Deep Continuous Fusion for Multi-Sensor 3DObject Detection
ECCV 2018
1.摘要+intro
如何设计能够更好地利用多种模态的三维探测器仍然是一个有待解决的问题。本文提出了一种基于鸟瞰(BEV)的三维目标检测器,通过学习将图像特征投影到BEV空间进行融合,设计了一种端到端的可学习结构,利用连续卷积对不同分辨率的图像和LIDAR特征图进行融合。提出的连续融合层能够对两种模式下位置间的密集精确几何关系进行编码,从而设计出一种新颖、可靠、高效的基于多传感器的三维目标检测器。
2.method
我们利用卷积网络提取图像特征,然后将图像特征投影到BEV中,并与基于LIDAR的检测器的卷积层进行融合。因为图像特征发生在离散的位置,因此,需要“插值”来创建密集的BEV特征图。为了执行该操作,我们利用连续卷积从BEV空间中每个点的最接近的对应图像特征中提取信息。
我们的总体架构包括两个流,一个流提取图像特征,另一个流从LIDAR的Bev提取特征。我们设计了连续融合层来连接两侧的多个中间层,以便在多个尺度上进行多传感器融合。
2.1. 连续融合层
深度可连续卷积
作者认为连续卷积很适合本次任务,因为摄像机视图和Bev都是通过3D点集连接的,而无损地建模它们之间的几何关系是信息融合的关键。可连续卷积就是根据每个邻居相对于目标点的几何偏移,对每个邻居进行不同的加权。其中fj是输入特征,其中j是在点i邻域上的索引,Xj是邻域的连续坐标
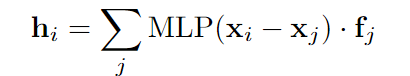

Continuous Fusion Layer

这里提出的连续卷积融合层相当于连续卷积。在给定输入摄像机图像特征映射和一组LIDAR点的情况下,目标是创建密集的BEV要素地图(因为BEV上有些像素是空的),其中每个离散像素包含从摄像机图像生成的特征。
首先对于BEV密集特征图中的每个目标像素,我们使用欧式距离在2DBev平面上找到其最近的K个LIDAR点。反投影在3D空间中。然后投影到图像平面,采用双线性插值法提取连续坐标系下的图像特征。然后,编码了密集BEV特征图上原始的LIDAR点与目标像素之间的3D相邻偏移为了建模它们之间的几何关系,将邻域点的图像特征+连续几何偏移喂给MLP(这里就相当于上述的可连续卷积),预测得到该BEV目标点的特征值。
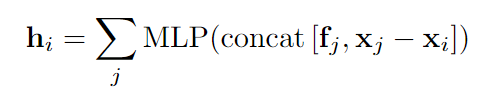
Comparison against Standard Continuous Convolution:
与标准的深度可连续卷积相比,所提出的连续融合层利用mlp直接输出目标特征。而标准的深度可连续卷积通过MLP只输出权重然后再对所有特征进行sum。内存效率提升,因为不需要显式地在GPU存储器中存储额外的权重矩阵。
2.2 网络结构

使用四个连续的融合层将多个尺度的图像特征自下而上地融合到BEV网络中,这样做能相当于一个交叉融合,每个送往BEV特征都来自于三个不同尺度的特征,而不像是直接对应尺度融合仅仅来自于单一尺度的图像特征图。BEV空间中的输出特征与对应的BEV层具有相同的形状,通过元素级相加组合成新的BEV。最终BEV特征输出还以类似于FPN的方式组合了最后三个残差组的输出,以便利用多尺度信息。
检测头:在最终的BEV层上计算1×1卷积层来产生检测输出。在每个输出位置,我们使用两个固定大小和两个方向的anchor,分别为0和π/2弧度。每个anchor的输出包括每像素类置信度及其相关框的中心位置、大小和方向。 最终采用NMS生成最终对象框
loss为正常的交叉熵分类损失加L1回归损失:
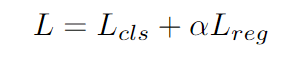
3.实验结果
