1. ʹ�ó����ڴ�ĺô�
- ���ʳ����ڴ�ʱ, GPU����Է���ͬһ����ַ��half-warp(16��threads)ֻ��ȡһ�δ˵�ַ.
- �����ʵij����ڴ汻cache, ֮��ĶԴ˵�ַ�ķ��ʿ��Ը��ӿ��.
���half-warp�ڵ�threads��Ҫ���ʲ�ͬ�ĵ�ַ, ��ô��Щ���ʾͻᴮ�н���, �ٶȻ��ʹ��global memoryҪ��. ��Ϊ����global memory�ǿ��Բ��е�.
2. ����������
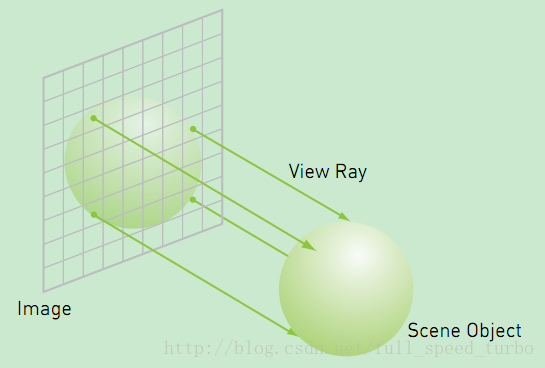
���Լ�Ϊ: ��ijһ����������Ĵ�ֱ��bitmapƽ�������,�͵�ǰ�����ཻ,��������һ������.
�������ò�ͬ��С, λ�ú���ɫ������.
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"#define INF 2e10f
#define rnd( x ) (x * rand() / RAND_MAX)
#define SPHERES 20 //��������
#define DIM 1024 // bitmapͼ��Сstruct Sphere{float r,b,g;float radius;float x,y,z; //����//��ijһ����������Ĵ�ֱ��bitmapƽ�������,�͵�ǰ�����ཻ,��������һ������//û�н���ͷ��ظ�����__device__ float hit(float ox, float oy, float *n){float dx = ox - x;float dy = oy - y;if(dx*dx + dy*dy < radius*radius){float dz = sqrtf(radius*radius - dx*dx - dy*dy);*n = dz / sqrtf( radius * radius);return dz + z;}return -INF;}
};// kernel����Ӧ�ü���ڶ�������Sphere* s
// ��Ϊmain�������s��host����,������kernelʹ��
__global__ void kernel( unsigned char *ptr, Sphere *s)
{int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;int offset = x + y * blockDim.x * gridDim.x;float ox = (x - DIM/2);float oy = (y - DIM/2);float r=0, g=0, b=0;float maxz = -INF;for (int i=0; i<SPHERES; i++){float n;float t = s[i].hit(ox, oy, &n);if (t > maxz){float fscale = n;r = s[i].r * fscale;g = s[i].g * fscale;b = s[i].b * fscale;}}//�ĸ�ͨ����ֵptr[offset*4 + 0] = (int)(r*255);ptr[offset*4 + 1] = (int)(g*255);ptr[offset*4 + 2] = (int)(b*255);ptr[offset*4 + 3] = 255;
}int main(void)
{cudaEvent_t start, stop;HANDLE_ERROR( cudaEventCreate( &start ) );HANDLE_ERROR( cudaEventCreate( &stop ) );HANDLE_ERROR( cudaEventCreate( &start, 0 ) );CPUBitmap bitmap(DIM, DIM);unsigned char *dev_bitmap;Sphere *s;HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,bitmap.image_size() ) );HANDLE_ERROR( cudaMalloc( (void**)&s,sizeof(Sphere) * SPHERES ) );//���������CPU�ϳ�ʼ��Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );for (int i=0; i<SPHERES; i++){temp_s[i].r = rnd( 1.0f );temp_s[i].g = rnd( 1.0f );temp_s[i].b = rnd( 1.0f );temp_s[i].x = rnd( 1000.0f ) - 500;temp_s[i].y = rnd( 1000.0f ) - 500;temp_s[i].z = rnd( 1000.0f ) - 500;temp_s[i].radius = rnd( 100.0f ) + 20;}//��Sphere������������GPU��HANDLE_ERROR( cudaMemcpy( s, temp_s,sizeof(Sphere) * SPHERES,cudaMemcpyHostToDevice ) );free( temp_s );// GPU��������dim3 grids(DIM/16, DIM/16);dim3 threads(16, 16);kernel<<<grids,threads>>>(dev_bitmap, s);//��GPU������Host��HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(),dev_bitmap,bitmap.image_size(),cudaMemcpyDeviceToHost ) );bitmap.display_and_exit();//free memorycudaFree( dev_bitmap );cudaFree( s );}���:

3. �ڹ�����������ʹ��Constant Memory
ʹ�ó����ڴ�Ҫע��:
1. ���䳣���ڴ治ʹ�ö�̬����, ֱ���ڱ���ʱ����. ���Ҵ��������ܷ��ں������ڲ�.
