��������:https://arxiv.org/abs/1801.00908
���ļ��
���������һ��ͨ�������װ�ڻ���ͼ���ʵ��Ƕ�������е�֪ʶ�������ල��Ƶ����ָ�ķ�����ʵ��Ƕ������Ϊÿ����������Ƕ���������Ա�ʶ������ͬһ������������ء���Ȼ�ھ�̬ͼ���Ͻ�����ѵ������ʵ��Ƕ������������Ƶ֡�����ȶ��ģ���ʹ���ǿ�����ʱ�佫����������һ����ˣ����ǽ��ھ�̬ͼ����ѵ����ʵ��������Ӧ��Ƶ����ָ�����������ѧ�����������ϣ�������ģ����ѵ������������
��״�Ͳ���
��Ƶ�����һ����Ҫ������ʱ��Ϳռ��еĶ���λ����������£���Ӧ���ܹ�ʹ�ü���Ķ���mask��λ��ʱ�����Ƶ���Ϥ����ӱ�Ķ����ⱻ��Ϊ��Ƶ����ָVOS�������û�и���Ҫ�ָ�Ķ����ָʾ����������Ϊ�ල��Ƶ����ָ����Ҫ����ָ
��̬ͼ���е���ض���ָ�����Ŀǰ�ɻ���FCN�ķ�������[1]����Щ��������Ҫ����ͼ������ע�ĵĴ������ݼ�����PASCAL [2]��COCO [3]�� ��Ƶ�ָ����ݼ���С����Ϊ���Ǹ����Ա�ע[4]�� ��ˣ���ȷ��ѵ��������������Ƶ�ָ������˵�������ѡ�
���ķ���
�������У������һ�ַ�����ת���ھ�̬ͼ����ѧϰ��ʵ���ָ�Ƕ���з�װ��֪ʶ�������������÷ֺ������ϣ��Զ���Ƶ�е��˶�������зָ������Ϊ������ͼ��ת�Ƶ���Ƶ���ʱ��ʵ��Ƕ���������ʹ��ǰ��/��������Ԥ�ⷽ���ĸ����õ���������ͼ����ʵ��ʾ����

�����Ƕ�����Ƶ�е�ǰ����Ҳ�ǵײ���Ƶ�еı�����Ϊ�˽��������⣬���ǵķ�������˶���ʵ����Ƕ�룬��ʶ����ǰ��/�����Ĵ���Ƕ�룬Ȼ����ݴ���Ƕ���֡���зֶΡ� �����ࡣ �м䣺ͨ��PCAͶӰ��RGB�ռ��Ƕ��Ŀ��ӻ����Լ�ǰ����Ʒ��ɫ���ͱ�������ɫ���Ĵ����㡣 �ң���������ķ��������ķָ���ģ�����ͨ����һ�������ǰ����Ƕ�����ҵ�����ھ������������ؽ��з��ࡣ����һ���Dz��������̣�����Ҫ��Ƶ�ض���ѵ������Լල��
������
��1��һ���µ����ڵ����ھ�̬ͼ����ѵ����ʵ���ָ�ģ���õ���Ƶ��ȥ�IJ��ԡ�
��2���ò�����DAVIS����FBMS�������о�������ǰ�����ķǼල�����������ڲ���ʱ������ѵ���κ����缴�ɽӽ����CN������
��3�������û�мල�����ǰ����ѡ��ǰ�����±������������������ϵ��˶�������
��4�������˽�ʵ���ֶ�Ƕ����ʱ�����Ƶ��ȶ��ԡ�
�����ල�����ĺô�
��1�����ܴ��ڹ�ע�������ķ��գ��������ڸ���ط������ල��������Ϊ���Dz���Ҫ�û�������ָ��Ҫ�ֶεĶ����������ǶԲ���Ҫ�û������ķ�������Ȥ���������ѡ��רע���ල�ָ
��2����ල�ָ�����������Ҫ���뵽�����ӣ���������ͨ���ᵼ�¸��õķָ��������ʱ��ɱ���һ����ʹ���ǹ�ע�ල������
����ϸ��
��ͼ����������������ĸ�����

�������Ȼ�ý����������ʵ��Ƕ�룬�����������������ʵ��Ƕ�룬����ʶ���Ƿָ�����ġ����ӡ��㣬���������������빹�����ӹ������������ǰ�����������˶������Զ����ӹ��������������ÿ��֡��ѡ��ǰ���������ӣ� ���ǽ�һ��������һ��ǰ��/�����������ӣ�����ÿ��֡���������յķָ����롣
���������ϸϸ�ڣ�
��1����ȡ����
���ǵķ���ʹ���������룺ʵ��Ƕ�룬���������������Щ���ܶ���������Ƶ����ָ����ݼ��Ͻ�������ÿ��֡��Ӧ������������ȡϸ�����£�
ʵ��Ƕ��Ͷ���÷֣�
����ѵ��������ͼ��ʵ���ָ����������ʵ��Ƕ������������[5]�������� �����֮��ʵ��Ƕ��������һ���ܼ�����ľ��������磬�����������ͷ��ʵ���ָ����ݼ��ľ�̬ͼ���Ͻ���ѵ����
��һ��ͷ���ÿ�����ص�Ƕ�룬����������ͬ����ʵ��������������֮����б����ڵ�����������ظ�С��ŷʽ���룻�ڶ���ͷ�����������ָ�Ķ�������� ������С������ָ�log loss����ѵ���ڶ���ͷ���ÿ�����ص����������ʡ�
Ƕ��ͼ��
���Ǵ��ܼ�Ƕ��ӳ�乹��һ��4����ͼ������ÿ��Ƕ����������һ�����㣬�����ڿռ�����Ƕ��֮����ڱߣ���Ȩ�ص���Ƕ������֮���ŷ����¾��롣 ��Ƕ��ͼ�������Ժ�����ͼ�������ӻ�Ƕ��ͼ����ͼ��ʾ��

������
�˶����������������ڹ����ϡ� Ϊ���Ը߾��Ƚ��п��ٹ������ƣ���������FlowNet 2.0 [6]������ʵ�֣������ڵ��������硣
��2��������������
������Ƶ�е�֡K��һЩ�Ӽ���ͨ����ȫ������������֡k������������������ӵ�Sk�� �����������뵱ǰ֡�ڵ����ӽ��бȽϣ����Ϊ������ʡ�����ϱ�k�����Ǽ����Խ���֡��������ΪFG��BG��������Ƕ��ռ���Ӧ���Ƕ����ģ���Ϊ�ָ�Ŀ��������������������ƶ�������һ�鲻ͬ�������У�����һ������Ӧ������FG��������һ��BG���ӣ���ΪǶ��ռ��еľ�������Եġ�
��������߽��ϵ�Ƕ��ͨ�����ӽ���һ�����Ƕ�롣 ��Ϊ������ҪǶ�����Ĵ��������ǴӶ���߽����ų����ӡ�Ϊ�˱������߽磬���ǽ���ʵ��Ƕ���ڱ���һ�µĺ�ѡ����ѡ�����ӡ����Dz���KMeans ++��ʼ��[7]�еij���������Щ��ѡ���ӵIJ�ͬ�Ӽ���Ϊ���������ӡ������������Ƚ�����������÷ֵĺ�ѡ�����ӵ����Ӽ��У�ͨ���������Ӻ�ѡ�����������������������ǰѡ������Ӿ�����С����������ԣ�����ѡ�ﵽĿ��������ʱֹͣ��
��3���������������
���ල����Ƶ����ָ������У�����û����ȷָ����Ŀ�������ˣ�������Ҫ���ƶ�����ʶ��Ϊ�ָ�Ŀ�꣨��FG�����������ȸ��ݶ����Ժ��˶������Զ����ӽ������֡�Ϊ���ҵ�����ϣ����FG���ӣ�����Ȼ��ͨ����Ƕ��һ���������������ӹ������Խ֡�����ӹ�������Ź���ľۺϷ�������������˶��������Լ����ӹ�������������
�˶������ԣ�
�����IJ�����Է����ڱ������ƶ�������[8]�����ڹ���������Ȼ�����ƣ�����ͼ��������ƽ������������ʹ�����Ե������ص�����������ÿ������s������ʹ����Ӧ�����е�ƽ��������Ϊ�Աȡ�ͼ�������ʾ������ͼ������

���ӹ����
ǰ���������һ����������Ӧ���Ƕ������е����Ŷ�������ͨ�������Ƶ�����������һ�����÷֣��������ӹ����ȡ�������ƽ������-ÿ�������ĵ÷ֺ��˶������Ե÷֡�
��4���ָ�ǰ������
�ָ�ǰ���������������裺��ʼ��ǰ���ָ����ǰ�����ӣ����ӱ������ӣ�����ϸ�ֺ����߸ıࡣ
��ʼǰ���ָ
��ÿ��֡��ѡ��������ǰ�����������ӹ�����ṩ��ʼǰ�����ӡ�����ͨ��ʶ��Ƕ��ͼ�п���ǰ�����ӵ���������ó�ʼǰ���ָ�����ٴν������������÷ֵ�������Ϊ��ʼ�������Ӽ���Ȼ��ʼǰ�������ɱ��κα������Ӹ��ӽ�ǰ�����ӵ�������ɡ�
����ǰ�����ӣ�
ͨ����ѡ��ǰ�����ӹ��ڱ��أ���ʼ�ָ�ܸ����������塣Ϊ����չǰ���ָ���Ǵ�����һ��ǰ�����ӡ�
���ӱ������ӣ�
���������������͵��������еͶ���÷ֵķǶ�������������գ���·��ˮ�ȣ��;�̬����̬������Ƕ��ռ��У�ͨ���ȷǶ������ӽ�ǰ��������̬����������ǰ��������ͬ���������ʱ�����Ӿ�����ս�ԡ���������ͨ��������÷�С����ֵ���������˶������Ե÷�С����ֵ��������������������չ�Ա�������ı�ʾ��
����ϸ�֣�
һ��������ǰ���ͱ������ϣ���Ϊÿ�����ؼ����������ǰ���ͱ������ӵ����ƶȡ�����ʹ��һ֡�е�ǰ���ͱ��������ָ���һ֡�Խ���ǰ��/�������ƶȼ��㡣����ܼ���CRF [9]����ϸ���ָ���ģ��
���߸ıࣺ
���߸ı�ֻ������һ���µ�ǰ���ͱ������ӡ������FCN�Խ�����ӦҪ���õö࣬��Ȼ����ǰ���ͱ��������ܻᵼ���ڲ�ͬ��֡�зָͬ�Ķ�����ͨ������ƽ����
ʵ�����
������DAVIS���ݼ�[10]��Freiburg-Berkeley�˶��ָFBMS�����ݼ�[11]��SegTrack-v2���ݼ�[12]��������������ķ���������ʹ����PASCAL VOC 2012���ݼ���ѵ����ͼ��ʵ���ָ���������ȡ����Ƕ��Ͷ���ʵ���ֶ��������DeepLab-v2��ResNet��Ϊ���ɣ���ʹ��������FlowNet2.0����ʵ�ֵ��ȶ������������Ƚ��ļ�����ȣ���DAVIS���ݼ��ϵ�Ч�����±���ʾ��
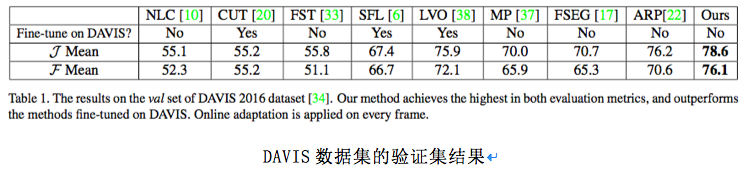
���ϱ���ʾ�����ǻ�����ල��Ƶ����ָ��������ܡ����ǵ��ල������������һЩ���Է��ʵ�һ֡ע�͵İ�ල������VPN [13]��SegFlow [14]����2����һЩ���Էָ�������ͼ��ʾ��

���µķ����ھ��д����۱仯�����У����������ı������ڶ��У������е��ˣ��ı��ӽǣ������У�����Ƶ�ϱ������á�
����
�������У����������һ�ַ��������Ӿ�̬ͼ����ѧϰ��ʵ��Ƕ��ת��Ϊ��Ƶ�в���Լ���Ķ���ָΪ����Ӧ��Ƶ����ָ������в��ϱ仯��ǰ��������ѵ���������ɷ�װʵ����Ϣ��Ƕ�룬������ѵ��ֱ�����ǰ��/�������������硣 ��ʵ��Ƕ���У����ǴӶ����Ժ��˶���������ʶ��������Ե�ǰ��/����Ƕ�롣 Ȼ������ǰ��/������Ƕ�������Զ����ؽ��з��ࡣ ��֮ǰ��Ҫ��Ŀ�����ݼ����������������ͬ�����ǵķ������ල����Ƶ����ָ�������ʵ�������Ƚ������ܣ������κ�����
�����
[1] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully con- nected crfs. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2016.
[2] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The PASCAL visual object classes (VOC) challenge. International Journal of Computer Vision (IJCV), 88(2):303�C338, 2010.
[3] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra- manan, P. Dolla ?r, and C. L. Zitnick. Microsoft COCO: Com- mon objects in context. In European conference on computer vision, pages 740�C755. Springer, 2014.
[4] F. Li, T. Kim, A. Humayun, D. Tsai, and J. M. Rehg. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Com- puter Vision, pages 2192�C2199, 2013.
[5] A. Fathi, Z. Wojna, V. Rathod, P. Wang, H. O. Song,
S. Guadarrama, and K. P. Murphy. Semantic instance segmentation via deep metric learning. arXiv preprint arXiv:1703.10277, 2017.
[6] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), volume 2, 2017.
[7] D. Arthur and S. Vassilvitskii. k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pages 1027�C 1035. Society for Industrial and Applied Mathematics, 2007.
[8] T. Brox and J. Malik. Object segmentation by long term analysis of point trajectories. Computer Vision�CECCV 2010, pages 282�C295, 2010.
[9] P. Kra ?henbu ?hl and V. Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. In Advances in neural information processing systems, pages 109�C117, 2011.
[10] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[11] P. Ochs, J. Malik, and T. Brox. Segmentation of moving objects by long term video analysis. IEEE transactions on pattern analysis and machine intelligence, 36(6):1187�C1200, 2014.
[12] F. Li, T. Kim, A. Humayun, D. Tsai, and J. M. Rehg. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Com- puter Vision, pages 2192�C2199, 2013.
[13] V. Jampani, R. Gadde, and P. V. Gehler. Video propagation networks. In IEEE Conference on Computer Vision and Pat- tern Recognition, volume 2, 2017.
[14] J. Cheng, Y.-H. Tsai, S. Wang, and M.-H. Yang. Segflow: Joint learning for video object segmentation and optical flow. In The IEEE International Conference on Computer Vision (ICCV), 2017.