ժҪ
���е�SOAĿ������������Siameseϵ�������㷨����ʹ��DNN����ø�ȷ�ʡ����ںܶ��˶����о��Ӿ���ģ�͵�³���ԡ���ƪ�����з����˻���Siamese�����Ŀ�����������㣬�������Ӿ�Ŀ�����������ɶԿ���������ƪ�����������һ��FAN��Fast Attack Network�����Ӷ�ʹ��Ư����ʧ��drift loss����Ƕ��������ʧ��mbeddedfeature loss��������Siamese����������FAN���������������ƪ������Ҫ�Dz��������ѵ���Կ��������ٶȡ�FAN������10ms��ʱ���ھͲ���һ����Ŀ��ĶԿ�������������Ŀ��ĶԿ�������
Introduction
1����Ŀ��ĶԿ���������Ŀ��ĶԿ�����

��ͼ�п��Կ�������Ŀ��ĶԿ���������ʹ��������Ŀ��������ٳ����෴��������Ҫ�ķ���ȥ�ƶ���������Ŀ��ĶԿ������У��ٵı߽�����ͼƬ�ķɣ��Ӷ�����ԭʼ����ȷ���ٽ����
SiamFC����ͨ��ѧϰ����������Եõ�֡��֮֡��������ԡ���Ŀ�����У�VOT�ǿ���������ÿһ֡�������Ƶ������������������ʵ���Ǹ����ƶȵĶ������⡣��ƪ�����о��ľ���VOT�ϵĶԿ�������
Contribution
��1����ƪ�����ǵ�һƪ��VOT����Ŀ�깥������Ŀ�깥���Ĺ�������������е�һ�θ�������Ŀ�깥������Ŀ�깥���Ķ��塣
��2����ƪ���������һ���˵��˵Ĺ���������FAN�����������һ�������drift loss��Ư����ʧ����ʵʩ��Ŀ�깥���������һ��embedded feature loss��ʵʩ��Ŀ�깥�������������ʧ������ϵ�һ��Ӷ�ʵʩ�����Ĺ�������
��3����3��Сʱ��ѵ������FAN�����ڲ���Ҫ�����������fine tune�Ļ����ϳɹ��Ĺ���VOT��OTB���ݼ���������inference�Σ�FAN������10ms���ڲ����Կ���������֮ǰ�ĵ����Ż��㷨Ҫ��ܶࡣ
��ع���
��1��Ŀ�����е����ѧϰ
���ڵĻ������ѧϰ�������ϵͳ���Էֳ��������һ����tracking-by-detection�ܹ�����һ���ǻ���SiamFC��SiamRPN����SiamFC�о��ǹ�ע���б�ʽ����ѧϰ��ͨ����ʾ��template-��ѡ����������н�ģ�����ҽ��ж�̬�ij������Ż�������SiamRPN�У��ܶ��о���������һ�����缶����ģ����������ѡ����������DaSiam�����һ�����ڸ�֪��������ѵ�����Կ��Բ�������Բ��Ҷ��������������ѹ����
��2������ʽ�Կ�����������ʽ�Կ�����
���еĶԿ������ǻ����Ż��㷨�������㷨�������Ż��ĶԿ�������ͨ������DNN���ݶȴӶ�����õ�noise�����Ĵ��·���I-FGSM�Ϳ��Խ�one-step���Ż��ָ�ɺü���С�IJ��裬���ҵ���ʽ��Ϊͼ������������ɶԿ�������DAG�ͽ�RPN�еĺ�ѡ��������һ��sample�����ҿ��Ե���ʽ�ĸı��ѡ�����label�Ӷ�����Ŀ�����Ŀ��ָ�������һ������ʽ�Կ��������ǻ��������������Ժܿ�����ɶԿ��Ŷ���GAP�Ϳ���ʹ��ResNet�������ܹ���ImageNet�����ͼƬ��������ࡣUEA����ͨ�����multi-layer������ʧ�ͷ�����ʧ�����ɿ���Ǩ�ƵĶԿ�������������Ϊ���ٶȵ����ƺ�Ҫ���ڵ����Ż��ĶԿ�����������VOT������ȡ��ʵʱ�ԵĹ���Ч����
���ɶԿ�����
��1�����ⶨ��
I1��I2����In��n����Ƶ֡��b1��b2������bn��n��ground truthҲ����n����Ƶ֡�е�Ŀ�������λ�á�VOT������ǻ���ڳ�ʼ֡��״̬��֮��ÿһ��֡��ͼƬ�е�Ŀ�������λ�ý���Ԥ�⡣������VOT�������ڷ��࣬���Dz����ڻع飩
��Ŀ�깥���Ķ���Ϊ������������������Ҫ�Ĺ켣CspecificC^{specific}Cspecificȥ��Ŀ�����塣��cic_ici?��ΪԤ�����ģ�cispecc_i^{spec}cispec?��������ҪĿ�걻�ٵĹ켣��Ŀ�������O�Oci?cispec�O�O<��||c_i-c_i^{spec}||<\xi�O�Oci??cispec?�O�O<��.�������\xi�������ó�20�����ص㡣��������ľ��뵽������ô������أ���Ϊÿһ֡������һ��λ�ã�
��Ŀ�깥���Ķ���Ϊ�����ٵĽ��Զ��ԭʼ���ٽ����IOU(��attack,��gt)=0IOU(\beta^{attack},\beta{gt})=0IOU(��attack,��gt)=0������һ����ԭʼ��gtҲ����ground truth�����һ���ǹ����Ľ����������ֱ��Ϊ0ʱ�Dz�������������Ƶ�̫ǿ�ˣ�
��2��Ư����ʧ����
�����������磨Siamese network���������ںܴ�̶��϶���������ȫ���������������Ӧͼ���Ӷ�Ԥ��Ŀ�������λ�á���ΪSiamFC��ʹ��һ����������x��Ԥ��Ŀ�������λ�ã����Կ���ͨ��������������Ӷ�ʵʩ��Ŀ�깥��������ʱ������ƣ�������һֱ����Ԥ��ƫ�ƣ�ֱ������������ȫ��ʧ��Ŀ��������١���ͼ2a�У����Կ���������ӦͼS�У���ɫԽ�������Ӧ����Խ����ͼ�еĺ�ɫ�������ɫ����ֱ�������ǶԿ�ͼ��ԭʼ�ɾ�ͼƬ����Ӧ����c��ʾ������Ӧͼ�еķ�����������һ��ѵ���õ�������˵���ɾ���������Ӧͼ�������ǹ�ע����ɫ���������������ˣ����������һ��Ư����ʧ������ʹ��S�����Ŀ���Ư�ơ�

����Ĺ�ʽ��drift loss�ĺ���������ͨ���Լ������ģ�activation center������Ư�ƣ��Ӷ������Կ��Ŷ���s��ʾ������Ӧ������y��ʾ����ӦͼS�е�label��ǩ�����е�S����������Ҳ�������е���ɫ����label��1���������־���-1.
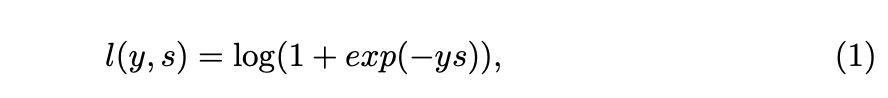
Ϊ�˲����Կ��������������������Ӧͼ�������ӦֵҪ��ground truth�������Ӧֵ��������Ӧͼ�ķ�����ʧ��score loss������д�����������е�p����������Ӧͼ�е�ÿһ��λ�á�
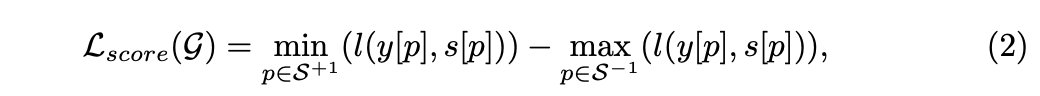
Ŀ��box��ƫ����������Ӧͼ�е�activation center��ƫ�ơ���������activation center�����ܵ�Զ��ԭʼ������center������distance loss���Ա�ʾ������������
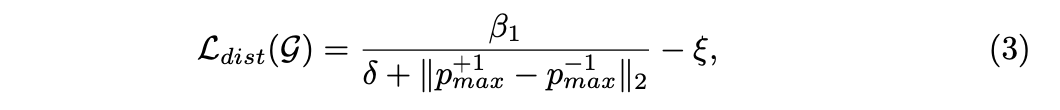
����drift lossƯ����ʧ����д�����£�
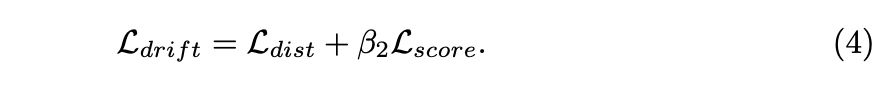
��3�� Ƕ��������ʧ������Embedded Feature Loss Attack��
��Ŀ�깥����Ҫ���������ض��Ĺ켣����Ŀ����������٣�������Ŀ�깥������Ŀ�깥���Dz�һ���ġ���Ȼ�����drift loss���Բ�����Ŀ�깥����������Ϊ���Ĺ��������Dz�ȷ���ģ����Բ��ܲ�����Ŀ�깥������Ŀ�깥����������һ����ƵV�Լ�һ���ض��Ĺ켣������CspecC^{spec}Cspec����ΪĿ��ͱ����кܴ������������������xR+1x_{R+1}xR+1?��ģ��ͼƬz����Ӧֵ�ڱ�����������ͣ�������Ŀ�깥���ͺ�����ʧ�ܡ�������û������ɶ��˼��
�����Ҫ����Ŀ�깥���Ļ�������Ҫ������Ӧֵ�Ĵ�С������ͼ�е�Figure 2b������Ҫ��С���Կ��Է������ض������������֮���L2���롣���ԣ����������Ƕ��ʽ������ʧ���Բ����Կ�ͼƬz^\hat zz^��x^R+1\hat x_{R+1}x^R+1?�����ɵĶԿ������������Ǻ�Ƕ��ͼƬe����������ġ�

����ͼ�еĹ�ʽ5��ʾ��e���������ض���������q���������������Ƶ����?\phi?������������������G(q����ʾ���ǶԿ��Ŷ������Զ�����ǰ����ǶԿ�����ͼƬ���������������Ƕ��ʽͼƬ����������������ȡ���Կ�ͼƬ��������Ƕ��ʽͼƬ����������Ҫ�����ܽӽ���
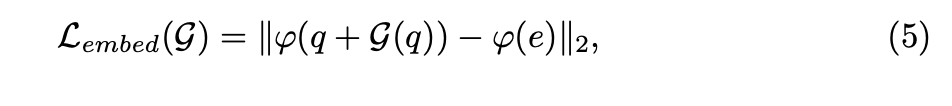
��ѵ���ε�Ƕ��ʽͼƬ��ѡ���Ǻ���Ҫ�ġ����磬����Ȯ��ѩ��Ȯ֮�����������С������Ȯ�Ͱ���è֮����������롣��ʵ�ʵĹ��������У����߲����˸�˹�������滻��ʽ5�е�Ƕ��ʽͼƬe��