目录
文章总览
《Linux操作系统实时性分析》
《内存管理的另辟蹊径 - 腾讯云虚拟化开源团队为内核引入全新虚拟文件系统(dmemfs)》
《刨根问底儿,看我如何处理 Too many open files 错误!》
《Linux Containers》
《一次解决Linux内核内存泄漏实战全过程》
文章总览
- 《Redis为什么要分16个库》https://mp.weixin.qq.com/s/A5jOgFL42hXHkxe299G-sg
- 《Linux操作系统实时性分析》https://w.cnblogs.com/h2zZhou/p/8513014.html
- 《云计算之linux调优_tuned调优》https://blog.csdn.net/mx_steve/article/details/100558608
- 《Product Documentation for Red Hat Enterprise Linux for Real Time 7》https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/
- 《TUNING GUIDE》https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/html/tuning_guide/index
- 《Introduction to RDMA (Remote Direct Memory Access)[MiniTool Wiki] 》https://www.minitool.com/lib/rdma.html
- 《NETWORKING GUIDE》https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/index
- 《用于Linux的NUMA API.pdf》http://www.halobates.de/numaapi3.pdf
- 《HOWTO: Build an RT-application》https://rt.wiki.kernel.org/index.php/HOWTO:_Build_an_RT-application
- 《Red Hat Enterprise Linux for Real Time参考指南》https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/html-single/reference_guide/
- 《内存管理的另辟蹊径 - 腾讯云虚拟化开源团队为内核引入全新虚拟文件系统(dmemfs)》https://mp.weixin.qq.com/s/DmoUynuyI8Wdwa_6kixgjw
- 《刨根问底儿,看我如何处理 Too many open files 错误!》https://mp.weixin.qq.com/s/GBn94vdL4xUL80WYrGdUWQ
- 《《高效入门eBPF》直播背后的有趣故事》https://mp.weixin.qq.com/s/CvLHdUhQtcqXrVMImtkAqg
- 《IP协议源码分析》https://mp.weixin.qq.com/s/8WNcTxtD4DBcNtcrR8nz4Q
- 本站地址《Linux TCP/IP网络协议栈:IP协议源码分析》https://rtoax.blog.csdn.net/article/details/113818814
- 《Linux Containers》https://wiki.archlinux.org/index.php/Linux_Containers
- 《实时红帽企业LINUX7参考指南》https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/html/reference_guide/index
- 资源:《CentOSLinux实时性配置要点翻译总结.pdf》https://download.csdn.net/download/Rong_Toa/15296983
- 《红帽Redhat网络功能虚拟化产品指南、规划和配置指南》https://rtoax.blog.csdn.net/article/details/113782760,https://access.redhat.com/documentation/en-us/
- 《一次解决Linux内核内存泄漏实战全过程》https://mp.weixin.qq.com/s/RafQUmblVX69zegDWQUcew
- 《内存管理之kmap vmap ioremap》https://mp.weixin.qq.com/s/Ka7Agm_voduy2-_eIJQe7g
- 《Linux内存管理之vmap与vmalloc》https://www.cnblogs.com/LoyenWang/p/11965787.html
- 本站转载地址《linux内存管理:kmap、vmap、ioremap》https://rtoax.blog.csdn.net/article/details/113818966
- 《NAT技术之源NAT-想上网少不了它(网络地址转换,解决IP资源紧缺问题)》https://mp.weixin.qq.com/s/aFibK-eVxzW_nla6Ep-Ssw
- 《Linux虚拟化KVM-Qemu分析(九)之virtio设备》https://mp.weixin.qq.com/s/DphwLpAZe0OXgybnRY-siA
- 《Virtio 网络的演化之路》https://mp.weixin.qq.com/s/xRVDVn2EkQjHR7b-XpDMBw
《Linux操作系统实时性分析》
https://w.cnblogs.com/h2zZhou/p/8513014.html
1. 概述
选择一个合适的嵌入式操作系统,可以考虑以下几个因素:
第一是应用。如果你想开发的嵌入式设备是一个和网络应用密切相关或者就是一个网络设备,那么你应该选择用嵌入式Linux或者uCLinux,而不是uC/OS-II。
第二是实时性。没有一个绝对的数字可以告诉你什么是硬实时,什么是软实时,他们之间的界限也是十分模糊的,这与你选择什么样的CPU,它的主频、内存等参数有一定关系。如果你使用加入实时补丁等技术的嵌入式Linux,如Monta Vista Linux(2.4.17版本),最坏的情况只有436微秒,而99.9%的情况是195微秒以内。考虑到最新的Linux在实时性方面的改进,它可以适合于90~95%的各种嵌入式系统应用。当然,你如果希望更快的实时响应,如高速A/D转换需要几个微秒以内的中断延时,可能采用uC/OS-II是合适的。当然,采用像Vxworks这样传统的嵌入式操作系统也可以满足这样的强实时性要求。
2. 为什么选择Linux操作系统
Linux系统作为一个GPOS(通用操作系统)发展至今已经非常成熟可靠了,并且由于遵循GPL协议,开放所有系统源代码,非常易于裁剪。更重要的是,与其他开源的GPOS或RTOS相比,Linux系统支持多种处理器、开发板,提供多种软件开发工具,同时Linux系统对网络和图形界面的支持非常出色。显然,选择Linux操作系统在产品的开发周期和成本控制方面都有巨大优势。
凭借经济和技术方面的诸多优势,Linux正被越来越多的嵌入式设备所使用。Linux在嵌入式系统市场的占用率越来越高,以下是大部分产品选择Linux系统的原因:
- Linux支持的硬件设备种类繁多。
- Linux支持非常多的应用程序和网络协议。
- Linux的扩展性很好,从小型的消费电子产品到大型、笨重的电信级交换机和路由器都可以采用Linux。
- 和传统的专有嵌入式操作系统不同,部署Linux不需要缴纳专利费。
- Linux吸引了为数众多的活跃的开发者,能很快支持新的硬件架构、平台和设备。
- 越来越多的硬件和软件厂商,包括几乎所有的顶级芯片制造商和独立软件开发商,现在都支持Linux。
3. 什么是实时
实时系统的典型定义如下:“所谓实时系统,就是系统中计算结果的正确性不仅取决于计算逻辑的正确性,还取决于产生结果的时间。如果完成时间不符合要求,则可以说系统发生了问题。”也就是说,不管实时应用程序进行的是何种任务,它不仅需要正确进行该任务而且还必须及时完成它。
