论文链接:https://arxiv.org/abs/1811.10870
用于实例分割的亲和派生和图合并方法
一、简介
文章提出了一种基于像素亲和信息的实例分割机制,使用了两个相似的网络结构,一个网络用语预测像素级的语义得分,另一个网路用于得到像素之间的亲和性信息。将像素视作顶点,将像素间亲和性视作边的权重,并且文章提出了能将像素聚合到实例的一种简单且有效的图合并方法。
二、相关工作
2.1语义分割
FCN将CNN的全连接层替换成卷积层,实现了语义分割,沿着这条道路,很多网络针对FCN的缺点陆续被提出,为了保证空间分辨率的同时扩大感受野,提出了带孔卷积 [1],又称膨胀卷积。为了获得多规模信息,PSPNet[2]提出金字塔池化,Deeplabv2 [3] 提出 Atrous Spatial Pyramid Pooling (ASPP) 来获得环境信息。最近,DeepLabV3+ [4]引进了编译码结构 [5]并且获得了良好的性能,该篇文章不关注网络设计,任何用于语义分割的CNN都合适。
2.2实例分割
目前实例分割有两种基本方法,第一种是基于目标检测,在得到目标检测框之后再在框内做语义分割分割前景背景,由于这种方法需要借助目标检测中的区域提议,因此该方法称为proposal-based方法;另一种方法是,在语义分割图的基础上,将像素聚集到不同的实例上,将这种被称为proposal-free方法。
-
proposal-based
关于第一种方法,DeepMask[6]提出了一个网络,用来判断某一个图片补丁是否含有实例,进而产生mask;Multi-task Network Cascades (MNC) 提出了层叠结构,并且将实例分割任务分解成框定位、掩模生成和分类三个步骤;Fully Convolutional Instance-aware Semantic Segmentation (FCIS) [7]首先产生位置敏感特征图,然后通过将相邻区域的特征合并产生mask;Mask RCNN[8]对Faster RCNN[9]进行扩展,在其头部增加了一个mask分支。MaskLab[10]将Mask RCNN与位置敏感得分结合使用,获得了性能提升。基于区域的方法都是在ROI内进行mask的,因此,结果收到RPN[11](区域提议网络)的影响,并且会受到边框回归的准确性影响。
-
proposal-free
基于proposal-free的方法也在发展,这类方法的基本思想是利用CNN学到每个像素实例级的特征,接着用一种聚合方法将像素聚合成实例。这种方法通常分两步,一个是分割,一个是聚合。语义分割图获得之后,将像素一步步的聚合到不同的实例中。Liang[12]利用语义分割图预测图像中实例的个数和每个像素所属实例的位置,然后,执行光谱聚类以对像素进行分组;Long[13]将实例间的关系分类并且在聚合像素的时候利用边界信息;Alireza[14]和Bert [15]尝试学习内嵌向量来聚合实例;Sequential group network(SGN)[16]利用了一系列的简单网络一步步的将像素最终聚合成了实例,获得了该篇文章发布前最佳基于proposal-free方法类的实例分割性能。
该篇文章就是从proposal-free方法出发,基于进行语义分割的CNN网络,并对其进行改进以评估像素亲和性,进而判断两像素是否属于同一物体。
三、论文方法
3.1概观
文章的基本框架如图1所示。


