论文链接:https://arxiv.org/abs/1612.03129
简介
文章方法基于物体掩模的距离变换。
文章设计了一个具有残差反卷积结构的物体掩模网络(OMN),提取特征并将其解码成最终的二值物体掩模。优点:这种方法能摆脱传统区域提议中提议框的范围局限,并且对于不够准确的区域提议具有鲁棒性。
文章将OMN整合到多任务网络级联框架中,称之为边界感知实例分割网络(BAIS),并实行端到端地学习。
文章方法在Cityscapes和PASCAL VOC2012数据集上的实例分割性能都超过了当时的最佳方法。
一、相关工作
实例分割能够提供图像中实例的数量、位置、类别、形状信息,在自动驾驶,个人机器人,植物分析等领域有广泛应用。常用实例分割方法:
(1)基于区域提议的方法
[1]中使用了Fast-RCNN的提议框[2]并建立了multi-stage管道用于抽取特征、分类和分割物体。通过开发Hypercolumn功能[3]以及使用全卷积网络(FCN)来编码特定类别的形状先验[4],改进了这一框架。在[5]中,[6]的区域提议网络(RPN)被集成到多任务网络级联(MNC)中执行语义分割。
缺点:这些方法都受到以下事实的影响:它们仅预测提议边界框内的二值掩模,这样通常是不准确的。
(2)避开区域提议的方法
PFN[7]通过预测实例数目,对每个像素预测类别标签和其包围框位置。
缺点:效果强依赖于预测的实例数目。
[8]提出根据深度排序识别实例,[9]使用一个深度密集连接的马尔科夫随机场对其进行扩展。
缺点:目前还不清楚这种方法如何处理多个实例处于大致相同深度的情况。
为了克服上述缺点,[10]使用FCN同时预测深度、语义和实例方向编码,然后将其通过模式匹配过程产生实例。
缺点:这个过程包含许多独立模块,无法一同进行优化, 所以产生的结果往往非最佳。
最后,在[11]中,提出了一种递归神经网络来逐个分割图像。然而,这种方法基本上假设图像中观察到的所有实例属于同一类。
(3)类不可知的区域提议方法
[12]中提出的方法,使用FCN计算组合成实例分割提议的一小部分实例感知得分图,该方法被加入到MNC中后能有效提升实例分割效果。
二、文章方法
文章提出了对边界框提议中的错误具有鲁棒性的实例分割的方法,为此,文章提出使用密集多值图编码建模物体形状。通过反向距离转换,将多值图转换成二值掩模,得到实例分割结果[13][14]。示例如图1所示。

由图1看出,文章方法实现的实例掩模可以超越边界框的局限。
文章设计了物体掩模网络(OMN),对每个提议区域,首先预测对应像素级多值图,并将其解码成最终的二值掩模,其中一些二值掩模会超过包围框的限制。将截短距离离散化,并用二值向量进行编码。这将预测多值图转换成了像素级标注让任务。网络的第一个模块生成多概率图,每个都表示该向量中一个特定位的激活。然后将概率图传入一个新的残差反卷积网络模块产生最终的二值掩模。由于这个反卷积模块,输出的分割实例不会严格局限在提议框内,从而使OMN大为不同。
为了解决实例分割,文章将OMN整合到多任务级联结构[5]中,用OMN替换原先的二值掩模预测模块。将文章提出的模型称为边界感知实例分割(BAIS)网络。
三、边界感知分割预测
文章目的是设计一个对提议框的错误偏移具有鲁棒性的实例分割方法。为此,首先设计了一个能够捕捉物体形状或者获取物体边界的物体掩模表示,这种方法的优势是:基于距离转换,即便只有部分信息也可以预测出实例的完整形状。然后设计了一个深度网络,输入图片,输出普适性的实例掩模,其可以超过最初提议框的范围。以端到端的方式学习。
3.1边界感知掩模表示
给到部分区域提议,目的获取整个物体掩模。文章提出根据距离变换构造一个像素级的多值映射图,它编码了整个对象的边界[13]。换句话说,对多值图中的每个像素值,若像素是实例内部的,则其值代表其与该实例边界的最近距离,如像素是实例外部的,则其对应信息为背景。
随着窗尺寸的变化和实例形状的变化,距离变换产生的值具有很大的变化区间,这将导致形状表示不稳定,并且会复杂化OMN训练过程。因此对窗尺寸进行归一化并且将距离转换值截短到一个限定范围内。特别的, Q 代表在实例边界和实例以外的像素。对归一化窗口中的每个像素p,计算对于Q的截短距离D§。公式如下:
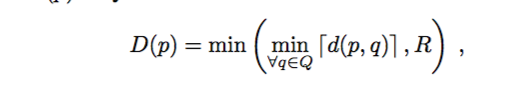
d(p,q)是d和p的欧氏距离, ?x?返回最近x的上整数, R是截短阈值,即想表达的最大距离。接下来使用D作为密集对象表示。图2左示意上述密集图。

可见这比二值掩模(指定是否是感兴趣实例)具有更多信息和优势。
距离截短表示法优势:
首先,每个像素处的值包含了物体边界位置信息,所以这对由提议框的错误引起的空间阻塞具有鲁棒性。其次,由于对每个像素编码距离值,这种表示是冗余的,因此可以一定程度避免像素图中的噪声影响。最后,对这种表示的预测可看做一个像素级的标签任务,使用深度网络可有效执行。
为了进一步促进这种标记任务,文章将像素方向图中的值量化为K个均匀区间。换句话说,将像素p的截短距离编码成k维的二值向量b(p):
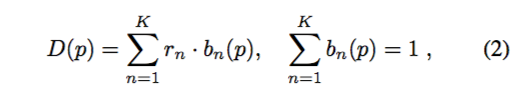
rn 是与第n个区间相对应的距离值.通过这种one-hot编码,便将多值像素图转化成一系列的k二进制像素图。这使文章能够将预测密集图的问题转化为一组像素级二进制分类任务,这些任务通常能由深度网络成功执行。
有了上述k二进制像素图,便可以通过反转距离变换大致恢复出实例掩模。特别的,用一个半径为D§的二值圆盘连接每个像素,建立物体掩模。然后通过获取所有圆盘的并集来计算对象掩码M. T (p, r)表示像素p位置处的以r为半径的圆盘。物体掩模可以如下表示:
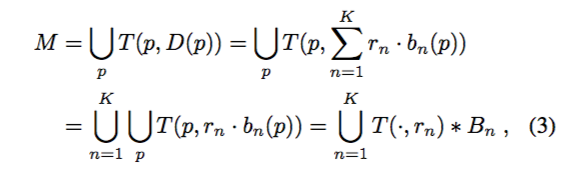
其中*表示卷积运算符,Bn是第n个bin的二进制像素值映射。
图1中最右边一行阐述了文章表示的行为,在顶部图像中,每个像素的值表示到边界框内实例边界的截断距离。虽然它没有覆盖整个对象,但是将这个密集的地图转换为二进制掩码,会产生底部显示的完整实例掩码。
3.2物体掩模网络
文章为了边界感知表示来为输入图像中的每个对象实例生成掩码,设计了一个深度神经网络,为一组边界框提议中的每个框预测K边界感知的密集二元图,并通过公式3将它们解码为完整的对象掩模。使用RPN产生最初的提议区域,对每一个提议区域使用ROI变形并将结果传递给文章网络。这个网络包括下述两个部分。
模块1:输入形变ROI,输出编码有截短距离的K二值掩模。特别的,对第n个掩模,使用具有sigmoid激活函数的全连接层预测像素级的概率图,这个概率图接近Bn。
模块2:残差反卷积网络,输入k概率图,输出二值实例掩模,使用残差反卷积网络的理论基础是,公式3可以看做一系列具有固定权重不同核尺寸和padding尺寸的反卷积操作。如图2右侧图示。然后,文章用一系列加权求和层和一个sigmoid激活函数逼近联合算子。加权求和层中的权重是在训练期间学习的。为了适应不同尺寸的反卷积滤波器,每次加权求和之前,对网络中较小的rn值对应的反卷积输出进行上采样。为此,文章使用固定的步幅值K。OMN网络的输出可以直接与GT对比,具有高分辨率,使用交叉熵loss。
四、学习实例分割
OMN输出二值实例掩模,接下来需要进行语义分类,得到最后的实例分割图。因此建立了边界感知实例分割(BAIS)网络。即将OMN整合到多任务网络级联(MNC)结构中。BAIS网络可以用端到端的方式进行训练。
4.1 BAIS网络
BAIS网络结构与MNC结构类似,BAIS包括三部分子网,对应着执行生成边界框提议、实例掩模预测和实例分类。第一个模块包括一个深度CNN(实践中使用VGG16结构[15]),从输入图像中提取特征,然后输入RPN[16]获取提议区域;经过ROI变换之后,送入OMN网络,生成分割掩模,最后如初始MNC网络一样,通过使用特征掩模层中的预测掩模并将其与提议区域特征串联,计算得出掩模特征;产生的特征送入第三个子网络,该网络包括一个用于分类的全连接层和边界框回归。图3展示了文章提出的BAIS网络结构。

多阶段边界感知分割网络
依据[5]中提出的方法,文章扩展了BAIS网络,想法是根据OMN的输出细化初始的边界框提议,从而优化预测的部分。如图3右所示,前三个阶段由上述模型组成,即VGG16卷积层,RPN,OMN,分类模块和边界框预测。然后,利用第三阶段的边界框回归部分生成的预测偏移来修正初始框。这些新框通过RoI变换作为输入,作为第四阶段,对应于第二个OMN。然后在最后阶段将其输出与细化的提议框一起用于分类。在该5级级联中,共享两个OMN和两个分类模块的权重。
4.2网络学习和推测
文章BAIS网络不同于其他的多任务级联网络,可以使用端到端方式训练,因此,使用多任务损失去计算提议框、实例掩模和类别的错误。具体的,使用softmax loss计算RPN和分类的错误,使用二值交叉熵损失计算OMN的错误。在五级级联结构中,在第三和第五级之后计算边界框和掩模损失。在测试时,首先对输入图片经过卷积层生成特征图,RPN模块进一步生成300个区域提议,并使用OMN预测对应的物体掩模,根据类得分分类掩模,再通过一个以0.5为IOU阈值的明确类的非极大值抑制进行筛选。最终,对每一个类独立使用[5]中的in-mask投票机制来进一步细化实例分割。
五、实验结果
实验证明了文章方法在实例分割和分割提议生成上的有效性。
5.1实例分割
Results on VOC 2012
与基线模型的对比如下表1:

由上表倒数第二行可见,将mask的范围扩展到提议框范围之外能够提高性能。
同样,文章还试验了MNC结构的stage数目对性能的影响。

注意到文章方法即使用3stages也能超越MNC的性能。
Results on Cityscapes



图4给出在Cityscapes上的示例:

下图5给出了一些失败案例,可以看到主要由于实例的遮挡支离造成。

5.2分割提议生成
此部分验证了OMN在生成实例mask方面的高性能。对于文章mask延伸到边界框之外,来自RPN的分数(与框相对应)不合适。 因此,文章学习了一个评分函数来重新排列提议。为了比较公平,文章还学习了一个类似的适用于MNC提议的评分函数。将此基线称为MNC +score。


不足:在表6可以看到在生成1000个区域提议时,文章的方法性能不如Sharp-Mask,但是实际应用中,一张图中很少需要如此多的提议区域,而文章在10或100个提议区域时性能优良。
在图6中可以看到,文章即使在1000个提议区域时,针对高的IOU阈值,仍然表现最佳。
六、结论
在文章中引入了一种基于距离变换的掩模表示,它能预测超出初始边界框限制的实例分割。然后,文章展示了如何使用完全可微分的对象掩码网络(OMN)来推断和解码这种表示,该对象掩码网络依赖于残差-反卷积体系结构。然后使用此OMN开发边界感知实例分割(BAIS)网络。 对Pascal VOC 2012和Cityscapes的研究表明,文章的BAIS网络优于最先进的实例级语义分割方法。在未来,文章打算用更深层次的体系结构(如残差网络)取代使用的VGG16网络,以进一步提高框架的准确性。
七、参考论文
[1]B. Hariharan, P. Arbela ?ez, R. Girshick, and J. Malik. Simul- taneous detection and segmentation. In ECCV, 2014. 1, 2, 5, 6, 7
[2]R. Girshick. Fast r-cnn. In ICCV, 2015. 2, 5
[3]B.Hariharan,P.Arbela ?ez,R.Girshick,andJ.Malik.Hyper- columns for object segmentation and fine-grained localiza- tion. In CVPR, 2015. 2, 5, 6
[4]K. Li, B. Hariharan, and J. Malik. Iterative instance segmen- tation. In CVPR, 2016. 1, 2
[5]J. Dai, K. He, and J. Sun. Instance-aware semantic segmen- tation via multi-task network cascades. In CVPR, 2016. 1, 2, 3, 4, 5, 6, 7
[6]S.Ren,K.He,R.Girshick,andJ.Sun.Fasterr-cnn:Towards real-time object detection with region proposal networks. In NIPS, 2015. 2, 4, 5
[7]X. Liang, Y. Wei, X. Shen, J. Yang, L. Lin, and S. Yan. Proposal-free network for instance-level object segmenta- tion. CoRR, abs/1509.02636, 2015. 2, 6
[8]Z.Zhang,A.Schwing,S.Fidler,andR.Urtasun.Monocular object instance segmentation and depth ordering with cnns. In ICCV, 2015. 2
[9]Z.Zhang,S.Fidler,andR.Urtasun.Instance-LevelSegmen- tation with Deep Densely Connected MRFs. In CVPR, 2016. 1, 2
[10]J. Uhrig, M. Cordts, U. Franke, and T. Brox. Pixel-level encoding and depth layering for instance-level semantic la- beling. In GCPR, 2016. 2, 6
[11]B. Romera-Paredes and P. H. S. Torr. Recurrent instance segmentation. In ECCV, 2016. 2
[12]J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive fully convolutional networks. In ECCV, 2016. 1, 2, 5, 6, 7
[13]G. Borgefors. Distance transformations in digital images. Computer vision, graphics and image processing, 1986. 1, 3
[14]B. Hariharan, P. Arbela ?ez, R. Girshick, and J. Malik. Simul- taneous detection and segmentation. In ECCV, 2014. 1, 2, 5, 6, 7
[15]K. Simonyan and A. Zisserman. Very deep convolu- tional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 4
[16]S.Ren,K.He,R.Girshick,andJ.Sun.Fasterr-cnn:Towards real-time object detection with region proposal networks. In NIPS, 2015. 2, 4, 5