人们很容易对实时产生误解,认为实时即速度足够快,实际上,实时并不意味着速度快。实时的关键在于保证完成时间,而不在于原始速度,因为速度性能与硬件相关,可以通过搭建快速硬件平台(处理器、存储器子系统等)来获得所需的性能。而实时的行为是一个软件问题,其目标是让关键的操作能够在所保证的时间之内完成。
实时进程不会影响自己在执行环境中的调度,反而是环境影响实时应用程序的调度。也就是说,实时进程通常和某个物理事件相关联,比如外围设备的中断。那么显然,影响实时的原因在于中断响应延时,在Linux系统中可细分为中断延时、中断处理、调度延时。一般来说,针对用户对超出时间限制所造成的影响的可接受程度,实时又可分为软实时和硬实时。
3.1 软实时
大多数人都同意软实时意味着操作有时间限制。如果超过了时间限制后操作还没有完成的话,体验的质量就会下降,但不会带来致命后果。桌面工作站就是一个需要软实时功能的绝好例子。编辑文档时,你期望在按键之后立刻在屏幕上看到结果。在播放MP3文件时,你期望听到没有任何杂音、爆音或中断的高品质音乐。如果这些所谓的软实时事件错过了时限,结果可能不尽如人意,并导致体验的质量有所下降,但这并不是灾难性的。
3.2 硬实时
硬实时的特点是错过时限会造成严重结果。在一个硬实时系统中,如果错过了时限,后果往往是灾难性的。当然,“灾难”是相对而言的。但如果你的嵌入式设备正在控制喷气式飞机引擎的燃料流,而它没有能够及时响应飞行员输入的命令或操作特性的变化,致命后果就不可避免了。
这里,我们总结一下软实时和硬实时的定义。对于软实时系统,如果错过了时限,系统的计算值或结果会不太理想。然而,对于硬实时系统,如果错过了某个时限,系统就是失败的,而且可能会造成灾难性的后果。
4. 制约标准Linux操作系统实时性的因素
虽然Linux系统功能强大、实用性强、易于软件的二次开发,并且提供编程人员熟悉的标准API。但是由于Linux系统一开始就被设计成GPOS(通用操作系统),它的目的是构建一个完整、稳定的开源操作系统,尽量缩短系统的平均响应时间,提高吞吐量,注重操作系统的整体功能需求,达到更好地平均性能。(在操作系统中,我们可以把吞吐量简单的理解为在单位时间内系统能够处理的事件总数。)
因此在设计Linux的进程调度算法时主要考虑的是公平性,也就是说,调度器尽可能将可用的资源平均分配给所有需要处理器的进程,并保证每个进程都得以运行。但这个设计目标是和实时进程的需求背道而驰的,所以标准Linux并不提供强实时性。
Linux系统实时性不强使其在嵌入式应用中有一定的局限性,主要是受内核可抢占性、进程调度方式、中断处理机制、时钟粒度等几个方面的制约,具体如下:
(1) 进程调度
Linux系统提供符合POSIX标准的调度策略,包括FIFO调度策略(SCHED_FIFO)、带时间片轮转的实时调度策略(SCHED_RR)和静态优先级抢占式调度策略(SCHED_OTHER)。Linux进程默认的调度策略为SCHED_OTHER,这种调度方式虽然可以让进程公平地使用CPU和其它资源,但是并不能保证对时间要求严格或者高优先级的进程将先于低优先级的执行,这将严重影响系统实时性。那么,将实时进程的调度策略设置为SCHED_FIFO 或SCHED_RR ,似乎使得Linux系统具备根据进程优先级进行实时调度的能力,但问题在于,Linux系统在用户态支持可抢占调度策略,而在内核态却不完全支持抢占式调度策略。这样运行在Linux内核态的任务(包括系统调用和中断处理)是不能被其它优先级更高的任务所抢占的,由此引起优先级逆转问题。
(2) 内核抢占机制
Linux的系统进程运行分为用户态和内核态两种模式。当进程运行在用户态时,具有高的优先级的进程可以抢占进程,可以较好地完成任务;但是当进程运行在内核态时,即使其他高优先级进程也不能抢占该进程。当进程通过系统调用进入内核态运行时,实时任务必须等待系统调用返回后才能获得系统资源。这和实时系统所要求的高优先级任务运行是相互矛盾的。
当然,这种情况在Linux2.6版本的内核发布以来有了显著改进,Linux2.6版本后的内核是抢占式的,这意味着进程无论在处于内核态还是用户态,都可能被抢占。Linux2.6以后的内核提供以下3种抢占模式供用户选择。