文章将实例分割任务分成两步。第一步是利用CNN获得每个像素类别信息,并利用另一个网络生成像素亲和性信息这是一个易处理的二值分类问题,当然,为一张图中的所有像素生成亲和信息是不现实的,因此文章选取了部分临近像素。网络输出的每一层都代表了临近像素和当前目标像素属于同一实例的概率,如图2(a)所示。正如图1中看到的instance分支,像素亲和性信息能清晰的指示实例边界,进而证明了用它表征实例信息的可行性。第二步是将图合并算法用于这些结果,从而产生实例分割,对每个实例,它的类别是由基于语义标签的所有像素投票确定的。
3.2语义分支
文章使用了DeepLabv3[17]语义分割网络,其他语义分割网络也适用于文章的网络结构。
3.3实例分支
文章选择了很多像素对,实例分支的输出代表了他们是否属于同一个实例。理论上,如果一个实例是一个连通闭集,使用两对像素亲和性信息就可以合并实例。为了实现鲁棒性并且能够处理碎片化的实例,文章将以下像素集合作为目标像素p(x,y)的邻居像素。
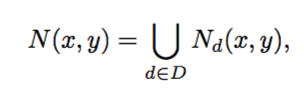
其中Nd(x,y)是与目标像素有着d距离的8个像素点,D是所有可选距离d的集合。在文章中D={1,2,4,8,16,32,64}
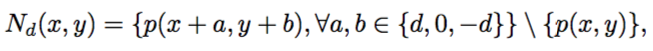
实例分支网络如图3所示。

其中文章去除了语义分割网络的最后一次softmax激活,并最小化了sigmoid激活后的交叉熵损失。集合N(x,y)中有8*7=56个元素,因此最后一层输出56层特征。在训练阶段,如果像素对属于同一个实例,相应的标签置为1,在推断阶段,输出特征的每一层代表邻近像素和目标像素属于同一实例的概率。图2(b)?中有关于被选择的邻居像素和训练阶段对应标签的简单示例。
3.4图合并
图合并的输入是语义分割特征图和像素亲和性信息,生成的是最终实例分割结果。
V是像素pair顶点集合,E是像素亲和性集合,于是就有图G=(V,G),值得注意的是实例分支的输出是对称的,即在(x, y)点处得到的Pair (p(x, y), p(xc, yc))和在 (xc,yc)点得到的(p(xc,yc),p(x,y)) 有着相同的物理意义:都意味着这个像素pair属于同一实例的概率。文章在使用亲和性初始话E之前,会将对应的对称像素对的概率平均化,因此G是无向图。让e(i,j)代表定点i,j之间的边,文章首先找到具有最大概率(亲和性)的边e(u,v),并且将u,v点合并成一个新的超像素定点uv,注意文章并不单独区分像素和超像素,uv只是代表由u、v两像素点合并而成的新像素点,合并u、v后就需要更新G,对于顶点集合V,u、v两点被除去,新的uv超像素被加入进来:
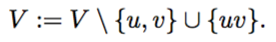
同样的边集合也需要更新:
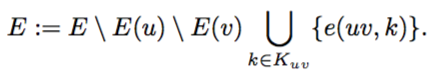
Ku:与u相连的所有像素点集,对于那些即与u点相连又与v点相连的像素点,e(uv,k)取e(u,k)和e(v,k)的均值,其它边则继承自原e(u,k)或e(v,k)。接下来寻找新的最大边,并且迭代上述过程,直到最大边的值小于阈值rw。算法1总结了上述过程。

