1 ʲô�� Encoder-Decoder ��
Encoder-Decoder ģ����Ҫ�� NLP ������ĸ����������ֵij�־�����㷨������һ���㷨��ͳ�ơ�Encoder-Decoder ����һ��ͨ�õĿ�ܣ����������¿���ʹ�ò�ͬ���㷨�������ͬ������,�����ܺܺõ�ڹ���˻���ѧϰ�ĺ���˼·������ʵ����ת��Ϊ��ѧ���⣬ͨ�������ѧ���⣬�Ӷ������ʵ���⡣
Encoder �ֳ������������������þ��ǡ�����ʵ����ת��Ϊ��ѧ���⡹

Decoder �ֳ��������������������ǡ������ѧ���⣬��ת��Ϊ��ʵ����Ľ��������

�� 2 ������������������ͨ�õ�ͼ������������������ӣ�

< center> ͼ1
Encoder-Decoder��ܿ�����ôֱ�۵�ȥ����_[1]�������������ʺϴ�����һ�����ӣ���ƪ�£���������һ�����ӣ���ƪ�£���ͨ�ô���ģ�͡����ھ��Ӷ�<X,Y>�����ǵ�Ŀ���Ǹ����������X���ڴ�ͨ��Encoder-Decoder���������Ŀ�����Y��X��Y������ͬһ�����ԣ�Ҳ���������ֲ�ͬ�����ԡ���X��Y�ֱ��ɸ��Եĵ������й���:
X=<x1,x2,...,xm>X=<x_1,x_2,...,x_m>X=<x1?,x2?,...,xm?>Y=<y1,y2,...,yn>Y=<y_1,y_2,...,y_n>Y=<y1?,y2?,...,yn?>
Encoder���������X���б��룬���������ͨ�������Ա任ת��Ϊ�м������ʾC��
C=F(x1,x2,...,xm)C = F(x_1,x_2,...,x_m)C=F(x1?,x2?,...,xm?)���ڽ�����Decoder��˵���������Ǹ��ݾ���X���м������ʾC��֮ǰ�Ѿ����ɵ���ʷ��Ϣy1,y2��.yi-1������iʱ��Ҫ���ɵĵ���yiy_iyi?
yi=g(C,y1,y2,...,yn)y_i=g(C,y_1,y_2,...,y_n)yi?=g(C,y1?,y2?,...,yn?)ÿ��yiy_iyi?��������ô��������ô��������������ϵͳ�����������X������Ŀ�����Y��
��ˣ�ȷ��˵��Encoder-Decoder������һ�������ģ�ͣ�����һ������Encoder��Decoder���ֿ�������������֣�������ͼ����Ƶ���ݣ�ģ�Ϳ��Բ���CNN��RNN��BiRNN��LSTM��GRU�ȵȡ����Ի���Encoder-Decoder�����ǿ�����Ƴ����ָ�����Ӧ���㷨��
Ϊ�˷������⣬������ѡȡ�˱���ͽ��붼��RNN����ϣ�
��RNN�У�x={x1��x2������xt}�������룬��ÿ��ʱ�䲽t��RNN������״̬ hth_tht?��ǰʱ������״̬������һʱ�̵�����״̬�͵�ǰʱ�̵���������ģ�����¹�ʽ���£�
ht=f(ht?1,x)h_t = f(h_{t-1},x)ht?=f(ht?1?,x)
���У�hth_tht?����һ����СΪrnn_size������״̬
����˸���ʱ�̵�����״̬�Ժ��ٽ���Ϣ���ܣ����������������C��������ͼ������C��
C=q({fh1,...,hTx})C=q({\{f_{h1},...,h_{T_x}\}})C=q({
fh1?,...,hTx??})
q��ʾij�ַ����Ժ�������[1]�У����߲���LSTM������ΪEncoder���磬ʵ������LSTM��������RNN�����У���ǰʱ�̼�������ǿ�����ǰ��ʱ�̵�����״̬���ˣ����Ծ��������һ��ʱ�̵�����״̬��Ϊ�������C����
C=hTxC = h_{T_x}C=hTx??
�����������Ҫ���ݸ������������C���Ѿ����ɵ��������y1,y2,��yt?1y_1,y_2,��y_{t?1}y1?,y2?,��yt?1?��Ԥ����һ������ĵ���yt��ʵ���Ͼ��ǰ����ɾ���y=y1,y2,��yTy={y_1,y_2,��y_T}y=y1?,y2?,��yT?�����ϸ��ʷֽ�ɰ�˳�������������
p(y)=��t=1Tp(yt�O{y1,y2,...yt?1},C)p(y)=\prod_{t=1}^{T}p(y_t|\{y_1,y_2,...y_{t-1}\},C)p(y)=t=1��T?p(yt?�O{
y1?,y2?,...yt?1?},C)��ÿһ�����������ֿ���д��:
p(yt�O{y1,y2,...yt?1},C)=g(yt?1,st,C)p(y_t|\{y_1,y_2,...y_{t-1}\},C)=g(y_{t-1},s_t,C)p(yt?�O{
y1?,y2?,...yt?1?},C)=g(yt?1?,st?,C)����sts_tst?�����RNN�е����ز㣬C����֮ǰ���������������yt?1y_{t?1}yt?1?��ʾ�ϸ�ʱ�̵������ggg��ʾһ�ַ����Ա任����������ָһ�ֶ��ĺ������������yty_tyt?�ĸ��ʣ�������RNN���softmax����
���ԣ����ı����е�Encoder-Decoderģ���У�ԭ��RNN��LSTM������ģ����Ҫ����p(y1,y2,��yT�Ox1,x2,...,xT��)p(y1,y2,��yT|x1,x2,...,xT��)p(y1,y2,��yT�Ox1,x2,...,xT��)������һ������x���õ�һ�����y������Ҫ�ȳ�����������ΪEncoder-Decoder�м����������c��ǰ�������ָ����ˣ������������yֻ��Ҫ��c��ؼ�����
ѵ��ʱֻҪ�˵���ѵ��RNN��LSTM������Ϳ����ˣ���ÿһ������ĩβ����һ��end-of-sentence symbol�� EOS���ţ������������Ԥ��������ӡ�������ģ�;Ϳ�����ɻ�����Ӣ��-����ķ�������

���� Encoder-Decoder����2 ����Ҫ˵����
- �������������ij�����ʲô���м�ġ����� c�� ���ȶ��ǹ̶��ģ���Ҳ������ȱ�ݣ����Ļ���ϸ˵����
- ���ݲ�ͬ���������ѡ��ͬ�ı������ͽ�������������һ�� RNN ����ͨ��������� LSTM ���� GRU �����Ѿ��ᵽ��һЩ��
2 Attention Model��AM��
������Encoder-Decoderģ�ͷdz����䣬����Ҳ�о����ԡ����ľ����Ծ����ڱ���ͽ���֮���Ψһ��ϵ����һ���̶����ȵ���������c��Ҳ����˵��������Ҫ���������е���Ϣѹ����һ���̶����ȵ�������ȥ�������������������ˣ�һ��������������ȫ��ʾ�������е���Ϣ�����о��������������Я������Ϣ�ᱻ���������Ϣϡ�͵�������˵���������ˡ���������Խ������������Խ���ء����ʹ���ڽ����ʱ��һ��ʼ��û�л�����������㹻����Ϣ�� ��ô�����ȷ����ȻҲ��Ҫ����ۿ���[3]��
���dz�������һ����Ϊ��ע���������С���Ϊʲô˵��ע�����������أ���۲���Ŀ�����Y��ÿ�����ʵ����ɹ������£�
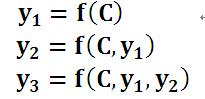
����f��decoder�ķ����Ա任��������������Կ�����������Ŀ����ӵĵ���ʱ�����������ĸ����ʣ���y1,y2Ҳ�ã�����y3Ҳ�ã�����ʹ�õľ���X���������C����һ���ģ�û���κ�����
���������C���ɾ���X��ÿ�����ʾ���Encoder ��������ģ�����ζ�Ų����������ĸ����ʣ�y1,y2����y3����ʵ����X�����ⵥ�ʶ�����ij��Ŀ�굥��yi��˵Ӱ����������ͬ�ģ�û���κ�����
�����Ϊ��˵���ģ��û�����ֳ�ע������Ե�ɡ�������������һ����������û��ע�⽹��һ��������û��������������������ģ�͵�Encoder-Decoder��ܸ������⣬�����������Ӣ�ľ��ӣ�Tom chase Jerry��Encoder-Decoder������������ĵ��ʣ�����ķ�������𡱣������𡱡��ڷ��롰����������ĵ��ʵ�ʱ����ģ�������ÿ��Ӣ�ĵ��ʶ��ڷ���Ŀ�굥�ʡ����𡱹�������ͬ�ģ����������ﲻ̫��������Ȼ��Jerry�����ڷ���ɡ����𡱸���Ҫ�����Ƿ���ģ������������һ��ģ������Ϊ��˵��û������ע������ԭ��
����ʵ���Encoder��RNN�Ļ���������Խ�Ǻ�����ĵ���Ӱ��Խ���ǵ�Ȩ�ģ�������Ҳ��Ϊ��Google���Sequence to Sequenceģ��ʱ���ְ����������������������Ч������õ�СTrick��ԭ��
û������ע������ģ����������ӱȽ϶̵�ʱ��������ⲻ�������������ӱȽϳ�����ʱ����������ȫͨ��һ���м�������������ʾ��������������Ϣ�Ѿ���ʧ�������֪�ᶪʧ�ܶ�ϸ����Ϣ����Ҳ��Ϊ��Ҫ����ע����ģ�͵���Ҫԭ��
����������У��������AMģ�͵Ļ���Ӧ���ڷ��롰���𡱵�ʱ�����ֳ�Ӣ�ĵ��ʶ��ڷ��뵱ǰ���ĵ��ʲ�ͬ��Ӱ��̶ȣ����������������һ�����ʷֲ�ֵ��
��Tom,0.3��(Chase,0.2)(Jerry,0.5)
����ÿ��Ӣ�ĵ��ʵĸ��ʴ����˷��뵱ǰ���ʡ�����ʱ��ע��������ģ�ͷ������ͬӢ�ĵ��ʵ�ע������С����Ϊ�������µ���Ϣ���������ȷ����Ŀ�����ʿ϶����а����ġ�
ͬ����Ŀ������е�ÿ�����ʶ�Ӧ��ѧ�����Ӧ��Դ������е��ʵ�ע�������������Ϣ������ζ��������ÿ������YiY_iYi?��ʱ��ԭ�ȶ�����ͬ���м������ʾC���滻�ɸ��ݵ�ǰ���ɵ��ʶ����ϱ仯��CiC_iCi?��

������Ŀ����ӵ��ʵĹ��̳����������ʽ��

��ÿ��CiC_iCi?���ܶ�Ӧ�Ų�ͬ��Դ����ӵ��ʵ�ע����������ʷֲ���������������Ӣ��������˵�����Ӧ����Ϣ�������£�

���У�f2��������Encoder������Ӣ�ĵ��ʵ�ij�ֱ任�������������Encoder���õ�RNNģ�͵Ļ������f2�����Ľ��������ij��ʱ������xi������ڵ��״ֵ̬��
\ \ \ \ \ g����Encoder���ݵ��ʵ��м��ʾ�ϳ����������м������ʾ�ı任������һ��������У�g�������ǶԹ���Ԫ�ؼ�Ȩ��ͣ�Ҳ���dz�����������������й�ʽ��
Ci=��j=1TaijhjC_i = \sum_{j=1}^{T}a_{ij}h_jCi?=j=1��T?aij?hj?
����CiC_iCi?���Ǹ�iii��������ġ���ķ������ôTxT_xTx?�͵���3������������ӵij��ȣ�h1=f(��Tom��)h1=f(��Tom��)h1=f(��Tom��)��h2=f(��Chase��)h2=f(��Chase��)h2=f(��Chase��),h3=f(��Jerry��)h3=f(��Jerry��)h3=f(��Jerry��)����Ӧ��ע����ģ��Ȩֵaia_iai?�ֱ���0.6,0.2,0.2������ggg�������Ǹ���Ȩ��ͺ�������������ʾ�Ļ����������ĵ��ʡ���ķ����ʱ����ѧ��ʽ��Ӧ���м������ʾCiC_iCi?���γɹ���������ͼ��

���ﻹ��һ�����⣺����Ŀ�����ij�����ʣ����硰��ķ����ʱ������ô֪��AMģ������Ҫ��������ӵ���ע����������ʷֲ�ֵ�أ�����˵����ķ����Ӧ�ĸ��ʷֲ���
��Tom,0.6��(Chase,0.2)(Jerry,0.2��
����εõ����أ�
Ϊ�˱���˵�������Ǽ����ͼ1�ķ�AMģ�͵�Encoder-Decoder��ܽ���ϸ����Encoder����RNNģ�ͣ�DecoderҲ����RNNģ�ͣ����DZȽϳ�����һ��ģ�����ã���ͼ1��ͼת��Ϊ��ͼ��

��ô����ͼ���Խ�Ϊ��ݵ�˵��ע����������ʷֲ�ֵ��ͨ�ü�����̣�

���ڲ���RNN��Decoder��˵�����Ҫ����yi���ʣ���ʱ��iii�������ǿ���֪��������YiY_iYi?֮ǰ������ڵ�iʱ�̵����ֵHiH_iHi?�ģ������ǵ�Ŀ����Ҫ��������YiY_iYi?ʱ��������ӵ��ʡ�Tom������Chase������Jerry����YiY_iYi?��ע����������ʷֲ�Pdf(��)Pdf(\alpha)Pdf(��)
��ô���ǾͿ�����iiiʱ�̵�����ڵ�״̬HiH_iHi?,ȥ�����������ÿ�����ʶ�Ӧ��RNN����ڵ�״̬hjh_jhj?���жԱȡ�����ͨ������F(hj,Hi)F(h_j,H_i)F(hj?,Hi?)�����Ŀ�굥��YiY_iYi?��ÿ�����뵥����Ӧ�Ķ����������(���FFF�����ڲ�ͬ��������ܻ��ȡ��ͬ�ķ���)��Ȼ����FFF���������Softmax���й�һ���͵õ��˷������ʷֲ�ȡֵ������ע����������ʷֲ���ֵ��
2.1 AM Decoder����
ʹ����attentionģ�͵Ľ��벿�ֵ���������д��
p(yi�Oy1,��,yi?1,X)=g(yi?1,si,ci)p(y_i|y_1,\ldots,y_{i-1},X)=g(y_{i-1},s_i,c_i)p(yi?�Oy1?,��,yi?1?,X)=g(yi?1?,si?,ci?)��ʽSiS_iSi?��ʾ������iʱ�̵�����״̬�����㹫ʽ��
si=f(si?1,yi?1,ci)s_i=f(s_{i-1},y_{i-1},c_i)si?=f(si?1?,yi?1?,ci?)ע�����������������ÿ��Ŀ�����yiy_iyi?���Ӧ����������CiC_iCi?�йء�CiC_iCi?�ļ��㹫ʽ�������Ľ��ܵļ�Ȩ���ʽ��
������ʹ��˫��RNN�ı��������������Ϊhih_ihi?�а��������������е�i�����Լ�ǰ��һЩ�ʵ���Ϣ���������������а�Ȩ����ӣ���ʾ�����ɵ�j�������ʱ���ע���������Dz�ͬ�ġ������Ҫ������i?1i-1i?1���������״̬si?1s_{i?1}si?1?�������и�������״̬������ע�����ֲ���
д�ɹ�ʽ��
aij=exp(eij)��k?1Txexp(eik)a_{ij}=\frac{exp(e_{ij})}{\sum_{k-1}^{T_x}exp(e_{ik})}aij?=��k?1Tx??exp(eik?)exp(eij?)? eij=a(si?1,hj)e_{ij}=a(s_{i-1},h_j)eij?=a(si?1?,hj?)
��\alpha����Ȩֵ����a��һ�ֶ��뷽ʽ(alignment model)
Ҳ����˵��si?1s_{i?1}si?1?�ȸ�ÿ��hhh�ֱ����õ�һ����ֵ��Ȼ��ʹ��softmax�õ�iʱ�̵������TxT_xTx?����������״̬�е�ע�������������������������Ҳ���Ǽ���CiC_iCi?��Ȩ�ء�
���������ٰѹ�ʽ����ִ��˳�����һ�£�
eij=a(si?1,hj)��ij=exp(eij)��k=1Txexp(eik)ci=��j=1Tx��ijhjsi=f(si?1,yi?1,ci)yi=g(yi?1,si,ci)\begin{aligned} &e_{ij}=a(s_{i-1},h_j)\\ &\alpha_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\\ &c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j\\ &s_i=f(s_{i-1},y_{i-1},c_i)\\ &y_i=g(y_{i-1},s_i,c_i) \end{aligned} ?eij?=a(si?1?,hj?)��ij?=��k=1Tx??exp(eik?)exp(eij?)?ci?=j=1��Tx??��ij?hj?si?=f(si?1?,yi?1?,ci?)yi?=g(yi?1?,si?,ci?)?
2.2 Encoder ����
����һ����������������-�������ģ�ͣ�
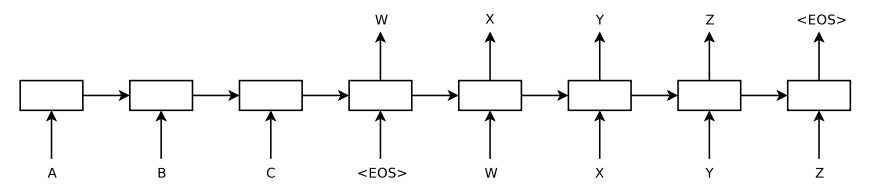
ABCΪencoder�����룬WXYZΪdecoder�����롣encoder�Ὣ���õ������ز��״̬hth_tht?���뵽decoder�ĵ�һ��cell���˴������Ͽ��������뵽�������һ�������Ե�����������
������˵��encoder�Ĺ�������ͼ��

��Ӧdecoder�Σ�

�õ���encoder represention����encoder�����һ��ʱ�䲽��������ht�Ժ����뵽decoder�ĵ�һ��cell�Ȼ��ͨ��һ���������softmax�㣬�õ���ѡ��symbols��ɸѡ����������symbol��Ȼ����Ϊ��һ��ʱ�䲽�������룬����cell�С����������Ǿ͵õ������ǵ�Ŀ��p(y)=��t=1Tp(yt�O{y1,y2,...yt?1},C)p(y)=\prod_{t=1}^{T}p(y_t|\{y_1,y_2,...y_{t-1}\},C)p(y)=��t=1T?p(yt?�O{ y1?,y2?,...yt?1?},C)
2.3 AM Encoder �������
������NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE �У�Seq2Seq With Attentionʱ�����ߴ���Encoders��ͨ��˫��RNN�����˴��������������洦��Decoder����������Ȩ�أ�
��ʾ��ͼ��ʾ��

��ͼ�У�encoder��decoder�������˱仯������encoder��ʹ����˫��RNN����Ϊϣ�������ܵõ�ǰ��Ĵʵ�˳��ϣ���ܹ��õ�����Ĵʵ�˳��ʹ��hj��\overrightarrow{h_{j}}hj??����hjh_jhj?ǰ�������״̬��ʹ��hj��\overleftarrow{h_{j}}hj??����hjh_jhj?�ķ�������״̬��hjh_jhj?������״̬Ϊ���������ӣ�concat����������hj=[hj��;hj��]hj=[\overrightarrow{h_{j}};\overleftarrow{h_{j}}]hj=[hj??;hj??]
����������ԭ���Ǵ�ͳ�ĵ����RNN�У������ǰ�˳������ģ���˵�j������״̬h��j\overrightarrow h_jhj?ֻ��Я����j�����ʱ����Լ�֮ǰ��һЩ��Ϣ��������������룬��hj��\overleftarrow{h_{j}}hj??������j�����ʼ�֮���һЩ��Ϣ����������������������hj=[hj��;hj��]hj=[\overrightarrow{h_{j}};\overleftarrow{h_{j}}]hj=[hj??;hj??]�Ͱ����˵�j�������ǰ�����Ϣ��
[1]https://blog.csdn.net/malefactor/article/details/50550211
[2]https://www.cnblogs.com/sxron/articles/7039699.html
[3]https://blog.csdn.net/u014595019/article/details/52826423
[4]https://arxiv.org/pdf/1409.0473.pdf