PREEMPT_NONE――没有强制性的抢占。整体的平均延时较低,但偶尔也会出现一些较长的延时。它最适合那些以整体吞吐率为首要设计准则的应用。
PREEMPT_VOLUNTARY――降低延时的第一阶段。它会在内核代码的一些关键位置上放置额外的显示抢占点,以降低延时。但这是以牺牲整体吞吐率为代价的。
PREEMPT/PREEMPT_DESKTOP――这种模式使内核在任何地方都是可抢占的,临界区除外。这种模式适用于那些需要软实时性能的应用程序,比如音频和多媒体。这也是以牺牲整体吞吐率为代价的。
(3) 中断屏蔽
Linux在进行中断处理时都会关闭中断,这样可以更快、更安全地完成自己的任务,但是在此期间,即使有更高优先级的实时进程发生中断,系统也无法响应,必须等到当前中断任务处理完毕。这种状况下会导致中断延时和调度延时增大,降低Linux系统的实时性。
(4) 时钟粒度粗糙
时钟系统是计算机的重要组成部分,相当于整个操作系统的脉搏。系统所能提供的最小时间间隔称为时钟粒度,时钟粒度与进程响应的延迟性是正比关系,即粒度越粗糙,延迟性越长。但时钟粒度并不是越小越好,就同等硬件环境而言,较小的时间粒度会导致系统开销增大,降低整体吞吐率。在Linux2.6内核中,时钟中断发生频率范围是50~1200Hz,周期不小于0.8ms,对于需要几十微秒的响应精度的应用来说显然不满足要求。而在嵌入式Linux系统中,为了提高整体吞吐率,时钟频率一般设置为100HZ或250HZ。
另外,系统时钟负责软定时,当软定时器逐渐增多时会引起定时器冲突,增加系统负荷。
(5) 虚拟内存管理
Linux采用虚拟内存技术,进程可以运行在比实际空间大得多的虚拟空间中。在分时系统中,虚拟内存机制非常适用,然而对于实时系统这是难以忍受的,频繁的页面换进换出会使得系统进程运行无法在规定时间内完成。
对于此问题,Linux系统提供内存锁定功能,以避免在实时处理中存储页被换出。
(6) 共享资源的互斥访问差异
多个任务互斥地访问同一共享资源时,需要防止数据遭到破坏,系统通常采用信号量机制解决互斥问题。然而,在采取基于优先级调度的实时系统中,信号量机制容易造成优先级倒置,即低优先级任务占用高优先级任务资源,导致高优先级任务无法运行。
虽然从2.6.12版本之后,Linux内核已经可以在较快的x86处理器上实现10毫秒以内的软实时性能。但如果想实现可预测、可重复的微秒级的延时,使Linux系统更好地应用于嵌入式实时环境,则需要在保证Linux系统功能的基础上对其进行改造。下一节将介绍通过实时补丁来提高Linux实时性的方法。
5. 常用的实时Linux改造方案
根据实时性系统要求以及Linux的特点和性能分析,对标准Linux实时性的改造存在多种方法,较为合理的两大类方法为:
- 直接修改Linux内核源代码。
- 双内核法。
5.1 直接修改Linux内核源代码
对Linux内核代码进行细微修改并不对内核作大规模的变动,在遵循GPL协议的情况下,直接修改内核源代码将Linux改造成一个完全可抢占的实时系统。核心修改面向局部,不会从根本上改变Linux内核,并且一些改动还可以通过Linux的模块加载来完成,即系统需要处理实时任务时加载该功能模块,不需要时动态卸载该模块。
目前kernel.org发布的主线内核版本还不支持硬实时。为了开启硬实时的功能,必须对代码打补丁。实时内核补丁是多方努力的共同成果,目的是为了降低Linux内核的延时。这个补丁有多位代码贡献者,目前由Ingo Molnar维护,补丁网址如下:www.kernel.org/pub/linux/kernel/projects/rt/。
在配置已经打过实时补丁的内核代码时,我们发现实时补丁添加了第4种抢占模式,称为PREEMPT_RT(实时抢占)。实时补丁在Linux内核中添加了几个重要特性,包括使用可抢占的互斥量来替代自旋锁;除了使用preempt_disable()保护的区域以外,内核中的所有地方都开启了非自愿式抢占(involuntary preemption)功能。这种模式能够显著降低抖动(延时的变化),并且使那些对延时要求很高的实时应用具有可预测的较低延时。
这种方法存在的问题是:很难百分之百保证,在任何情况下,GPOS程序代码绝不会阻碍RTOS的实时行为。也就是说,通过修改Linux内核,难以保证实时进程的执行不会遭到非实时进程所进行的不可预测活动的干扰。
5.2 双内核法
实际上,双内核的设计缘由在于,人们不相信标准Linux内核可以在任何情况下兑现它的实时承诺,因为GPOS内核本身就很复杂,更多的程序代码通常会导致更多的不确定性,这样将无法符合可预测性的要求。更何况Linux内核极快的发展速度,使其会在很短的时间内带来很大的变化,直接修改Linux内核源代码的方法将难以保持同步。
双内核法是在同一硬件平台上采用两个相互配合,共同工作的系统核心,通过在Linux系统的最底层增加一层实时核心来实现。其中的一个核心提供精确的实时多任务处理,另一个核心提供复杂的非实时通用功能。
双内核方法的实质是把标准的Linux内核作为一个普通进程在另一个内核上运行。关键的改造部分是在Linux和中断控制器之间加一个中断控制的仿真层,成为其实时内核的一部分。该中断仿真机制提供了一个标志用来记录Linux的关开中断情况。一般只在修改核心数据结构关键代码时才关中断,所以其中断响应很小。其优点是可以做到硬实时,并且能很方便地实现一种新的调度策略。
为方便使用,实时内核通常由一套可动态载入的模块提供,也可以像编译任何一般的子系统那样在Linux源码树中直接编译。常用的双内核法实时补丁有RTLinux/GPL、RTAI 和 Xenomai,其中RTLinux/GPL只允许以内核模块的形式提供实时应用;而RTAI和Xenomai支持在具有MMU保护的用户空间中执行实时程序。下面,我们将对RTAI与Xenomai进行分析。

图1所示为RTAI和Xenomai两个实时内核分别与标准Linux内核组成双内核系统是的分层结构。可以看到两者有稍微不同的组织形式,与Xenomai让ADEOS掌控所有的中断源不同的是,RTAI拦截它们,使用ADEOS将那些RTAI不感兴趣的中断通知送给Linux(也就是,中断不影响实时时序)。这样混合过程的目的是提高性能,因为在这种情况下,如果中断是要唤醒一个实时任务,就避免了由ADEOS管理中断的开销。从这里可以看出,RTAI的实时性能应该是比Xenomai要好的。
RTAI(Real-Time Linux Application interface)虽然实时性能较好,但对ARM支持不够,更新速度极慢,造成项目开发周期长,研发成本高。
与RTAI相比,Xenomai更加专注于用户态下的实时性、提供多套与主流商业RTOS兼容的API以及对硬件的广泛支持,在其之上构建的应用系统能保持较高实时性,而且稳定性和兼容性更好;此外,Xenomai社区活跃,紧跟主流内核更新,支持多种架构,对ARM的支持很好。
Xenomai是Linux内核的一个实时开发框架。它希望无缝地集成到Linux环境中来给用户空间应用程序提供全面的、与接口无关的硬实时性能。Xenomai是基于一个抽象实时操作系统核心的,可以被用来在一个通用实时操作系统调用的核心上,构建任意多个不同的实时接口。Xenomai项目始于2001年8月。2003年它和RTAI项目合并推出了RTAI/fusion。2005年,因为开发理念不同,RTAI/fusion项目又从RTAI中独立出来作为Xenomai项目。相比之下,RTAI项目致力于技术上可行的最低延迟;Xenomai除此之外还很着重扩展性、可移植性以及可维护性。Xenomai项目将对Ingo Molnar的PREEMPT_PT实时抢占补丁提供支持,这又是与RTAI项目的一个显著的不同。RTAI和Xenomai都有开发者社区支持,都可以作为一个VxWorks的开源替代。
Xenomai是基于Adeos(Adaptive Domain Environment for Operating System)实现的,Adeos的目标是为操作系统提供了一个灵活的、可扩展的自适应环境;在这个环境下,多个相同或不同的操作系统可以共存,共享硬件资源。基于Adeos的系统中,每个操作系统都在独立的域内运行,每个域可以有独立的地址空间和类似于进程、虚拟内存等的软件抽象层,而且这些资源也可以由不同的域共享。与以往传统的操作系统共存方法不同,Adeos是在已有的操作系统下插入一个软件层,通过向上层多个操作系统提供某些原语和机制实现硬件共享。应用上主要是提供了一个用于“硬件-内核”接口的纳内核(超微内核),使基于Linux环境的系统能满足硬实时的要求。