图合并示例如图4所示。

最后会获得一个顶点集V,其中的每一个顶点(像素点或超像素点)代表一个实例,然后,将超像素点恢复成像素集,并且取包含像素数大于阈值rc的作为最终实例,假设像素点集X是一个保留实例,文章从最初的边集E中计算该实例的confidence,对于X中的所有点集对i,j,将他们对应的所有边值算数平均,这个值代表着X是实例的概率。
从直观经验上,文章也更希望将空间相邻的像素合并,因此,将D分成三个子集,Ds = {1,2,4}, Dm = {8,16},Dl = {32, 64} ,从小到大,依次在符合某一距离的像素点集上做图合并,每次图合并的概率阈值rw随着距离的增大而减小。
四、实施细节
4.1去除背景像素
因为他们在图合并的过程中不重要,去除他们能减小图像尺寸同时加快整个进程,文章将包括前景物体的感兴趣子区域称作ROI,与基于区域提议方法中的ROI不同,文章中的ROI可能包括很多实例。在具体实施中,超像素的尺寸是3232,意味着,如果任何像素在3232区域中属于前景像素,则全部的32*32区域都被认为是前景区域,接着使用一些像素将连通区域扩展并找到最紧致的包围框,这些被找到的包围框区域就是网络的输入。文章方法中的ROI数目通常小于10。
4.2细化像素亲和性
语义分割图除了能用来决定实例的类别,还能够对图合并算法有所助攻。比如,如果两个像素有不同的语义标签,则他们不属于同一实例,所以文章提出用语义分支的得分去细化图1中实例分支所输出的像素亲和性结果,针对某一像素对,具体实施中是将实例分支中得到的亲和性概率P(x,y,c)与语义特征图中二者的相似性相乘,去细化像素亲和性。P(x, y) = (p0(x, y), p1(x, y), · · · , pm(x, y)) 代表语义分支得到的特征图,包括背景共有m+1类,pi(x,y)代表该位置像素属于i语义类的概率,两个像素点对应的P(x,y)的内积则代表该两像素点属同一语义类别的概率,在计算时不考虑背景概率。细化像素亲和性的公式如下。
其中 ,它修改自sigmoid函数,将α设为5是为了减小语义分割内积对像素亲和性的影响。可见,当内积为0时,的概率为0,当内积为1时,得概率接近1。
,它修改自sigmoid函数,将α设为5是为了减小语义分割内积对像素亲和性的影响。可见,当内积为0时,的概率为0,当内积为1时,得概率接近1。
除了以上提到的信息,文章发现语义分割模型可能会在类与类之间产生混淆,因此,文章定义了混淆矩阵,它中某个元素cij代表着GT为i类却被错误分到j类的像素个数,通过混淆矩阵,文章发现语义分割模型有时会在大类内错误分类小类,但是极少跨越大类错误分类。为了进一步减弱语义阶段对实例分割造成的影响,文章将每一个大类对应的所有小类集合在一起称作一个超类。更多的,当两个像素数与不同的超类时,直接将两像素内积置为0,这有利于细化实例分割结果。
4.3改变ROI尺寸
就像是ROI pooling一样,文章将提议框的短边扩大到固定的尺寸并且成比例扩大另外一边,然后将扩大后的ROI作为输入。这有利于找到更多小的实例。
4.4强制区域合并
在进行图合并之前,强制性的将相邻的m*m个像素合并,在这个过程中,根据上文算法,重新计算像素亲和性。图5给出了简单例子。

强制合并临近像素不仅可以通过平均化将网络输出中的噪声滤除,还可以通过降低图合并算法的输入尺寸来节省处理时间。后文中有关于强制合并区域尺寸大小的确定的实验。
4.5语义类别分区
为了得到更好的ROIs,文章使用了4.2中的超类并且将它用于产生连通域,文章统计了每个像素属于某一超类的概率并且将像素分类到某超类上。为了寻找前超类前景区域,文章只将那些被分为该超类的像素看做前景,其他一律看做背景。详细的实验结果在后文中。
五、实验评估
文章在Cityscpaes数据集上进行了实验,使用AP作为评估结果的标准,IOU是0.5-0.95以0.05为步长。
因为大部分的数据集图像中的上和下部分都是背景,为了使数据更有效,文章随机抽取了训练集90%的图片,将它们图中上或下部中没有语义标签的部分丢弃。为了提升语义分割的性能,文章还使用了包含有卡车、火车和公交车的粗标注训练数据来训练语义分支,从粗标注数据中一共截取了1554个patches。为了从获得不同尺寸的物体角度入手扩张数据,文章还对精细标注的数据集进行了上采样以从中剪裁一些区域。网络在tensorflow平台上搭建,图合并代码是通过C++实现的。
5.1训练策略
语义分支使用了ImageNet[19]在ResNet-101上的预训练模型,实例分支也是用了ImageNet预训练模型。其他详细参数设置见原文。
5.2主要结果
文章方法显著提升了性能并且在Cityscapes测试集上实现了27.3%的AP,超越了Mask RCNN 1.1个百分点。如下表1。

