End-to-End Multi-View Fusion for 3D Object Detection in Lidar Point Clouds 谷歌2019
先验知识:
1).在鸟瞰图BEV中,物体保持其规范的三维形状信息,并自然可分离,而透视图的缺点是对象的形状不是距离不变的。
2).VoxelNet的体素化被称为硬体素化(hard voxelization,HV),因为一个体素可能被分配了比它的固定点容量T所允许的更多的点,每个体素中只能采样抽取固定的T个点。相似的,如果点云产生的体素大于固定体素容量V,则对体素进行降采样。另一方面,当点(体素)比固定容量T (V)少时,缓冲区中未使用的条目将被填充为零。
3).硬体素化有局限性:
(1)当点和体素超出缓冲容量时被丢弃,HV迫使模型丢弃可能对检测有用的信息;
(2)点和体素的随机缺失也可能导致不确定的体素嵌入,从而导致检测结果的不稳定或抖动
(3)填充的体素消耗了不必要的计算,阻碍了运行时的性能。
1.文章出发点
瞰视图(BEV)中的点云体素化,点云稀疏且具有高度可变的点密度,这可能导致检测器难以检测到远处或较小的物体(行人、交通标志等)。另一方面,透视视图提供了密集的观察,这可以允许对这样的情况进行更灵活的特征编码。所以两者结合可有效地学习利用两者的组成信息。 本文中关注的是怎么融合相同传感器的不同视图。与其他融合算法相比,作者的工作介绍了一种在点级而不是体素或ROI级操作的逐点特征融合方法。在通过ROI或体素级别对点进行聚合之前就已经融合了,它可以更好地保留LiDAR数据的原始3D结构。
2.文章主要贡献:
1):特征融合网络结构,对于BEV编码,我们使用垂直列体素化(Pointpillars的体素化方法,它在精度和延迟方面都提供了非常强的基线。对于透视嵌入,使用了2D卷积塔, 通过感受野的变化,在特征图上聚合大范围内的信息,有助于缓解点稀疏性问题。
2):提出了动态体素化(DV),其优点有:
a.消除了对每个体素采样预定义数量的点的需要。这意味着每个点都可以被模型使用,最大限度地减少信息损失。
b.消除了将体素填充到预定义大小的需要,即使它们的点明显较少。这可以极大地减少HV带来的额外空间和计算开销,特别是在点云变得非常稀疏的较长的范围内。例如,以前的模型如VoxelNet和pointcolumn为每个voxel(或每个等效的3D卷)分配100个或更多的点。
c.克服了点/体素的随机缺失,产生了确定的体素嵌入,使得检测结果更加稳定。
d.它是融合来自多视图的点级上下文信息的自然基础
3.体素和特征编码
dynamic voxelization (DV):
DV保持了分组阶段的不变,但是,它没有将点采样到固定数量的固定容量体素中,而是保留了点与体素之间的完整映射。因此,体素的数量和每个体素的点的数量都是动态的,这取决于特定的映射(mapping)函数。对每个point都建立起一个和voxel的mapping,也就是说,point->voxel是一对一的关系(hard编码下有可能是1对0),voxel->point是一对多或者一对0的关系(hard编码下不可能有1对0)。这消除了对固定大小缓冲区的需要,并消除了随机点和体素dropout。
如下图所示,HV和DV的直观展示,通过对比可以看出其中硬体素化占了15F内存,而动态体素化只占了13F:

4.特征融合

1.首先采用原始的LiDAR点云绝对坐标(相对于雷达坐标系)作为输入。经过vfe(voxel feature encoding)或者pfe(pillar feature encoding)的时候,需要转换成对应voxel或pillar的相对坐标,也就是对于每个点,我们在其所属的体素或锥体中计算其局部3D坐标。两个视图的点的局部坐标和强度在通过FC层之前进行拼接,FC层由线性层、批归一化(BN)层和整流线性单元(RELU)层组成。对于一帧点云(可以表达称nx4),先经过一个fc转换成nx128;这个nx128的特征将作为不同view的输入,该层特征供不同的视图共享。
2.接下来,在每个视图中,我们进行一个FC+Max操作,max操作并不是用conv实现的,而是用有一个函数实现的。再使用卷积塔(借鉴了FPN) 在扩大的感受野的基础上结合上下文信息,同时保持相同的空间分辨率。卷积塔的输入是一个二维的(因为用的是Pointpillars体素化方法),再通过最大合并将每个体素内的所有点聚合成一个特征,得到体素级别信息。
3.最后,使用点到体素映射F?P(VJ),对每个点进行来自三个不同信息源的特征融合:1)鸟瞰该点对应的笛卡尔体素,2)透视视图该点对应的球形体素,3)共享FC层的逐点特征。可以任选地将逐点特征变换为较低的特征维度,以降低计算成本。
5.损失函数
和VoxelNet的损失一样(注明一点,网络的输出是坐标偏移,定位的损失是拿坐标偏移作为被减数和减数来做差计算的,同Faster-Rcnn),:
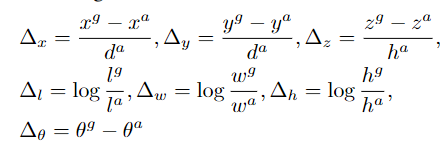
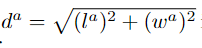
回归损失:

分类损失用的focal loss:
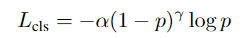
6.实验结果:

动态体素化和多视角融合技术确实显著提高了检测精度。