什么是word2vec?
word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
单词的向量化表示
所谓的word vector,就是指将单词向量化,将某个单词用特定的向量来表示。将单词转化成对应的向量以后,就可以将其应用于各种机器学习的算法中去。一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量。
所谓稀疏向量,又称为one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引[1]。举例来说,如果有一个词典[“面条”,”方便面”,”狮子”],那么“面条”对应的词向量就是[1,0,0],“方便面”对应的词向量就是[0,1,0]。这种表示方法不需要繁琐的计算,简单易得,但是缺点也不少,比如长度过长(这会引发维数灾难),以及无法体现出近义词之间的关系,比如“面条”和“方便面”显然有非常紧密的关系,但转化成向量[1,0,0]和[0,1,0]以后,就看不出两者有什么关系了,因为这两个向量相互正交。当然了,用这种稀疏向量求和来表示文档向量效果还不错,清华的长文本分类工具THUCTC使用的就是此种表示方法
至于密集向量,又称distributed representation,即分布式表示。最早由Hinton提出,可以克服one-hot representation的上述缺点,基本思路是通过训练将每个词映射成一个固定长度的短向量,所有这些向量就构成一个词向量空间,每一个向量可视为该空间上的一个点。此时向量长度可以自由选择,与词典规模无关。这是非常大的优势。还是用之前的例子[“面条”,”方便面”,”狮子”],经过训练后,“面条”对应的向量可能是[1,0,1,1,0],而“方便面”对应的可能是[1,0,1,0,0],而“狮子”对应的可能是[0,1,0,0,1]。这样“面条”向量乘“方便面”=2,而“面条”向量乘“狮子”=0 。这样就体现出面条与方便面之间的关系更加紧密,而与狮子就没什么关系了。这种表示方式更精准的表现出近义词之间的关系,比之稀疏向量优势很明显。可以说这是深度学习在NLP领域的第一个运用(虽然我觉得并没深到哪里去)
回过头来看word2vec,其实word2vec做的事情很简单,大致来说,就是构建了一个多层神经网络,然后在给定文本中获取对应的输入和输出,在训练过程中不断修正神经网络中的参数,最后得到词向量。
模型构建
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words) 与Skip-Gram两种模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。 Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
CBOW
CBOW的训练模型如下图所示:
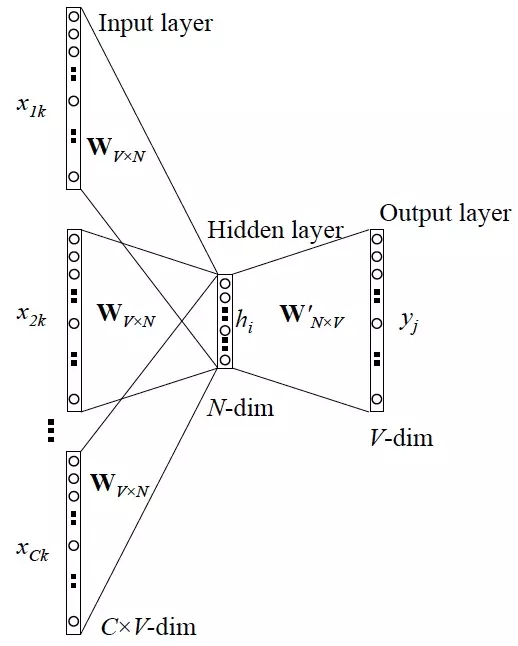
- 输入层:上下文单词的one-hot. {假设单词向量空间dim为V,上下文单词个数为C}
- 所有one-hot分别乘以共享的输入权重矩阵W. {VN矩阵,N为自己设定的数,初始化权重矩阵W}
- 所得的向量 {因为是one-hot所以为向量} 相加求平均作为隐层向量, size为1N.