从表1中可以看到文章方法在50%AP上比Mask RCNN低,文中解释是,文章方法可以获得更为精确的边界,因此在高IOU标准下能获得更高精度,而Mask RCNN可以找到更多精度相对小的实例mask,基于区域提议方法的实例分割找到的边界框可能导致粗糙的mask,当IOU较小时,该mask会被判定为正确。图6有很多文章方法结果实例。

正如图6看到的,文章在语义分割和实例分割两方面都取得了高质量结果,获得了精确的边界。如图6最后一行的结果,文章方法可以有效处理支离的实例,并且将他们合并到一起。
文章还将结果与MaskRCNN进行了对比,如图7所示。

可以看到文章方法得到的mask具有更高的细粒度。这与文章对于为何50%AP低于MaskRCNN的解释相通。
5.3详细结果
文章在验证集上进行了消融实验,并分析了细节。文章使用了4.1中介绍的baseline,这样做可以排除背景像素以有效加速图合并算法并且对最终结果的影响尽量小。在基线上获得了18.9%的AP,后文介绍了图合并算法的结果。
表2给出了图合并算法的实验结果。

关于像素亲和性,文章增加了语义信息去改进像素亲和性概率,获得了22.8%的AP。接着文章将ROI尺寸固定位513,AP显著提升了5.9%。考虑到窗口尺寸对结果也有影响,文章实验了2和4两种尺寸的窗口,发现使用大小为2的窗口不仅能减小图合并的复杂度,还能够提升精度,使用4则相反,因此,在接下来的试验中选用了2。如4.1提到,文章最后将语义类别分为了三个子类,分别为{person, rider}, {car, trunk, bus, train} and {motorcycle, bicycle},并分别寻找可能的区域,这种分离能够减小子类间的错误分类带来的影响,并使得ROI resize更有效。当然,使用大尺寸的图像可以提升性能,但是却会增加处理时间。
除此之外,输出图像的步长也会影响性能,小步长会使我们得到更详细的信息,但却会增加处理时间,并且会使得训练时的batch size变小。一开始文章试验了16输出步长,和8输出步长,表3给出结果。

可以看到使用8输出步长,会得到更好的语义分割和实例分割效果。
除此之外,文章还使用了水平翻转和语义类别提炼作为推测策略的可选项,水平翻转为语义推测带来了0.7%的AP提升,为实例推测带来了0.5%的提升。通过对val的观察,文章发现,在遇到碎片化实例的情况时,自行车和摩托车的两类碎片实例往往很难被连接。为了改善效果,在d=64时,文章对这两类实例的像素亲和性做了基于语义的像素亲和性细化操作,如上文4.2公式所示。表3中可以看到,使用了SCR后,文章方法达到了在验证集上最佳34.1%的精度。
5.4问题及改进
在文章中使用的最大距离d=64,也就是超过该距离的属于同一实例的两个部分就会合并失败,使用更大的距离增加通道数很难对性能有所提升。更多的,使用那些在语义分割上有更好性能的网络可能会对图合并有更多的帮助。一些失败的例子在图8中展示。可以看到文章提出的方法可能会错过一些小实例或者会将两个实例错误合并到一起。

六、文章贡献及结论:
(1)文章引进了一种全新的proposal-free实例分割机制,为了得到实例分割结果,即使用了语义信息,又使用了像素亲和性。
(2)文章证明了即使使用一个简单的图合并机制,也能实现很好效果,并超越基于区域提议的一些方法,这显著证明了proposal-free方法有着与及预期与提议方法相当甚至更好的性能。这也给实例分割研究的新层次带来了希望。
(3)证明了语义分割网络非常适合于像素亲和力预测,只是输出特征的含义改变了。
文章介绍了基于proposal-free的方法进行实例分割的机制,它是通过亲和派生和图合并进行的。文章使用了两个独立的具有相似结构的网络生成了语义分割结果和像素亲和性结果,将这两个结果作为输入,送到图合并进程,将像素聚合成实例。文章的方法只使用Cityscapes训练集就超过了Mask RCNN 1.1%AP,这表明了proposal-free方法可以获得最佳性能。语义分割性能随着新方法的使用可以进一步提升,应用到文章的方法中,可以进而提升实例分割效果。文章提出的图合并方法很简单,该机制的进步也会进一步提升性能,未来大有可期。
七、参考论文
[1] Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Se- mantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelli- gence 40(4), 834–848 (April 2018). https://doi.org/10.1109/TPAMI.2017.2699184
[2] Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J.: Pyramid scene parsing network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6230–6239 (July 2017). https://doi.org/10.1109/CVPR.2017.660
[3] Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Se- mantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelli- gence 40(4), 834–848 (April 2018). https://doi.org/10.1109/TPAMI.2017.2699184
[4] Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. arXiv preprint arXiv:1802.02611 (2018)
[5] Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose esti- mation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Visio
[6] Pinheiro, P.O., Collobert, R., Doll ?ar, P.: Learning to segment object candidates. In: Advances in Neural Information Processing Systems. pp. 1990–1998 (2015)
[7] Li, Y., Qi, H., Dai, J., Ji, X., Wei, Y.: Fully convolutional instance-aware semantic
segmentation. In: 2017 IEEE Conference on Computer Vision and Pattern Recogni-
tion (CVPR). pp. 4438–4446 (July 2017). https://doi.org/10.1109/CVPR.2017.472
[8] He, K., Gkioxari, G., Dollr, P., Girshick, R.: Mask r-cnn. In: 2017 IEEE In- ternational Conference on Computer Vision (ICCV). pp. 2980–2988 (Oct 2017). https://doi.org/10.1109/ICCV.2017.322
[9] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time ob- ject detection with region proposal networks. IEEE Transactions on Pat- tern Analysis and Machine Intelligence 39(6), 1137–1149 (June 2017). https://doi.org/10.1109/TPAMI.2016.2577031
[10] Chen, L.C., Hermans, A., Papandreou, G., Schroff, F., Wang, P., Adam, H.: Masklab: Instance segmentation by refining object detection with semantic and direction features. arXiv preprint arXiv:1712.04837 (2017)
[11] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time ob- ject detection with region proposal networks. IEEE Transactions on Pat- tern Analysis and Machine Intelligence 39(6), 1137–1149 (June 2017). https://doi.org/10.1109/TPAMI.2016.2577031
[12] Liang, X., Wei, Y., Shen, X., Yang, J., Lin, L., Yan, S.: Proposal-free network for
instance-level object segmentation. arXiv preprint arXiv:1509.02636 (2015)
[13] Jin, L., Chen, Z., Tu, Z.: Object detection free instance segmentation with labeling transformations. arXiv preprint arXiv:1611.08991 (2016)
[14] Fathi, A., Wojna, Z., Rathod, V., Wang, P., Song, H.O., Guadarrama, S., Murphy, K.P.: Semantic instance segmentation via deep metric learning. arXiv preprint arXiv:1703.10277 (2017)
[15] Brabandere, B.D., Neven, D., Gool, L.V.: Semantic instance segmentation for autonomous driving. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 478–480 (July 2017). https://doi.org/10.1109/CVPRW.2017.66
[16] Liu, S., Jia, J., Fidler, S., Urtasun, R.: Sgn: Sequential grouping networks for in- stance segmentation. In: 2017 IEEE International Conference on Computer Vision (ICCV). pp. 3516–3524 (Oct 2017). https://doi.org/10.1109/ICCV.2017.378
[17] Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017)
[18] Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benen- son, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for se- mantic urban scene understanding. In: 2016 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 3213–3223 (June 2016). https://doi.org/10.1109/CVPR.2016.350
[19] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge. International Journal of Computer Vision115(3), 211–252 (Dec 2015). https://doi.org/10.1007/s11263-015-0816-y,https://doi.org/10.1007/s11263-015-0816-y