文字识别是AI的一项重要应用,例如将包装盒上的文字识别出来、将产品说明书上的文字识别出来、将大街上广告牌的文字识别出来等等,在现实生活中能给我们带来很大的便利,有着非常广泛的应用。
一个简单的文字识别流程如下:
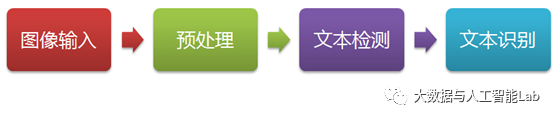
Step 1. 通过手机、摄像机等设备采集含有待识别字符的图像,作为输入;
Step 2. 对图像进行尺寸缩放、明暗调整、去噪等预处理操作;
Step 3. 将图像中的单个字符、或者是连续几个字符所在的区域检测出来;
Step 4. 根据文本检测结果从图像中将文本所在区域分割出来,然后导入到模型中进行文本识别,进而得到图像中的字符信息。
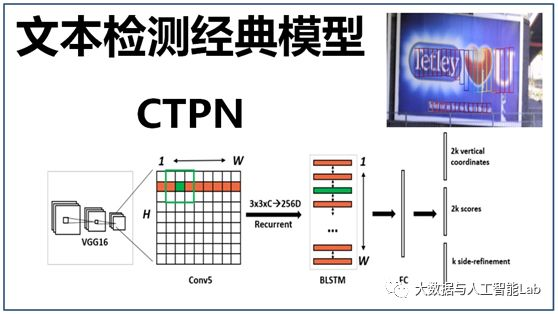
其中,这个流程有两个环节非常关键,一个是“文本检测”、另一个是“文本识别”,本文将介绍“文本检测”的经典模型CTPN,而“文本识别”模型将在后面另外介绍,敬请关注。
对于印刷字体的检测,由于排版很规范,现在的检测、识别技术已经很成熟了,我们日常使用的微信、QQ里面就有提取图片中文字的功能。而对于自然场景下的文字检测,由于光照环境以及文字存在着很多样的形式,要将文字检测出来则有比较大的难度,例如要检测出大街上广告牌中的文字,如下图:

本文主要介绍文本检测的经典模型:CTPN,它不仅可以用于检测自然场景下的文字,印刷文字的检测自然也不在话下。
1、文字分布的特点
在了解文字检测之前,先来看一下文字分布的特点。无论是印刷文字,还是自然场景下的文字,一般文字是水平排列,连续字符的长度可变,但高度基本相同,如下图:

这也是CTPN的基本思路,既然宽度是可变、不确定的,那么就按照固定的高度进行检测,看看图像中有哪些区域是连续出现了一片同样高度特征的区域,并且其边缘符合文字的特点?