- 乘以输出权重矩阵W’ {NV}
- 得到向量 {1V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词}
- 概率最大的index所指示的单词为预测出的中间词(target word)与true label的one-hot做比较,误差越小越好(根据误差更新权重矩阵)
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实聪明的你已经看出来了,其实这个look up table就是矩阵W自身),也就是说,任何一个单词的one-hot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
Skip-Gram
从直观上理解,Skip-Gram是给定input word来预测上下文。
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是[‘The’, ‘dog’,‘barked’, ‘at’]。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘dog’, ‘barked’),(‘dog’, ‘the’)。
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。这句话有点绕,我们来看个栗子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 (‘dog’, ‘barked’) 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率大小。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“中国“,那么最终模型的输出概率中,像“英国”, ”俄罗斯“这种相关词的概率将远高于像”苹果“,”蝈蝈“非相关词的概率。因为”英国“,”俄罗斯“在文本中更大可能在”中国“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。
面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。Training Samples(输入, 输出)。
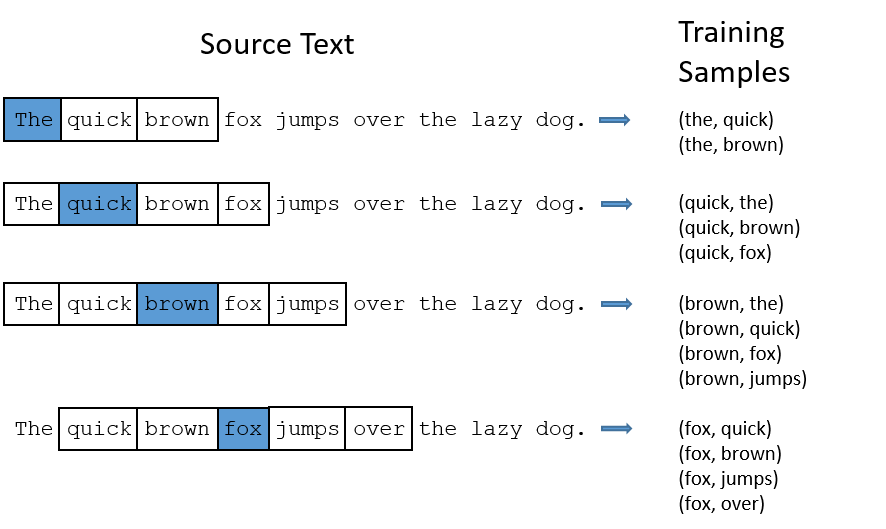
首先,你你知道你并不能把文本字符串直接输入神经网络模型,因此我们需要一种能表示这些词的方式。为了实现这种方式,我们首先从训练语料中构建一个词典-假如说我们有一个10000不同单词的词汇表。
我们用one-hot向量来表示input word “ants”,这个向量有10000组成单元(每一个代表词汇表中的一个词)并且我们将"ants"相应的位置元素置为1,其它位置全部置为0.
Skip-Gram的网络结构:
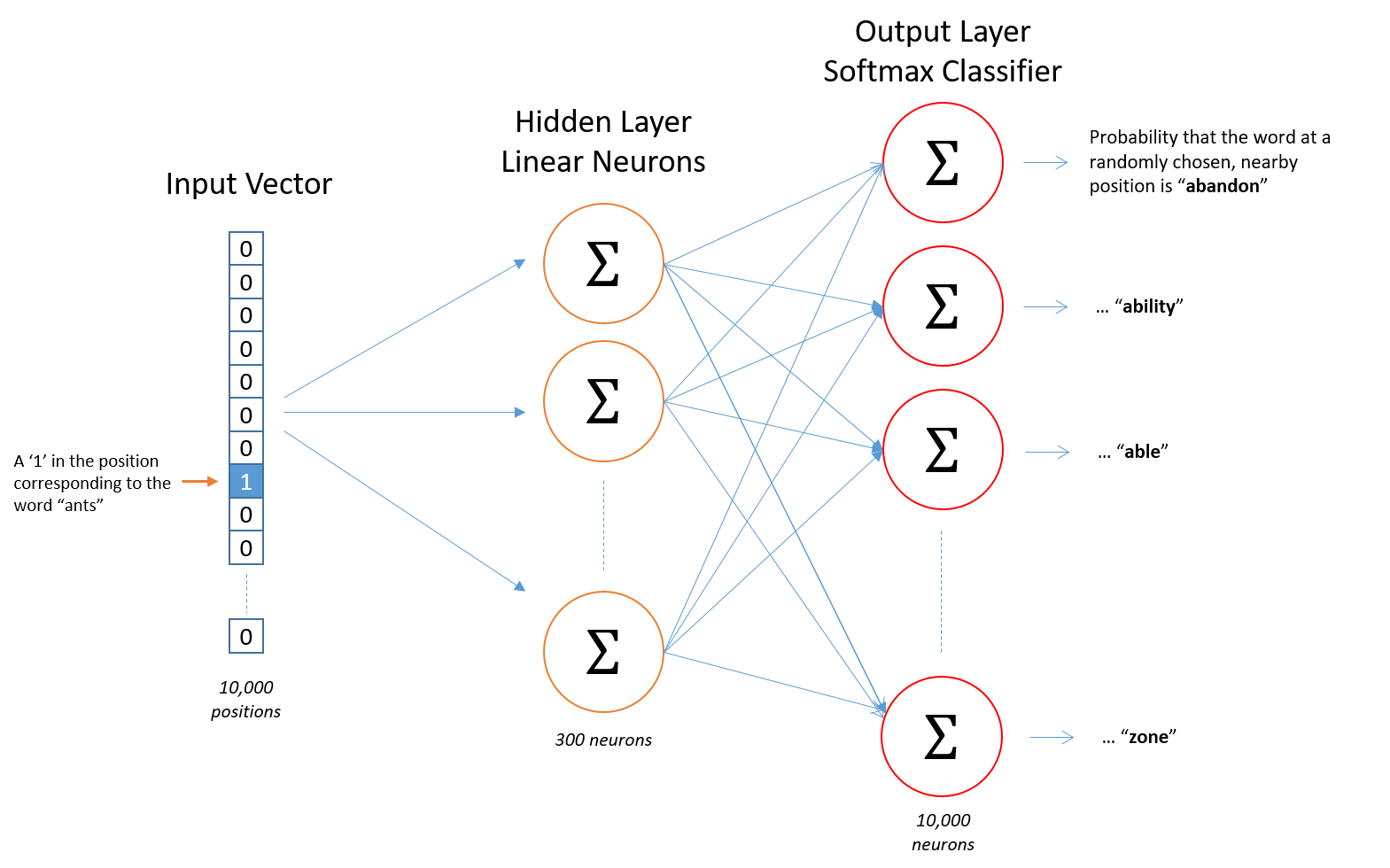
在隐藏层的神经元中没有激活函数,但是输出神经元使用softmax。
当用单词对训练网络的时候,输入的是一个表示input word的one-hot向量并且输出也是一个表示output word的one-hot向量。但是当你用一个input word评价网络的时候,输出向量实际上是一个概率分布(一串浮点型数值,而不是one-hot向量)。
Skip-Gram隐藏层
对于我们的例子来说,我们正在学习一个300维特征的词向量。因此隐藏层可以用一个10000行(每一行对应词汇表中的一个词)300列(每一列对应一个隐藏神经元)的权重矩阵来表示。
如果你看一下这个权重矩阵的行,这些实际就是我们的单词向量。
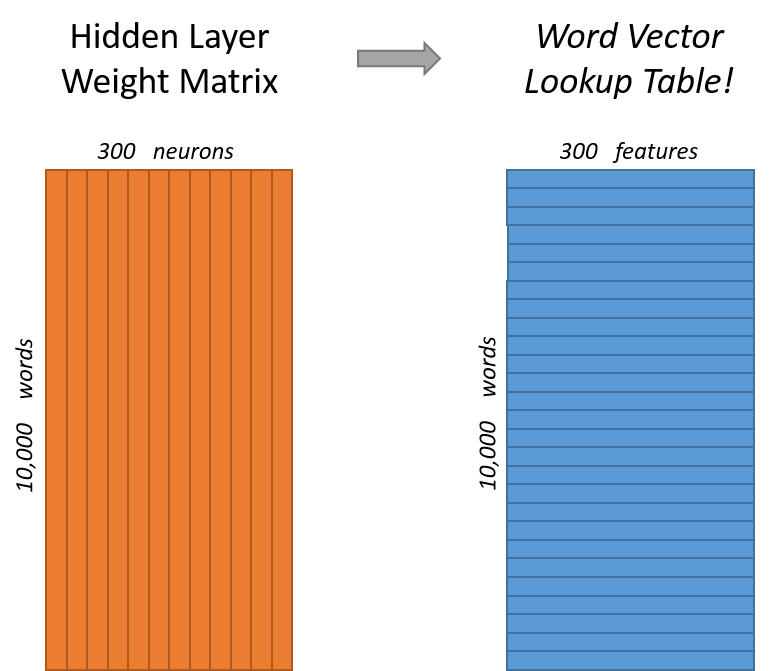
所以最终目标是学习这个隐藏层权重矩阵-当我们训练完成时,我们就会丢弃掉输出层。

这意味着该模型的隐藏层实际上只是作为查找表运行,隐藏层的输出输出只是输入字的 “字向量” 。
python调用API
样例代码:
# -*- coding:utf-8 -*-from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = Word2Vec(min_count=1, size=10) # size:the number of hidden layer neurons
model.build_vocab(sentences) # prepare the model vocabulary
model.train(sentences, total_examples=model.corpus_count, epochs=model.iter) # train word vectors
vector = model.wv['dog'] # numpy vector of a word
print(vector)样例输出:
[ 0.00883317 0.04478928 -0.01250693 0.0334021 -0.0213156 0.04220686 0.00417733 -0.04854728 0.02249074 0.00690281]
项目数据处理源代码
- https://github.com/rogeroyer/dataCastle/blob/master/DaGuan_Cup_2018/word_to_vec.py
参考文献
[1] https://www.jianshu.com/p/471d9bfbd72f
[2] http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
[3] https://zhuanlan.zhihu.com/p/26306795
[4] https://www.zhihu.com/question/44832436/answer/266068967
[5] https://blog.csdn.net/u014595019/article/details/51884529
[6] https://radimrehurek.com/gensim/models/word2vec.html