机器翻译阅读笔记-2
- 第二章 词法、语法及统计建模基础
-
- 1 问题概述
- 2 概率论基础
-
- 2.1 联合概率、条件概率、边缘概率
- 2.2 链式法则
- 2.3 贝叶斯法则
- 2.4 KL距离和熵
- 3 中文分词
-
- 3.1 基于词典的分词方法
- 3.2 基于统计的分词方法
- 4 n-gram语言模型
-
- 4.1 建模
- 4.2 未登录词和平滑算法
-
- # 加法平滑
- 古德-图灵估计法
- 5 句法分析(短语结构分析)
-
- 5.1 句子的句法树表示
- 5.2 上下文无关文法
- 5.3 规则和推导的概率
第二章 词法、语法及统计建模基础
1 问题概述
机器翻译系统=前/后处理+翻译引擎。
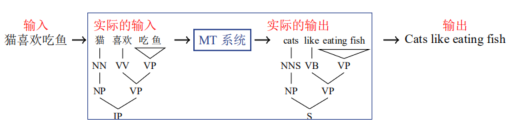
预处理和后处理是对文字序列进行,即对文字序列进行分词和词法分析。
2 概率论基础
2.1 联合概率、条件概率、边缘概率
联合概率P(A∩B):指多个事件共同发生,每个随机变量满足各自条件的概率。
条件概率:
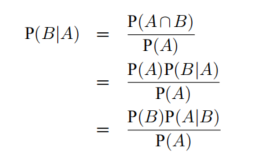
边缘概率:仅与单个随机变量有关的概率。例如P(X=a)或P(Y=b)。
三者之间的关系:

2.2 链式法则
n个事件同时发生的概率,链式法则的公式:
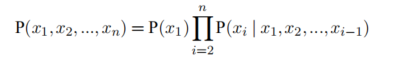
例如:有ABCDE五个事件,同时发生的概率
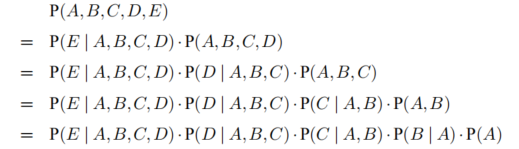
2.3 贝叶斯法则
全概率公式:
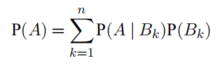
贝叶斯法则:已知P(A|B),求P(B|A)。贝叶斯公式常用于根据已知的结果推断使之发生的各因素的可能性
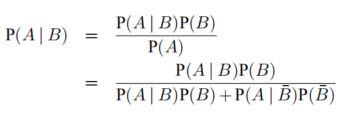
2.4 KL距离和熵
熵:对系统无序性的一种度量标准。
nlp领域中,常用来描述文字的信息量大小。此外一个事件的不确定性越高,信息熵越高。
信息熵:量化整个概率分布中的不确定性或信息量
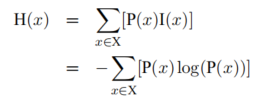
自信息:用来衡量单一事件发生时所包含的信息多少。处理变量单一取值的情况
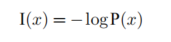
分布越尖锐,熵越低;分布越均匀,熵越高。
KL距离:用来衡量同一个随机变量X上有两个概率分布P(x)和Q(x)的不同。即相对熵
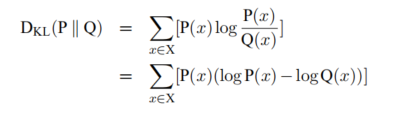
KL距离具有非负性和不对称性。
交叉熵:与KL距离的目的相同,用来描述两个分布的差异。且交叉熵计算上方便,在机器翻译中广泛应用。
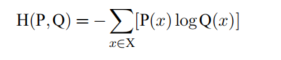
3 中文分词
机器翻译的第一步就是开发出适合翻译任务的分词系统。
分词方法有两种,基于词典的分词方法和基于统计的分词方法
3.1 基于词典的分词方法
给定一个词典,通过词典定义一个标准。符合这个标准定义的字符串都是合法的‘词’。
只需预先加载词典到计算机中,扫描输入句子,查询每个词串是否出现在词典中。
缺点:由于自然语言灵活,这种方法经常出现歧义。
3.2 基于统计的分词方法
标注数据:已经切分好的数据
分为两步,①训练:利用标注数据,对统计模型的参数进行学习;②推断:利用学习到的模型和参数对新的句子进行切分
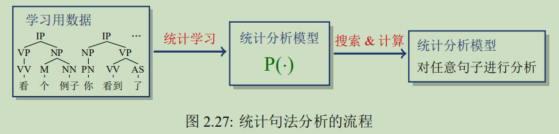
典型的方法有全概率分词方法(1-gram语言模型)。分词系统的学习和使用过程如下图所示,利用大量人工标注好的分次数据,通过统计学习方法获得一个统计模型P(・),即分词模型。对于一个新句子,使用模型列举出不同的切分方式并计算其概率,其中概率最高的,即为输出。