Xenomai正是充分利用了Adeos技术,它的首要目标是帮助人们尽量平缓地移植那些依赖传统RTOS的应用程序到GNU/Linux环境,避免全部重写应用程序。它提供一个模拟器模拟传统实时操作系统的API,这样就很容易移植应用程序到GNU/Linux环境中,同时又能保持很好的实时性。Xenomai的核心技术就是使用一个实时微内核来构建这些实时API,也称作“Skin”。Xenomai通过这种接口变种技术实现了针对多种传统RTOS的应用编程接口,方便传统RTOS应用程序向GNU/Linux的移植。图2描述了Xenomai的这种带Skin的分层架构。

从图2可以看出,Xenomai系统包含多个抽象层:Adeos纳内核直接工作在硬件之上;位于Adeos之上的是与处理器体系结构相关的硬件抽象层(Hardware Abstraction Layer, HAL);系统的中心部分是运行在硬件抽象层之上的抽象的实时内核,实时内核实现了一系列通用RTOS的基本服务。这些基本服务可以由Xenomai的本地API(Native)或由建立在实时内核上的针对其他传统RTOS的客户API提供,如RTAI、POSIX、VxWorks、uITRON、pSOS+等。客户API旨在兼容其所支持的传统RTOS的应用程序在Xenomai上的移植,使应用程序在向Xenomai/Linux体系移植的过程中不需要完全重新改写,此特性保证了Xenomai系统的稳健性。Xenomai/Linux系统为用户程序提供了用户空间和内核空间两种模式,前者通过系统调用接口实现,后者通过实时内核实现。用户空间的执行模式保证了系统的可靠性和良好的软实时性,内核空间程序则能提供优秀的硬实时性。
《内存管理的另辟蹊径 - 腾讯云虚拟化开源团队为内核引入全新虚拟文件系统(dmemfs)》
https://mp.weixin.qq.com/s/DmoUynuyI8Wdwa_6kixgjw
作者简介
本文作者誉磊,腾讯云虚拟化开源团队高级研发工程师。
Linux内存管理概述
我们知道linux系统内核的主要工作之一是管理系统中安装的物理内存,系统中内存是以page页为单位进行分配,每个page页的大小是4K,如果我们需要申请使用内存则内核的分配流程是这样的,首先内核会为元数据分配内存存储空间,然后才分配实际的物理内存页,再分配对应的虚拟地址空间和更新页表。
好奇的同学肯定想问,元数据是什么,为什么我申请内存还要分配元数据,元数据有什么用呢?
其实为了管理内存页的使用情况,内核设计者采用了page structure(页面结构)的数据结构,也就是我们所说的元数据来跟踪内存,该数据结构以数组的形式保存在内存中,并且以physical frame number(物理页框号)为索引来做快速访问 (见图1) 。

元数据存储着各种内存信息,比如使用大页复合页的信息,slub分配器的信息等等,以便告诉内核该如何使用每个页面,以及跟踪页面在各个映射列表上的位置,或将其连接到后端的存储等等。所以在内核的内存管理中页面元数据的重要性不言而喻,目前在64位系统上这个数据结构占用64个字节,而由于通常的页面大小为4KB,比如一台安装了4GB内存的普通电脑上就有1048576个普通页,这意味着差不多需要64MB大小的内存来存储内存元数据来用于管理内存普通页。
似乎看起来并没有占用很多内存,但是在某些应用场景下面可就不同了哦,现今的云服务中普遍安装了海量内存来支持各种业务的运行,尤其是AI和机器学习等场景下面,比如图2中,如果服务器主机有768g的内存,则其中能真正被业务使用的只有753g,有大约10多个g的物理内存就被内存元数据所占用了,假如我们可以精简这部分内存,再将其回收利用起来,则云服务提供商就可以提供更多的云主机给自己的客户,从而增加每台服务器能带来的收入,降低了总体拥有成本,也就是我们常说的TCO,有那么多好处肯定是要付诸实施咯,但是我们要如何正确并且巧妙地处理这个问题而不影响系统的稳定性呢?

Direct Memory Management File System (直接内存管理文件系统)
有的小伙伴会说好像现有的内核接口就可以解决类似问题呀,比如我可以mmap系统中的/dev/mem,将线性地址描述的物理内存直接映射到进程的地址空间内,不但可以直接访问这部分内存也绕过了内核繁复的内存管理机制,岂不是很方便。但其实这里有很大的局限性,首先对于/dev/mem的访问需要root权限的加持,这就增加了内核被攻击的风险,其次mmap映射出来的是一整块连续的内存,在使用的过程中如何进行碎片化的管理和回收,都会相应需要用户态程序增加大量的代码复杂度和额外的开销。
为了既能更好地提高内存利用率,又不影响已有的用户态业务代码逻辑,腾讯云虚拟化开源团队独辟蹊径,为内核引入了全新的虚拟文件系统 - Direct Memory Management File System(直接内存管理文件系统)(见图3),该文件系统可以支持页面离散化映射用来避免内存碎片,同时全新设计了高效的remap (重映射)机制用来处理内存硬件故障(MCE)的情况,并且对KVM、VFIO和内存子系统交互所用到的接口都进行了优化,用来加速虚拟机机EPT页表和IOMMU页表的建立,在避免了内存元数据的额外开销的情况下还增加了虚拟机的性能提升的空间。
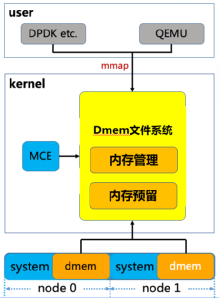
从内存管理上来看,dmemfs在服务器系统启动引导的时候就将指定数量的内存预先保留在系统中的各个NUMA节点上,这部分内存没有被系统内存管理机制接管,也就不需要消耗额外的内存来存储元数据。
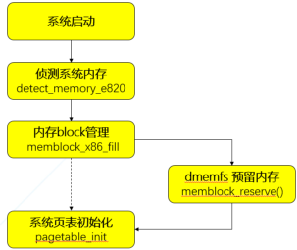
我们知道内核的内存信息全部来自e820表, 这部分e820信息只提供了内存的区间描述和类型,无法提供NUMA节点信息, 所以必须在memblock初始化之后, 内核buddy伙伴系统初始化之前做好内存预留 (见图4), 而这时memblock可能已经有分配出去的空间, 以及BIOS会预留等等原因, 导致同一个节点存在不连续的内存块,因此dmemfs引入了全新的kernel parameter “dmem=”,并将其指定为early param。
内核在解析完参数之后会将得到的信息全部存放在全局结构体dmem_param,其中包含着我们需要预留的memory的大小和起始地址等,随后在内核初始化到在ACPI处理和paging_ini()之间,我们插入dmem的预留处理函数memblock_reserve(),将dmem内存从memblock中扣除,形成dmem内存池。而存留在memblock中的系统内存则会被paging_init()构建对应的内存元数据并纳入buddy子系统。(见图4)
预留下来的内存由称为dmem_pool的内存池结构体来管理,第一层拓扑为dmem numa node,用来描述dmem在各个numa 节点上的分布情况以实现了numa亲和性,第二层拓扑是在dmem numa node的基础上再实现一个dmem region链表,以描述当前节点下每段连续的dmem内存区间(见图5)。每个region中以page作为分配的最小颗粒度,都关联到一个local bitmap来维护和管理每个dmem 页面的状态,在挂载dmemfs文件系统时为每个 region申请并关联 bitmap, 并且指定页面大小的粒度, 比如4K, 2M或1G,从而方便在服务器集群中部署使用

简单的来说在挂载了dmemfs文件系统之后,就可以使用如下的qemu参数将dmemfs所管理的物理内存传递给虚拟机直接使用。
-object memory-backend-file,id=ram-node0,mem-path=/mnt/dmemfs-uuid \而在虚拟机启动之后,对内存的读写会发生缺页异常,而内核的缺页处理机制会将请求发送给dmemfs,dmemfs就会将预留内存按照所需页面的大小补充到EPT表中从而帮助虚拟机建立好GVA->HPA的映射关系。
为了满足实际生产环境,dmemfs还必须支持对MCE的处理。MCE, 即Machine Check ERROR, 是一种用来报告系统错误的硬件方式。当触发了MCE时, 在Linux内核流程中会检查这个物理页面是否属于dmem管理, 我们在基于每个连续内存块的dmem region内引入了一个error_bitmap, 这是以物理页面为单位的, 来记录当前系统中发生过mce的页。同时通过多个手段, 保证分配内存使用的bitmap和这个mce error_bitmap保持同步, 从而后续的分配请求会跳过这些错误页面(见图6)。
