- ����ʱ�䣺2018-12-05
ǰ��
֮ǰ������AutoEncoder���伸����չ�ṹ����DAE��CAE�ȣ���ƪ���ͽ���ջʽ�Ա�������
ģ�ͽ���
��ͨ��AEģ��ͨ�������������̣��õ��������С����������IJ���Ӷ�ʹģ��ѧ�����õ���������������AE�ṹ��һ���ˣ���Ȼ�����˶�ε�������ȡ��������Ŀ�꺯���ļ���ֻ��һ�Σ���ô�����ͨ����ջ����AE�ṹ��������̰��ѵ���õ������ܻ������е�Ҫ���أ�
ʵ���ϣ�Stacked AutoEncoder���Ƕ��AE�ġ�ջ���������������������£�
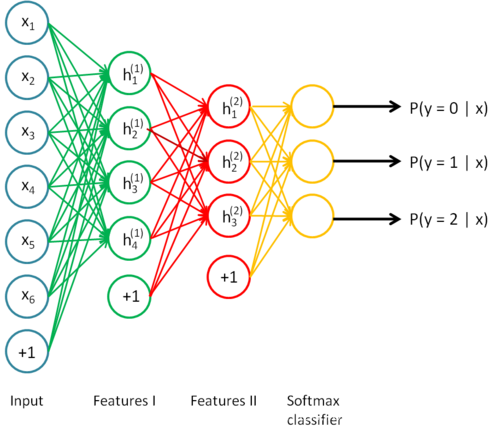
��ͼչʾ����һ��������AE�ṹ���� x i x_i xi?�� h i ( 1 ) h_i^{(1)} hi(1)?�Ĺ���Ϊ������̣��� h i ( 1 ) h_i^{(1)} hi(1)?�� x ^ i \hat{x}_i x^i?�Ĺ���Ϊ������̣�ͨ������£���С����ʧ������ (1) L = �� i = 1 n ( x ^ i ? x i ) 2 L=\sum_{i=1}^n(\hat{x}_i - x_i)^2 \tag{1} L=i=1��n?(x^i??xi?)2(1)
�Ϳ�����ģ��ѧϰ�����õ���������Ȼ�������ʧ������Ψһ��
��ջ��������ָ���ǽ������ͼ��ѵ�������ںϵ�һ��ʹģ���ܹ�ѧ�õ�����Ч����Ϣ��
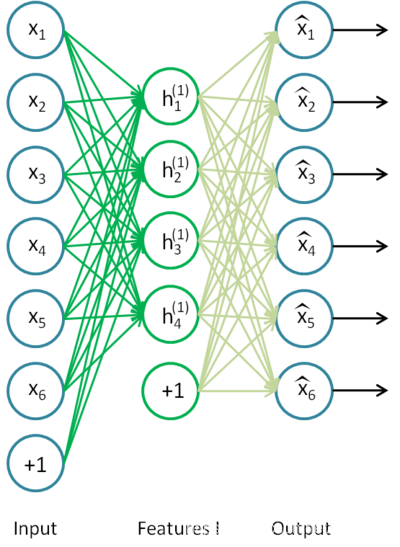
��ջ�������̵Ļ���ʵ��˼�����£�ѵ������ͼ��AE�ṹ����ȥ������̣���ʱ���ǿ�������Ϊcode��4ά������һ���Ľ�ά����ȡ����������������ʱ��code��Ϊ���룬���뵽�µ�AE�ṹ�н���ѵ��������ͼ��ʾ��
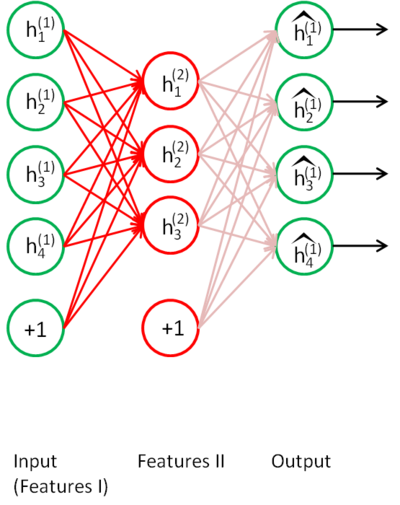
����������ͬ����˼����ѵ�����AE�����������������code��������һ�ν��н�ά������ظ���ʹÿ�εġ�ջ�������̶��ܹ�ѧϰ���������ţ����õ�code��������Ϊ�����code���ܹ���ȡ����Ч����������Ϊ���Ƕ���Ч���ġ����ӡ�����Ӧ�ģ�����ǽ��з��������ֱ�ӽ�code���뵽�������У��Ϳ��Եõ�����������ͼ��ʾ���ǽ�code���뵽softmax�У�
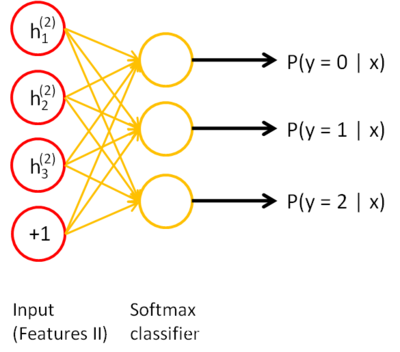
����ջʽ�Ա�����������ѵ�����̿���������ʾ��;��ʡ����ÿ��ѵ���Ľ�����̣