ժҪ
���߳ƣ����ж������������ڵ�����ѵ�����Ͻ���ѧϰ���ⲻ������ʵ���ն�ͼ���������ʵ�ص㡣ͬʱ���߷����ڵ��ն�ͼ���е������ڲ�ͬƵ�ȱ��ֲ�ͬ����Ƶ�������Ƶ�����������������Ҹ����ױ����ƣ������IJο�������29��41�������������һ�����磬�ܹ����ڵ�Ƶ��ָ�ͼ������ڻָ���ͼ���������ǿ��Ƶϸ�ڡ����������һ���µ�sRGB���ն�ͼ�����ݼ������г����dz���SID����ʹ��RAWԭʼ���ݲ�������Ŀ��ǣ����������ACE��CDT������ģ�顣

�ò����Լ��ĵĻ���˵�����������£�
- ������ն�ͼ�������Լ�������RAWתsRGB���ݼ�����
- ������һ�ε�ACEģ�飬�м�ʹ����Ƶ��ṹ��ϢͼCa��\bar{C_a}Ca?��?�����õ�Ƶ�ʸ�֪�DZ�������xoutx_{out}xout?��
- ��xoutx_{out}xout?����������ṹ������CDTģ�飩��Ҳ��ʹ�õ�Ƶ��Ϣ�õ�����CCC���ٷŴ�
- ���Ŵ�õ���IaI^aIa����ڶ��ε�ACE����ʱʹ�õ�����Ƶϸ����CaC_aCa?�����õ���Ӧ��xoutx_{out}xout?��
- ����xoutx_{out}xout?���ڶ��εı�����루����CDTģ�飩��ʹ�ø�Ƶϸ�ڽ����ع��ӹ���
- ������ؼ���ӵõ�������ǿ�����
�ܵ���˵���������õ�Ƶ��������������ڵ�Ƶ������������ͬʱ��Ƶ�����ͼ�����Ҫ�ṹ��Ϣ���ⶼ��������ĵ�һ���н��д�������һ������Ҫȥ����Ƶ���Ӱ�죻����Ƶ�����ͼ��ϸ�ڣ��ڵڶ����ع���ʱ���õ����ܹ�����ǿͼ����ȣ���ֹģ����
introduction
e��d��f�ǵ��ն�ͼ����ǿ�����c��d�ֱ�������ʹ�ø�˹�˲����õ��ĵ�Ƶ���Ƶ�㣬��Ƶ���г�����������g��GT��h�����߷����Ľ�������߳����е��ն�ͼ����ʱ��ǿ��ͼ���Ծɱ��ֽϵ͵�����ȣ�SNR��������е�����˵��ǿ���ͼ��PSNRֵ�Ƚϵͣ�����ʵ���ϣ���Щ��ǿ���ͼ��ʹPSNRֵ�ϸߣ�Ҳ�������ã���ΪPSNR��̫�ܴ��������۹۲��ϲ�ã����ڸ�ֵȴ��������ʧ��������

����ȥ��
���߳ƣ�֮ǰ��ͳ�����в��������������ԡ�ϡ���Ժ͵��ȣ�low rank����������ȥ�룬�������ѧϰ��һЩģ�ͣ�������Щ����ͨ���Ӽ����м��ԣ�addactive�������������߸�˹������ѵ������������ʵ���������һЩ����ʹ�õ����ϳ����ݻ��ߵ�����ʵ���ݣ�������������һ�𣬻����ල������ѵ��������Ч������̫���롣
���߳���Щ��ʽ��û�п��ǵ������صĵ��ն�ͼ�������ṩ�㹻��������Ϣ�����ﲻ�Ǻ����������ȥ�룻ͬʱ����ǿͼ���ʱ��ijЩ�����ᱻ������Ԥ��ء��Ŵ�ʵ�������ַ������ɱ��⣬��������Ҳ�����Ӧ��Ҳ��Ϊ��д��д��
ģ�ſ�
��һ�Σ�
IaI^aIa�ǷŴ��ĵ�Ƶ�㣻C(?)C(\cdot)C(?)�ǵ�Ƶͼ����ǿ������A(?)A(\cdot)A(?)����ɫ�ָ��Ŵ�����
���߳����������ʽ���Բ���ѧϰȫ����Ϣ�����������;ֲ���Ϣ������ɫ�����Ӷ������ǿ���
��һ����ǿ��Ia=��A(C(I))?C(I)I^a=\alpha A(C(I))\cdot C(I)Ia=��A(C(I))?C(I), ��\alpha���ǿ�ѧϰ��ȫ�ֱ�����
�ڶ��Σ�
û��ʹ�ó���������ԭʼͼ����ʹ����һ��������IaI^aIa��ѧϰ��Ƶϸ�ڣ����и�Ƶϸ����ǿ����D(?)D(\cdot)D(?)��Ȼ���òв�ķ�ʽ��D(?)D(\cdot)D(?)���н�ģ��
Ic=Ia+D(Ia)I^c=I^a+D(I^a)Ic=Ia+D(Ia)
��ͼΪ���ν�����ӻ���d-h����

Attention to Context Encoding��ACE��ģ��
ACEģ���Ŀ����ѧϰ����ͼ��ֽ��Ƶ�ʸ�֪������ACE��չ�˷Ǿֲ�����[42]��ѡ��Ƶ������Ӧ��������Ϣ���ò��������Ϊ����Զ�̹�ϵ������ġ�
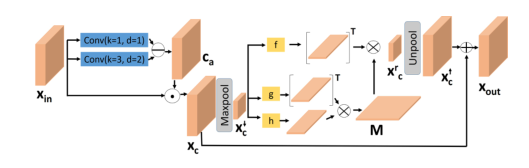
�������������;���d1��d2��Ȼ��ͨ����ʽ��Ca=sigmoid(fd1(xin)?fd2(xin))C_a = sigmoid(f_{d1}(x_{in})-f_{d2}(x_{in}))Ca?=sigmoid(fd1?(xin?)?fd2?(xin?))���õ��Աȶȸ�֪ע����ͼCaC_aCa?�����������ؼ��ĸ�Ƶ��Ϣ����ͨ��C��a=1?Ca\bar{C}_{a}=1-C_aC��a?=1?Ca?���õ�������Ƶ��Ϣ��C��a\bar{C}_{a}C��a?����ACE��CDTģ���У������ڵ�һ����C��a\bar{C}_{a}C��a?������Ƶ��Ϣ�����ڵڶ���ʹ�� CaC_{a}Ca?����Ƶ��Ϣ��ͬʱxc=C��a?xinx_c=\bar{C}_{a} \cdot x_{in}xc?=C��a??xin?��
��һ�εڶ���ACE�㹲������
��ͼ��ACE������ӻ���

Cross Domain Tranformation��CDT��ģ��

��ģ��������ǣ���С���ն�ͼ�����ǿͼ��֮��������ࣨ���룩���õ��Ǻ�����39һ�������Ӹ���Ұ�ѻ�ø���ȫ����Ϣ�ķ�����
�ڵ�һ�Σ�
���Ա����������������ڿռ���ͨ����Աȶȸ�֪ͼC��a\bar{C}_aC��a?��������Ƶϸ�ڣ����߶Աȶȵ�����ϸ�ڣ���Ȼ������Ӧ�ı�����������xdex_{de}xde?���ӡ��ٴ�����[xen,xde][x_{en}, x_{de}][xen?,xde?]����ȫ����������vvv����ͨ������Ӧ�ķ�ʽ�����Ų�ͬ�����������en��������de�������������ܿ�������������ͼ��
�ڵڶ��Σ�
ʹ�öԱȶȸ�֪ͼCaC_aCa?������Աȶȸ�֪ͼ����ACEһ���IJ�����
���ݼ�
�������ݼ�����SID���ݼ�����������SID�е�RAW���ԭʼ���������Եģ����ձ�ʹ�õ�sRGB����ͨjpg֮��ģ�Ϊ�����Եġ����ң��������ԭʼ���ݺ�sRGB�ķ���������ȫͬ�Ȼ��ã����в�ͬ�ġ���������ͨ���������棬����RAW���ԭʼ���ݣ���ɿ�ʹ�õ�sRGB���ݼ����عⲹ������ƽ���ȥ���Ի���
- �عⲹ���������عⲹ����ÿ������ı�����̫һ�£�������0.5EV�ļ����[0EV��2EV]�����ȡ�عⲹ��ֵ
- ��ƽ�⣺���ڰ�ƽ����ÿ�������Ҳ��̫һ�£�����ѡ����[2100K��4000K]��Χ�ڵ�ɫ�£����ʾ���͵ļ�ͥ�������ճ�/����������ɫ�¡�
- ȥ���Ի�������ÿ�������Ӧ����������ķ����Բ�ͬ�����ѽ������̣�17�����������������磨12�������飬ʹ��٤��������ȥ���Ի�����٤�������ܹ�����
���յõ�4198������ѵ����ͼ��Ժ�1196�����ڲ��Ե�ͼ��ԡ�
loss
loss�����Լ�
Lacc=��1�O�OC?Ifgt�O�O2+��2�O�OIc?Igt�O�O2L_{acc}=\lambda_1|| C-I^{gt}_{f}||_2 + \lambda_2|| I^c-I^{gt}||_2Lacc?=��1?�O�OC?Ifgt?�O�O2?+��2?�O�OIc?Igt�O�O2?
�õ�L2 loss��CCC���ع����ݣ�IfgtI^{gt}_{f}Ifgt?�ǵ�Ƶ���GT��IcI^cIc����ǿ���ع������ͼ��IgtI^{gt}Igt����ǿͼ���GT������Ҫ���������Ƶ���Ӧͼ�����ݣ���ǿͼ���Ӧ��ǿͼ���GT������ǰ������ϵ����ͬʱ������һ��VGG loss��Lvgg=��3�O�O?(Ic)??(Igt)�O�O1L_{vgg}= \lambda_3|| \phi(I^c)-\phi(I^{gt}) ||_1Lvgg?=��3?�O�O?(Ic)??(Igt)�O�O1?��?\phi?��VGG��
experiments



ע������Ķ��ԱȽ��У�����ͨ���������Լ���sRGBѵ��������ѵ��ԭ��ʹ��RAW���ݵ�SID������չʾ���߷�������Ч�ԣ������е�*������������ʵ���У�ͨ�����������Ŀ��Ʊ�������֤����������ȷʵ�ܹ�������ܡ��Լ�һ���ǣ���ʹ����ǿ��������LIME��������ʹ�ô�ͳȥ��BM3DЧ���û�����ȥ����ʹ��BM3DЧ���ã����˼·������֤����������ǰ�����������е���һ���������ܺܺý���������ֻ����ͨ�����ѧϰ��������Ƭ�ع���ǿ���ܺܺõ�ȥ��������