然后在内存管理部分引入一个 mce通知链, 通过注册相应的处理函数, 在触发mce时可以通知使用者进行相应的处理。
而在dmem文件系统层面, 我们则通过inode链表来追踪文件系统的inode,当文件系统收到通知以后, 会遍历这个链表来判断并得到错误页面所属的inode,再遍历inode关联的vma红黑树, 最终得到使用这些错误页的相关进程进行相应的处理。

在使用了dmemfs之后,由于消除了冗余的内存元数据结构,内存的额外消耗有了显著地下降,从图7的实验数据中可以看到,内存规格384GB的服务器中, 内存消耗从9GB降到2GB, 消耗降低了77.8%,而内存规格越大, 使用内存全售卖方案对内存资源的消耗占比越小, 从而可以将更多内存回收再利用起来, 降低了服务器平台成本。

目前dmemfs的相关代码已经提交到了内核社区review,感兴趣的同学可以点击左下角阅读原文阅读相关的代码。
https://lkml.org/lkml/2020/10/8/139
《刨根问底儿,看我如何处理 Too many open files 错误!》
https://mp.weixin.qq.com/s/GBn94vdL4xUL80WYrGdUWQ
本站转载地址:《Linux如何处理 Too many open files》https://rtoax.blog.csdn.net/article/details/113818743
《Linux Containers》
https://wiki.archlinux.org/index.php/Linux_Containers
Linux容器(LXC)是一种操作系统级虚拟化方法,用于在单个控制主机(LXC主机)上运行多个隔离的Linux系统(容器)。它不提供虚拟机,而是提供具有自己的CPU,内存,块I / O,网络等空间和资源控制机制的虚拟环境。这由LXC主机上Linux内核中的名称空间和cgroups功能提供。它类似于chroot,但是提供了更多的隔离。
LXD可以用作LXC的管理器。此页面直接处理LXC。
- 1个特权容器或非特权容器
- 1.1举例说明无特权的容器
- 2设置
- 2.1所需软件
- 2.1.1启用支持以运行非特权容器(可选)
- 2.1.1.1Linux强化和自定义内核上的非特权容器
- 2.1.1启用支持以运行非特权容器(可选)
- 2.2主机网络配置
- 2.2.1使用主机桥
- 2.2.2使用NAT网桥
- 2.2.2.1防火墙注意事项
- 2.2.2.1.1iptables规则示例
- 2.2.2.1.2UFW规则示例
- 2.2.2.2以非root用户身份运行容器
- 2.2.2.1防火墙注意事项
- 2.3容器创建
- 2.4容器配置
- 2.4.1具有网络的基本配置
- 2.4.2安装在容器内
- 2.4.3Xorg程序注意事项(可选)
- 2.4.4OpenVPN注意事项
- 2.1所需软件
- 3管理容器
- 3.1基本用法
- 3.2高级用法
- 3.2.1LXC克隆
- 3.3将特权容器转换为非特权容器
- 4运行Xorg程序
- 5故障排除
- 5.1根登录失败
- 5.2容器配置中没有与veth的网络连接
- 5.3错误:命令未知
- 5.4错误:在步骤KEYRING产生时失败...
- 6已知的问题
- 6.1与Linux内核5.10.0不兼容
- 6.2由于缺少lxc.init.static,lxc执行失败
- 7也可以看看
《一次解决Linux内核内存泄漏实战全过程》
https://mp.weixin.qq.com/s/RafQUmblVX69zegDWQUcew
接下来的排查思路是:
1.监控系统中每个用户进程消耗的PSS (使用pmap工具(pmap pid)).
PSS:按比例报告的物理内存,比如进程A占用20M物理内存,进程B和进程A共享5M物理内存,那么进程A的PSS就是(20 - 5) + 5/2 = 17.5M
2.监控/proc/meminfo输出,重点观察Slab使用量和slab对应的/proc/slabinfo信息
3.参考/proc/meminfo输出,计算系统中未被统计的内存变化,比如内核驱动代码
直接调用alloc_page()从buddy中拿走的内存不会被单独统计

在排查的过程中发现系统非常空闲,都没有跑任何用户业务进程。