__constant__ Sphere s[SPHERES];- �����ݴ�Host������GPU��constant memory����Ҫʹ��:
cudaMemcpyToSymbol( s, temp_s, sizeof(Sphere) * SPHERES );��������:
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"#define INF 2e10f
#define rnd( x ) (x * rand() / RAND_MAX)
#define SPHERES 20 //��������
#define DIM 1024 // bitmapͼ��Сstruct Sphere{float r,b,g;float radius;float x,y,z; //����//��ijһ����������Ĵ�ֱ��bitmapƽ�������,�͵�ǰ�����ཻ,��������һ������//û�н���ͷ��ظ�����__device__ float hit(float ox, float oy, float *n){float dx = ox - x;float dy = oy - y;if(dx*dx + dy*dy < radius*radius){float dz = sqrtf(radius*radius - dx*dx - dy*dy);*n = dz / sqrtf( radius * radius);return dz + z;}return -INF;}
};// ����ָ��
// �����ڴ���������ܷ��ں������ڲ�.
__constant__ Sphere s[SPHERES];
__global__ void kernel( unsigned char *ptr)
{int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;int offset = x + y * blockDim.x * gridDim.x;float ox = (x - DIM/2);float oy = (y - DIM/2);float r=0, g=0, b=0;float maxz = -INF;for (int i=0; i<SPHERES; i++){float n;float t = s[i].hit(ox, oy, &n);if (t > maxz){float fscale = n;r = s[i].r * fscale;g = s[i].g * fscale;b = s[i].b * fscale;}}//�ĸ�ͨ����ֵptr[offset*4 + 0] = (int)(r*255);ptr[offset*4 + 1] = (int)(g*255);ptr[offset*4 + 2] = (int)(b*255);ptr[offset*4 + 3] = 255;
}int main(void)
{cudaEvent_t start, stop;HANDLE_ERROR( cudaEventCreate( &start ) );HANDLE_ERROR( cudaEventCreate( &stop ) );HANDLE_ERROR( cudaEventCreate( &start, 0 ) );CPUBitmap bitmap(DIM, DIM);unsigned char *dev_bitmap;HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,bitmap.image_size() ) );//�����ڴ治��ҪΪ֮����GPU�洢�ռ�.//HANDLE_ERROR( cudaMalloc( (void**)&s,// sizeof(Sphere) * SPHERES ) );//���������CPU�ϳ�ʼ��Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );for (int i=0; i<SPHERES; i++){temp_s[i].r = rnd( 1.0f );temp_s[i].g = rnd( 1.0f );temp_s[i].b = rnd( 1.0f );temp_s[i].x = rnd( 1000.0f ) - 500;temp_s[i].y = rnd( 1000.0f ) - 500;temp_s[i].z = rnd( 1000.0f ) - 500;temp_s[i].radius = rnd( 100.0f ) + 20;}//��Sphere������������GPU��HANDLE_ERROR( cudaMemcpyToSymbol( s, temp_s,sizeof(Sphere) * SPHERES ) );free( temp_s );// GPU��������dim3 grids(DIM/16, DIM/16);dim3 threads(16, 16);kernel<<<grids,threads>>>(dev_bitmap);//��GPU������Host��HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(),dev_bitmap,bitmap.image_size(),cudaMemcpyDeviceToHost ) );bitmap.display_and_exit();//free memorycudaFree( dev_bitmap );//cudaFree( s );}