4 n-gram语言模型
4.1 建模
使用统计建模的方式,语言模型被定义为计算 P(w1w2…wm)的问题。统计语言建模把整个序列生成的问题转化为逐个生成单词的问题。
n-gram语言模型可认为只考虑前面n-1个历史单词来生成当前单词。那么P(w1w2…wm)便被重新定义为:

对于P(wm|wm n+1…wm 1)的计算有两种方法。①极大似然估计,利用词序列出现的频度。
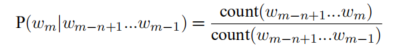
②人工神经网络方法,构建一个人工神经网络估计该值。例如构建前馈神经网络对n-gram建模
4.2 未登录词和平滑算法
未登录词:根本没有在词表中出现过的词
未登录词会引起0概率的问题,为解决此问题,对模型进行平滑处理(“劫富济贫”)。即给可能出现的情况一个非0的概率,使得模型不会对整个序列给出0概率。
平滑算法主要有加法平滑法、古德-图灵估计法和Kneser-Ney平滑。
# 加法平滑
假设每个n-gram出现的次数比实际统计次数多θ次,0≤θ≤1。这样便不会存在概率为0的情况。
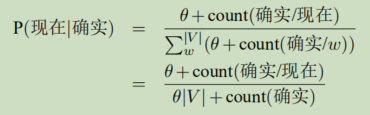
V 表示所有词汇的词表,|V| 为词表中单词的个数,w 为词典中的一个词。当 θ 取 1,这时称之为加一平滑或是拉普拉斯平滑。
古德-图灵估计法
假设语料库中出现r次的n-gram有nr个,例如出现0次的n-gram(未登录词)的出现次数为n0个。
为解决0概率的问题,对于任何一个出现r次的n-gram,此法利用出现r+1次的n-gram统计量重新估算r,如下公式:
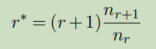
则每个统计数为r的事件,概率为 Pr = r*/N
经过此方法,使得所有出现为0次事件的概率为n1/N
5 句法分析(短语结构分析)
NLP中常用的两种句法分析形式是短语结构分析(成分分析、完全分析)、依存分析。
5.1 句子的句法树表示
短语结构树:
叶子节点为单词,中间节点为词性或短语句法标记。
在短语结构分析中,单词――终结符,词性――预终结符,其他句法标记――非终结符。
依存句法树:无预终结符和非终结符。所有节点都是句子里的单词。

5.2 上下文无关文法
计算机实现对句子结构的归纳过程使用到了形式文法。形式文法有四种类型:无限制文法(0 型文法)、上下文相关文法(1 型文法)、上下文无关文法(2 型文法)――短语结构分析,和正规文法(3 型文法)――描述有限状态自动机。
一个上下文无关文法可以被视为一个系统 G =< N,Σ,R,S >,其中
? N 为一个非终结符集合
? Σ 为一个终结符集合
? R 为一个规则(产生式)集合,每条规则 r ∈ R 的形式为 X → Y1Y2…Yn,其
中 X ∈ N, Yi ∈ N ∪Σ
? S 为一个起始符号集合且 S ? N
上下文无关文法的规则是一种产生式规则。左右两边满足规则便可相互替换。
推导是描述句法分析树的一种方式。为了消除歧义,要求规则使用都服从最左优先原则,称为最左优先推导。
5.3 规则和推导的概率
为了达到对使用的规则进行概率化,从而对句法树进行概率化的目的,使用概率上下文无关文法
概率上下文无关文法的定义和上下文无关文法的定义大同小异,区别是在R中,每个r对应了一个概率p,表示其生成的可能性。
其中规则的概率p=树库(treebank)中规则左右同时出现的次数 / 规则左边出现的次数,即

树库是指包括很多人工标注句法树的句法。若左右同时出现的次数为0,则使用平滑方法对概率进行平滑处理。
基于统计的句法分析的流程:①通过树库的统计,获得各个规则的概率,得到一个模型。②使用模型对任意句子进行分析,计算每个句法分析树的概率,将概率最高的树作为句法分析的结果。如图: