ����dts������
3.1.2 ��ʽ�� ���ݲ����������
3.2 CMA���ӵ�Buddy System
3.3 CMA����/�ͷ�
3.4 DMAʹ��
4.CMA����
4.1.�ŵ�
4.2.ȱ��
5.ΪʲôҪ����CMA
5.1.����CMA
5.1.1.���������
5.1.2. DMA���似��
5.1.3.���ӷ�����
6.CMA documentation file
7.���
8.�Ƽ��Ķ�
cma��ȫ�ƣ�contiguous memory allocation��,���ڴ��ʼ��ʱԤ��һ�������ڴ����������ڴ���Ƭ������ʱͨ������dma_alloc_contiguous�ӿڲ���gfpָ��Ϊ__GFP_DIRECT_RECLAIM��Ԥ�����ǿ������ڴ��з����������ڴ档
1. ����
Contiguous Memory Allocator, CMA�������ڴ�����������ڷ��������Ĵ���ڴ档
�����ڴ��������CMA����һ����ܣ�������Ϊ���������ڴ���������ض��ڼ���������á�Ȼ����ݸ����÷����豸���ڴ档�ÿ�ܵ���Ҫ���ò��Ƿ����ڴ棬���ǽ��������ڴ����ã����䵱�豸��������Ϳɲ�η�����֮����н顣��ˣ������������κ��ڴ���䷽������ԡ�
Ƕ��ʽϵͳ�ϵĸ����豸��֧��ɢ��ͼ��/��IOӳ�䣬�����Ҫ�������ڴ��������С����ǰ��������Ӳ����Ƶ�������ͱ��������豸�������豸ͨ����Ҫ����ڴ滺���������磬ȫ����֡�Ĵ�С����2�����أ������ڴ��С����6 MB������ʹ��kmalloc����֮��Ļ�����Ч��һЩǶ��ʽ�豸�Ի���������˶����Ҫ�����磬����ֻ���ڷ�����ض�λ��/�ڴ�⣨���ϵͳ���ж���ڴ�⣩�Ļ����������ض��ڴ�߽����Ļ����������С�Ƕ��ʽ�豸�Ŀ�����������˺ܴ����������������V4L���������������������������Լ����ڴ������롣�����еĴ����ʹ�û���bootmem�ķ�����
CMA����������ReserveһƬ�����ڴ�����
- �豸��������ʱ���ڴ����ϵͳ�����������ڷ���������ƶ�����ҳ�棻
- �豸����ʹ��ʱ�����������ڴ���䣬��ʱ�Ѿ������ҳ����Ҫ����Ǩ�ƣ�
���⣬CMA��������������DMA��ϵͳ������һ����ʹ��DMA���豸������������ʹ�õ�����CMA API��

���㶮Linux�㿽����DMA��https://rtoax.blog.csdn.net/article/details/108825666
��ARM SMMUԭ����IOMMU��������VT-d�� DMA��I/O���⻯���ڴ����⻯����
1.1.Ϊʲô��Ĭ�ϰ汾��ʹ����
�����i.MX SoC��û������ض�IP��IOMMU��������Ҫ�ϴ�������ڴ������в���������VPU / GPU / ISI / CSI������������IOMMU����������ȴ����ô������Ĭ�ϵ�i.MX BSP�У�������ȻΪ��ЩIP��������������������ڴ棬�Խ���DMA���䡣
��arm64�ں��У�DMA����API���Ը��ַ�ʽ�����ڴ棬����ȡ�����豸���ã���dts��gfp��־�У����±���ʾ��DMA����API������IOMMU���豸����ι������ҵ���ȷ��ҳ�淽ʽ����˳�������-> CMA->����-> SWIOTLB����
| Allocator (by order) | Configurations (w/o IOMMU) | Comments | Mapping |
|---|---|---|---|
| Coherent Pool |
|
By __alloc_from_pool() | Already mapped on boot when coherent pool init in VMALLOC |
| CMA |
|
By cma_alloc() | map_vm_area, mapped in VMALLOC |
| Buddy |
|
By __get_free_pages(), which can only allocate from the DMA/normal zone (lowmem), 32bits address spaces | Already mapped in the lowmem area by kernel on boot |
| SWIOTLB |
|
By map_single() | Already mapped on boot when SWIOTLB init |
����һ�£�
| �����ߣ��������� | ���ã�����IOMMU�� | ע������ | ӳ�� |
|---|---|---|---|
| ��ɳ�Coherent Pool |
|
ͨ��__alloc_from_pool���� | ��VMALLOC�н�����سس�ʼ��ʱ��������ʱӳ�� |
| CMA |
|
ͨ��cma_alloc���� | map_vm_area����VMALLOC��ӳ�� |
| ���Buddy |
|
ͨ��ֻ�ܴ�DMA /��������lowmem�������__get_free_pages����������ʹ��32λ��ַ�ռ� | ����ʱ�Ѿ����ں�ӳ�䵽lowmem���� |
| SWIOTLB |
|
��map_single���� | SWIOTLB��ʼ��ʱ��������ʱӳ�� |
����ʾ�����Ĺ���ԭ����DMA����·������

Ĭ������£��ڴ��������£��ں�ʹ��CMA��ΪDMA����������ĺ�ˡ������Ϊʲôi.MX BSP��Ĭ�ϰ汾�н�CMA����GPU / VPU / CSI / ISI����������DMA����Ļ�������ԭ��
https://rtoax.blog.csdn.net/article/details/109558498

2. ���ݽṹ
�ں˶�����struct cma�ṹ�����ڹ���һ��CMA���������������ȫ�ֵ�cma���������£�
struct cma {unsigned long base_pfn;unsigned long count;unsigned long *bitmap;unsigned int order_per_bit; /* Order of pages represented by one bit */struct mutex lock;
#ifdef CONFIG_CMA_DEBUGFSstruct hlist_head mem_head;spinlock_t mem_head_lock;
#endifconst char *name;
};extern struct cma cma_areas[MAX_CMA_AREAS];
extern unsigned cma_area_count;base_pfn��CMA����������ַ����ʼҳ֡�ţ�count��CMA���������ҳ����*bitmap��λͼ����������ҳ�ķ��������order_per_bit��λͼ��ÿ��bit����������ҳ���orderֵ������ҳ����Ϊ2^orderֵ��
��һ��ͼ�ͻ��������ˣ�


3. ���̷���
3.1 CMA����
3.1.1 ��ʽһ ����dts������
֮ǰ������Ҳ���������������ڴ������������dts�У����ջ���ϵͳ���������У���dtb�ļ����н������Ӷ�����ڴ���Ϣע�ᡣ
CMA���ڴ���dts�е�����ʾ������ͼ��
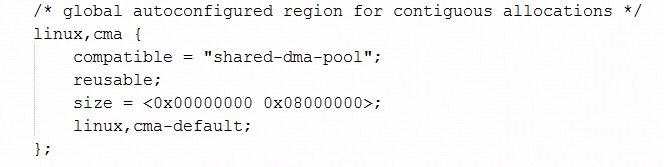
��dtb���������У�����õ�rmem_cma_setup������
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
3.1.2 ��ʽ�� ���ݲ����������
����ͨ���ں˲��������ú꣬������CMA����Ĵ��������ջ���õ�cma_declare_contiguous����������ͼ��

3.2 CMA���ӵ�Buddy System
�ڴ�����CMA�������ڴ�������˱��������������������ʹ�ã���Ȼ������ڴ���˷ѣ�����ڴ����ģ��ὫCMA�������ӵ�Buddy System�У����ڿ��ƶ�ҳ��ķ��������CMA������ͨ��cma_init_reserved_areas�ӿ������ӵ�Buddy System�еġ�
core_initcall(cma_init_reserved_areas);
core_initcall�꽫cma_init_reserved_areas�������õ��ض��Ķ��У���ϵͳ������ʱ�����õ��ú�����

3.3 CMA����/�ͷ�
CMA���䣬��ں���Ϊcma_alloc��

CMA�ͷţ���ں���Ϊcma_release�������Ƚϼ�ֱ�����ϴ���
/*** cma_release() - release allocated pages* @cma: Contiguous memory region for which the allocation is performed.* @pages: Allocated pages.* @count: Number of allocated pages.** This function releases memory allocated by alloc_cma().* It returns false when provided pages do not belong to contiguous area and* true otherwise.*/
bool cma_release(struct cma *cma, const struct page *pages, unsigned int count)
{unsigned long pfn;if (!cma || !pages)return false;pr_debug("%s(page %p)\n", __func__, (void *)pages);pfn = page_to_pfn(pages);if (pfn < cma->base_pfn || pfn >= cma->base_pfn + cma->count)return false;VM_BUG_ON(pfn + count > cma->base_pfn + cma->count);free_contig_range(pfn, count);cma_clear_bitmap(cma, pfn, count);trace_cma_release(pfn, pages, count);return true;
}3.4 DMAʹ��
����ο�driver/base/dma-contiguous.c����Ҫ�����Ľӿ��У�
/*** dma_alloc_from_contiguous() - allocate pages from contiguous area* @dev: Pointer to device for which the allocation is performed.* @count: Requested number of pages.* @align: Requested alignment of pages (in PAGE_SIZE order).* @gfp_mask: GFP flags to use for this allocation.** This function allocates memory buffer for specified device. It uses* device specific contiguous memory area if available or the default* global one. Requires architecture specific dev_get_cma_area() helper* function.*/
struct page *dma_alloc_from_contiguous(struct device *dev, size_t count,unsigned int align, gfp_t gfp_mask);/*** dma_release_from_contiguous() - release allocated pages* @dev: Pointer to device for which the pages were allocated.* @pages: Allocated pages.* @count: Number of allocated pages.** This function releases memory allocated by dma_alloc_from_contiguous().* It returns false when provided pages do not belong to contiguous area and* true otherwise.*/
bool dma_release_from_contiguous(struct device *dev, struct page *pages,int count);�������Ľӿ��У�ʵ�ʵ��õľ���cma_alloc/cma_release�ӿ���ʵ�ֵġ�
����������CMA���������DZȽϼ�����Ҳ�������������
4.CMA����
4.1.�ŵ�
- ������ƣ���ʹ���ڴ���Ƭ�����Ҳ�����ڴ��������ڴ���䡣
- CMA�е�ҳ������ɻ��ϵͳ�����������DZ����ع���
- �������ض����豸��CMA�����ɸ��豸ʹ�ò���ϵͳ����
- �������±����ں˼���������������������ַ�ʹ�С
4.2.ȱ��
- ��ҪǨ��ҳ��ʱ������̱���
- ���ױ�ϵͳ�ڴ�����ƻ�����ϵͳ�ڴ治��ʱ���ͻ����ܻ�����cma_alloc���ϣ������ǰ̨Ӧ�ó�����Ҫͼ�λ�����������Ⱦ��RVCϣ������������CAR����ʱ���²������û����顣
- ��cma_alloc������ҪǨ��ijЩҳ��ʱ�Կ��ܳ�������������Щҳ������ˢ�µ��洢�У���FUSE�ļ�ϵͳ�ڻ�д·������һҳʱ��ijЩ�ͻ��Ѿ���������������cma_allocϣ��Ǩ�����������DZ�д���ĵ������������
5.ΪʲôҪ����CMA
�����RED Cons�������ؼ���Ϊ�ؼ��ķ���·��������GPUͼ�λ������������/ VPUԤ��/��¼�������������ڴ棬�Է�ֹ����ʧ�ܶ��������õ��û����飬����ʧ�ܻᵼ�º�����Ԥ�������ȡ� CMA��FUSEһ������
5.1.����CMA
Ҫ����CMA������˼������DMA�������ж�CMA��ʽ��ת����ɳأ�ԭ�ӳأ�����ע�⣬�����ֻ����DMA����APIʹ�ã���������ϵͳ��鹲����
5.1.1.���������
�������������ӡ� coherent_pool = <size>����Coherent��ʵ�����Ǵ�ϵͳĬ��CMA����ģ����CMA size> coherent_pool��
�˴�Сû�вο�����Ϊ��ϵͳ��ϵͳ�Լ��������������в�ͬ��
- DMA�������������GPU����ʹ���������ͨ��gmem_info���߽��м�ء��ڵ��͵������¼���gmem_info����ȷ��GPU������ڴ档
- ���DMA�ĵڶ���ʹ���ߣ�ISI /�����ȡ����V4l2 reqbuf�Ĵ�С������
- ���VPU��ȡ���ڶ�ý����
- ����alsa snd��USB��fecʹ��
����ͨ��������֤��С����ȷ��ϵͳ�ȶ���
5.1.2. DMA���似��
����arch / arm64 / mm / dma-mapping.c����__dma_alloc����������ɾ��gfpflags_allow_blocking��飺
diff --git a/arch/arm64/mm/dma-mapping.c b/arch/arm64/mm/dma-mapping.c
index 7015d3e..ef30b46 100644
--- a/arch/arm64/mm/dma-mapping.c
+++ b/arch/arm64/mm/dma-mapping.c
@@ -147,7 +147,7 @@ static void *__dma_alloc(struct device *dev, size_t size,size = PAGE_ALIGN(size);- if (!coherent && !gfpflags_allow_blocking(flags)) {
+ if (!coherent) { // && !gfpflags_allow_blocking(flags)) {
struct page *page = NULL;
void *addr = __alloc_from_pool(size, &page, flags);
5.1.3.���ӷ�����
��Android��Yocto�汾�У�ION��������Android��ʱ������������VPU����������Ĭ�Ͻ���ION CMA�ѡ�����ζ��ION�������ڴ������ֱ�ӷ���CMA��Ϊ�˱���CMA�����ǿ�����ION��ʹ�÷ָ��ջ������CMA��ջ��
5.1.3.1��
����CARVEOUT�ѣ�����CMA�ѣ�
CONFIG_ION = y
CONFIG_ION_SYSTEM_HEAP = y
-CONFIG_ION_CMA_HEAP = y
+ CONFIG_ION_CARVEOUT_HEAP = y
+ CONFIG_ION_CMA_HEAP = n��dts�е����ָ���Ķѻ���ַ�ʹ�С��
/ {reserved-memory {#address-cells = <2>;#size-cells = <2>;ranges;carveout_region: imx_ion@0 {compatible = "imx-ion-pool";reg = <0x0 0xf8000000 0 0x8000000>;};};
};5.1.3.2 Linux
- �ں�-�����i.MX8QM���渽��������Linux������ͬ������Ҫ��ION��������������������
- Gstreamer-Ӧ�����²����ӷ����з��䣺
yocto / build-8qm / tmp / work / aarch64-mx8-poky-linux / gstreamer1.0-plugins-base / 1.14.4.imx-r0 / git��
diff --git a/gst-libs/gst/allocators/gstionmemory.c b/gst-libs/gst/allocators/gstionmemory.c
index 1218c4a..12e403d 100644
--- a/gst-libs/gst/allocators/gstionmemory.c
+++ b/gst-libs/gst/allocators/gstionmemory.c
@@ -227,7 +227,8 @@ gst_ion_alloc_alloc (GstAllocator * allocator, gsize size,}for (gint i=0; i<heapCnt; i++) {
- if (ihd[i].type == ION_HEAP_TYPE_DMA) {
+ if (ihd[i].type == ION_HEAP_TYPE_DMA ||
+ ihd[i].type == ION_HEAP_TYPE_CARVEOUT) {heap_mask |= 1 << ihd[i].heap_id;}}
6.CMA documentation file
https://lwn.net/Articles/396707/
* Contiguous Memory AllocatorThe Contiguous Memory Allocator (CMA) is a framework, which allowssetting up a machine-specific configuration for physically-contiguousmemory management. Memory for devices is then allocated accordingto that configuration.The main role of the framework is not to allocate memory, but toparse and manage memory configurations, as well as to act as anin-between between device drivers and pluggable allocators. It isthus not tied to any memory allocation method or strategy.** Why is it needed?Various devices on embedded systems have no scatter-getter and/orIO map support and as such require contiguous blocks of memory tooperate. They include devices such as cameras, hardware videodecoders and encoders, etc.Such devices often require big memory buffers (a full HD frame is,for instance, more then 2 mega pixels large, i.e. more than 6 MBof memory), which makes mechanisms such as kmalloc() ineffective.Some embedded devices impose additional requirements on thebuffers, e.g. they can operate only on buffers allocated inparticular location/memory bank (if system has more than onememory bank) or buffers aligned to a particular memory boundary.Development of embedded devices have seen a big rise recently(especially in the V4L area) and many such drivers include theirown memory allocation code. Most of them use bootmem-based methods.CMA framework is an attempt to unify contiguous memory allocationmechanisms and provide a simple API for device drivers, whilestaying as customisable and modular as possible.** DesignThe main design goal for the CMA was to provide a customisable andmodular framework, which could be configured to suit the needs ofindividual systems. Configuration specifies a list of memoryregions, which then are assigned to devices. Memory regions canbe shared among many device drivers or assigned exclusively toone. This has been achieved in the following ways:1. The core of the CMA does not handle allocation of memory andmanagement of free space. Dedicated allocators are used forthat purpose.This way, if the provided solution does not match demandsimposed on a given system, one can develop a new algorithm andeasily plug it into the CMA framework.The presented solution includes an implementation of a best-fitalgorithm.2. CMA allows a run-time configuration of the memory regions itwill use to allocate chunks of memory from. The set of memoryregions is given on command line so it can be easily changedwithout the need for recompiling the kernel.Each region has it's own size, alignment demand, a startaddress (physical address where it should be placed) and anallocator algorithm assigned to the region.This means that there can be different algorithms running atthe same time, if different devices on the platform havedistinct memory usage characteristics and different algorithmmatch those the best way.3. When requesting memory, devices have to introduce themselves.This way CMA knows who the memory is allocated for. Thisallows for the system architect to specify which memory regionseach device should use.3a. Devices can also specify a "kind" of memory they want.This makes it possible to configure the system in sucha way, that a single device may get memory from differentmemory regions, depending on the "kind" of memory itrequested. For example, a video codec driver might want toallocate some shared buffers from the first memory bank andthe other from the second to get the highest possiblememory throughput.** Use casesLets analyse some imaginary system that uses the CMA to see howthe framework can be used and configured.We have a platform with a hardware video decoder and a camera eachneeding 20 MiB of memory in worst case. Our system is written insuch a way though that the two devices are never used at the sametime and memory for them may be shared. In such a system thefollowing two command line arguments would be used:cma=r=20M cma_map=video,camera=rThe first instructs CMA to allocate a region of 20 MiB and use thefirst available memory allocator on it. The second, that driversnamed "video" and "camera" are to be granted memory from thepreviously defined region.We can see, that because the devices share the same region ofmemory, we save 20 MiB of memory, compared to the situation wheneach of the devices would reserve 20 MiB of memory for itself.However, after some development of the system, it can now runvideo decoder and camera at the same time. The 20 MiB region isno longer enough for the two to share. A quick fix can be made togrant each of those devices separate regions:cma=v=20M,c=20M cma_map=video=v;camera=cThis solution also shows how with CMA you can assign private poolsof memory to each device if that is required.Allocation mechanisms can be replaced dynamically in a similarmanner as well. Let's say that during testing, it has beendiscovered that, for a given shared region of 40 MiB,fragmentation has become a problem. It has been observed that,after some time, it becomes impossible to allocate buffers of therequired sizes. So to satisfy our requirements, we would have toreserve a larger shared region beforehand.But fortunately, you have also managed to develop a new allocationalgorithm -- Neat Allocation Algorithm or "na" for short -- whichsatisfies the needs for both devices even on a 30 MiB region. Theconfiguration can be then quickly changed to:cma=r=30M:na cma_map=video,camera=rThis shows how you can develop your own allocation algorithms ifthe ones provided with CMA do not suit your needs and easilyreplace them, without the need to modify CMA core or evenrecompiling the kernel.** Technical Details*** The command line parametersAs shown above, CMA is configured from command line via twoarguments: "cma" and "cma_map". The first one specifies regionsthat are to be reserved for CMA. The second one specifies whatregions each device is assigned to.The format of the "cma" parameter is as follows:cma ::= "cma=" regions [ ';' ]regions ::= region [ ';' regions ]region ::= reg-name'=' size[ '@' start ][ '/' alignment ][ ':' [ alloc-name ] [ '(' alloc-params ')' ] ]reg-name ::= a sequence of letters and digits// name of the regionsize ::= memsize // size of the regionstart ::= memsize // desired start address of// the regionalignment ::= memsize // alignment of the start// address of the regionalloc-name ::= a non-empty sequence of letters and digits// name of an allocator that will be used// with the regionalloc-params ::= a sequence of chars other then ')' and ';'// optional parameters for the allocatormemsize ::= whatever memparse() acceptsThe format of the "cma_map" parameter is as follows:cma-map ::= "cma_map=" rules [ ';' ]rules ::= rule [ ';' rules ]rule ::= patterns '=' regionspatterns ::= pattern [ ',' patterns ]regions ::= reg-name [ ',' regions ]// list of regions to try to allocate memory// from for devices that match patternpattern ::= dev-pattern [ '/' kind-pattern ]| '/' kind-pattern// pattern request must match for this rule to// apply to it; the first rule that matches is// applied; if dev-pattern part is omitted// value identical to the one used in previous// pattern is assumeddev-pattern ::= pattern-str// pattern that device name must match for the// rule to apply.kind-pattern ::= pattern-str// pattern that "kind" of memory (provided by// device) must match for the rule to apply.pattern-str ::= a non-empty sequence of characters with '?'meaning any character and possible '*' atthe end meaning to match the rest of thestringSome examples (whitespace added for better readability):cma = r1 = 64M // 64M region@512M // starting at address 512M// (or at least as near as possible)/1M // make sure it's aligned to 1M:foo(bar); // uses allocator "foo" with "bar"// as parameters for itr2 = 64M // 64M region/1M; // make sure it's aligned to 1M// uses the first available allocatorr3 = 64M // 64M region@512M // starting at address 512M:foo; // uses allocator "foo" with no parameterscma_map = foo = r1;// device foo with kind==NULL uses region r1foo/quaz = r2; // OR:/quaz = r2;// device foo with kind == "quaz" uses region r2foo/* = r3; // OR:/* = r3;// device foo with any other kind uses region r3bar/* = r1,r2;// device bar with any kind uses region r1 or r2baz?/a* , baz?/b* = r3;// devices named baz? where ? is any character// with kind being a string starting with "a" or// "b" use r3*** The device and kind of memoryThe name of the device is taken form the device structure. It isnot possible to use CMA if driver does not register a device(actually this can be overcome if a fake device structure isprovided with at least the name set).The kind of memory is an optional argument provided by the devicewhenever it requests memory chunk. In many cases this can beignored but sometimes it may be required for some devices.For instance, let say that there are two memory banks and forperformance reasons a device uses buffers in both of them. Insuch case, the device driver would define two kinds and use it fordifferent buffers. Command line arguments could look as follows:cma=a=32M@0,b=32M@512M cma_map=foo/a=a;foo/b=bAnd whenever the driver allocated the memory it would specify thekind of memory:buffer1 = cma_alloc(dev, 1 << 20, 0, "a");buffer2 = cma_alloc(dev, 1 << 20, 0, "b");If it was needed to try to allocate from the other bank as well ifthe dedicated one is full command line arguments could be changedto:cma=a=32M@0,b=32M@512M cma_map=foo/a=a,b;foo/b=b,aOn the other hand, if the same driver was used on a system withonly one bank, the command line could be changed to:cma=r=64M cma_map=foo/*=rwithout the need to change the driver at all.*** APIThere are four calls provided by the CMA framework to devices. Toallocate a chunk of memory cma_alloc() function needs to be used:unsigned long cma_alloc(const struct device *dev,const char *kind,unsigned long size,unsigned long alignment);If required, device may specify alignment that the chunk need tosatisfy. It have to be a power of two or zero. The chunks arealways aligned at least to a page.The kind specifies the kind of memory as described to in theprevious subsection. If device driver does not use notion ofmemory kinds it's safe to pass NULL as the kind.The basic usage of the function is just a:addr = cma_alloc(dev, NULL, size, 0);The function returns physical address of allocated chunk ora value that evaluated true if checked with IS_ERR_VALUE(), so thecorrect way for checking for errors is:unsigned long addr = cma_alloc(dev, size);if (IS_ERR_VALUE(addr))return (int)addr;/* Allocated */(Make sure to include <linux/err.h> which contains the definitionof the IS_ERR_VALUE() macro.)Allocated chunk is freed via a cma_put() function:int cma_put(unsigned long addr);It takes physical address of the chunk as an argument anddecreases it's reference counter. If the counter reaches zero thechunk is freed. Most of the time users do not need to think aboutreference counter and simply use the cma_put() as a free call.If one, however, were to share a chunk with others built inreference counter may turn out to be handy. To increment it, oneneeds to use cma_get() function:int cma_put(unsigned long addr);The last function is the cma_info() which returns informationabout regions assigned to given (dev, kind) pair. Its syntax is:int cma_info(struct cma_info *info,const struct device *dev,const char *kind);On successful exit it fills the info structure with lower andupper bound of regions, total size and number of regions assignedto given (dev, kind) pair.*** Allocator operationsCreating an allocator for CMA needs four functions to beimplemented.The first two are used to initialise an allocator far given driverand clean up afterwards:int cma_foo_init(struct cma_region *reg);void cma_foo_done(struct cma_region *reg);The first is called during platform initialisation. Thecma_region structure has saved starting address of the region aswell as its size. It has also alloc_params field with optionalparameters passed via command line (allocator is free to interpretthose in any way it pleases). Any data that allocate associatedwith the region can be saved in private_data field.The second call cleans up and frees all resources the allocatorhas allocated for the region. The function can assume that allchunks allocated form this region have been freed thus the wholeregion is free.The two other calls are used for allocating and freeing chunks.They are:struct cma_chunk *cma_foo_alloc(struct cma_region *reg,unsigned long size,unsigned long alignment);void cma_foo_free(struct cma_chunk *chunk);As names imply the first allocates a chunk and the other freesa chunk of memory. It also manages a cma_chunk objectrepresenting the chunk in physical memory.Either of those function can assume that they are the only threadaccessing the region. Therefore, allocator does not need to worryabout concurrency.When allocator is ready, all that is left is register it by addinga line to "mm/cma-allocators.h" file:CMA_ALLOCATOR("foo", foo)The first "foo" is a named that will be available to use withcommand line argument. The second is the part used in functionnames.*** Integration with platformThere is one function that needs to be called form platforminitialisation code. That is the cma_regions_allocate() function:void cma_regions_allocate(int (*alloc)(struct cma_region *reg));It traverses list of all of the regions given on command line andreserves memory for them. The only argument is a callbackfunction used to reserve the region. Passing NULL as the argumentmakes the function use cma_region_alloc() function which usesbootmem for allocating.Alternatively, platform code could traverse the cma_regions arrayby itself but this should not be necessary.The If cma_region_alloc() allocator is used, thecma_regions_allocate() function needs to be allocated when bootmemis active.Platform has also a way of providing default cma and cma_mapparameters. cma_defaults() function is used for that purpose:int cma_defaults(const char *cma, const char *cma_map)It needs to be called after early params have been parsed butprior to allocating regions. Arguments of this function are usedonly if they are not-NULL and respective command line argument wasnot provided.** Future workIn the future, implementation of mechanisms that would allow thefree space inside the regions to be used as page cache, filesystembuffers or swap devices is planned. With such mechanisms, thememory would not be wasted when not used.Because all allocations and freeing of chunks pass the CMAframework it can follow what parts of the reserved memory arefreed and what parts are allocated. Tracking the unused memorywould let CMA use it for other purposes such as page cache, I/Obuffers, swap, etc.
7.���
�ڴ�����ķ����ȸ�һ���䣬�������ܻ������ijЩģ���һ�����о������ơ�
�ڴ������ϵͳ�����临�ӣ��̸����ڣ���������Ȧ�ˣ����ܷ��˲���������Ҳֻ��˵��֪Ƥë��
ѧϰ��������ɽ�����һ����ɽ�����ܻ��������ϰ������ǵ����Խ֮���ٿ���ͬ���ߵ�ɽ���������㽫����η�塣
���������о����̹�����ϵͳ�����ζ�������ͨ��
δ������������ں��еĸ����ܣ��������Ƶȣ������ע��һ��̽�֡�
https://www.cnblogs.com/LoyenWang/p/12182594.html
8.�Ƽ��Ķ�
���㶮Linux�㿽����DMA��https://rtoax.blog.csdn.net/article/details/108825666
��ARM SMMUԭ����IOMMU��������VT-d�� DMA��I/O���⻯���ڴ����⻯����
��ֱ���ڴ���� (Direct Memory Access, DMA)��
��[Linux Device Drivers, 2nd Edition] mmap��DMA��
��arm64/hugetlb: Reserve CMA areas for gigantic pages on 16K and 64K configs��
���� Aarch64 Linux�ں��ڴ��������
���� CMA�ĵ�����
������CMA��
��Aarch64 Kernel Memory Management��
��Linux�ڴ������ʲô��CMA��contiguous memory allocation��������DMA���ʹ�á