这几天看了Stacked Attention Networks for Image Question Answering这篇论文,对文中所提出的模型有了大概了解。本文提到了“SAN”网络,他是在attention基础上发展而来的。这里我先介绍一下注意力机制的使用,再针对这篇论文的stacked attention进行分析,由易到难,效果会更好。
注意力机制
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。Attention,顾名思义,是由人类观察环境的习惯规律总结而来的,人类在观察环境时,大脑往往只关注某几个特别重要的局部,获取需要的信息,构建出关于环境的某种描述,而Attention Mechanism正是如此,去学习不同局部的重要性,再结合起来。
Encoder-Decoder框架
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。目前大多数注意力模型附着在Encoder-Decoder框架下。当然,注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。图1是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
图1 抽象的文本处理领域的Encoder-Decoder框架
我们可以把输入和输出看作<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
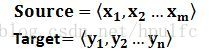
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:Encoder对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C,对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息
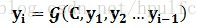
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,图1所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
添加注意力的Encoder-Decoder框架
图1中展示的Encoder-Decoder框架是没有体现出“注意力模型”的,为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
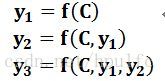
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子Source的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这就是为何说这个模型没有体现出注意力的原因。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。这里举个例子,英译汉任务:
"Tom chase Jerry."
显然答案是:
“汤姆追逐杰瑞”
我们要解决的是这样一个问题:(Tom, chase, jerry)→ (汤姆,追逐, 杰瑞),按照Encoder-Decoder的原始做法,我们为三个中文单词分别计算C:

比如在翻译“杰瑞”这个中文单词的时候,该模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是该模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如图2所示。
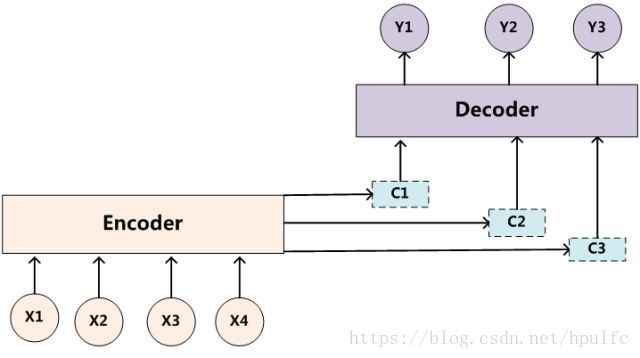
图3 引入注意力模型的Encoder-Decoder框架
即生成目标句子单词的过程变成了下面的形式:
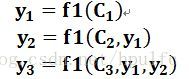
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
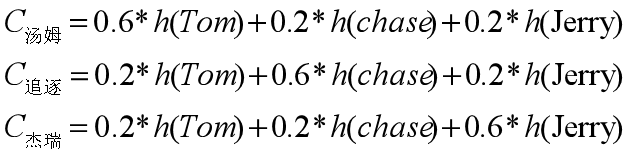
即中间语义表达C有如下公式:
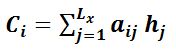
其中,Lx代表输入句子Source的长度,aij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而hj则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,经过加权求和得到语义表达C。
但是这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
为了便于说明,我们假设对图2的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图2的框架转换为图4。

假设当前Decoder要输出的是Yt,已知Decoder上一时刻的隐层输出St-1,用它与Encoder的各时刻隐层输出hj做某种fatt操作,计算出来的结果用softmax转化为概率,就是我们所需的权重a,对输入加权求和,计算出输入序列表达C,作为Decoder当前的部分输入,从而生成Yt。这就是Attention的工作机制。
可以说attention的核心就是C的计算,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性。
,即使跳出Encoder-Decoder这个框架,Attention也可以单独存在,因为他的本质就是“加权求和”。
还可以从另一个角度看Attention,那就是键值查询。键值查询应该有三个基本元素:索引(Query),键(Key)和值(Value),可以理解为这是一个查字典的过程,Key-Value对构成一个字典,用户给一个Query,系统找到与之相同的Key,返回对应的Value。那么问题来了,字典里没有与Query相同的Key怎么办?答案是分别计算Query和每一个已有的Key的相似度w,作为权重分配到所有的Value上,并返回它们的加权求和。Attention也可以理解为某种相似性度量。
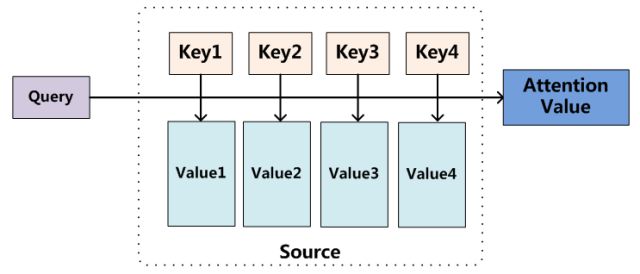
所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
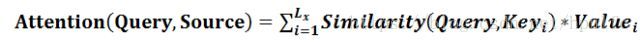
Attention也可以理解为某种相似性度量。 其中,Lx=||Source||代表Source的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码。
其中,计算Query和某个Key的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:
讲到这里,我们已经知道了什么是注意力机制,为什么要使用注意力机制,接下来我们来说一下注意力机制在视觉问答中的应用。
Stacked-Attention-Networks
首先来看一下SAN的大致结构:

可以看出SAN其实主要分为3个部分:LSTM/CNN(用来提取输入的问题特征)、CNN(提取图像特征)、Attention(注意力层)。其中CNN部分其实不是集成在SAN网络中的,原文的实现方式其实是用已经预训练好了的VGG16来提取图片feature,然后直接调用这些feature,而不会去更新VGG16网络的权重。所以最终实际程序需要实现的部分其实就是LSTM/CNN部分和Attention部分。
图像模型
首先image应当在输入VGG16网络前被rescale成448x448大小,然后,为了保证原始图像的空间信息,输入图像后应当直接从最后一层pooling层拿到feature。最终我们得到的feature的形状应当是512×14×14,即把原始图像划分为196个区域,每个区域是512维的feature vector,每个区域对应原图片32×32大小的区域,如下图所示:
因为在后文attention部分中将会将这问题向量和图像向量加在一起,这里我们对feature进行处理:
![]()
通过一个以tanh为激活函数的全连接层,最后得到的vector应当是与后面得到的问题的feature长度一致。
问题模型
这里使用了两种方法来提取问题特征,先讨论使用lstm来提取问题特征。
LSTM模型
作者这里使用了Sequence to Sequence中的多对一形式,问题中每个单词按照时间顺序依次输入到lstm中,在最后时刻输出该问题的表达向量,如下图所示:

在每一步中,lstm单元接受一个输入的单词xt,并且更新记忆单元ct,然后输出隐藏层状态ht,更新过程使用了门机制,分别有输入门,遗忘门,输出门和记忆单元,简单来说就是选择性遗忘,选择性输入,选择性输出。详细的更新过程如下所示:
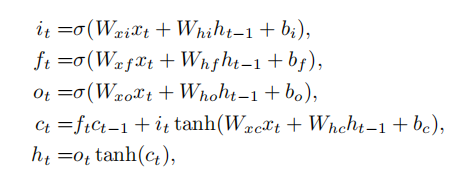
question q = [q1, ...qT ] ,qt 是t时刻输入单词的one hot vector表示,但是one-hot vector表示存在两个问题,(1)生成的向量维度往往很大,容易造成维数灾难;(2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义),所以通过一个嵌入矩阵将单词嵌入到向量空间。然后将词向量输入到lstm中。最后我们取最后一个隐藏层输出的ht 作为问题的feature。

这里的意思就是将每一个词(用qt 表示)转换成对应的embedding向量,实现方法是使用嵌入矩阵乘以单词的one hot向量得到该词的词向量。
CNN模型
与lstm方法类似,首先也需要将要输入的单词转换成词向量,将每个单词的词向量组合成一个矩阵,进行卷积操作。文中使用了三个卷积核。具体流程如下图所示:

卷积窗口的大小设置对最终的分类结果影响较大,借鉴N-gram语言模型的思想,通过提取相邻n个词进行局部特征的提取,从而捕捉上下文搭配词语的语义信息,对整个文本的语义进行表示。根据这种思想,将卷积窗口大小设置为n*m,n为窗口内词的个数,m为词向量维度。详细流程如下图所示:

将经过最大池化得到的向量连接起来得到的向量,即为问题向量。
Attention部分
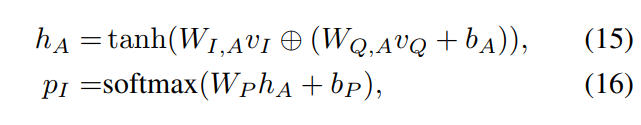
其实就是将图片和问题的feature线性变换下,然后再矩阵与向量求和(要用到框架内置的broadcasting机制),以此将文字信息和图片信息融合。最后通过对线性变换之后的图像-文本信息进行softmax来计算出图片与文字的相关性(或者说与问题相关的信息在图像的分布)。
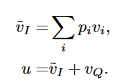
然后将pi和图像每个区域的feature相乘,就可以只保留与问题相关的信息。然后将信息叠加在一起(加权求和),最后和问题的feature相加,形成一个更加精化的查询向量,再经过一个softmax函数得到预测结果。
但是对于一些复杂的问题,一个注意力层是不够的,这时我们需要使用多个注意层迭代上述过程,每一次迭代都可以形成一个更加精确的视觉注意信息。
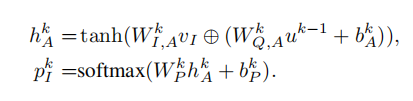
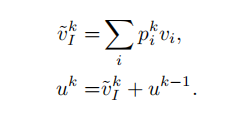
k代表第k个注意力层。u0被初始化为vQ
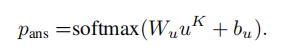
循环k次 ,使用最后一层输出的u来推断答案。
结束语
我认为对于Attention可以有三种理解。
- 首先,从数学公式上和代码实现上Attention可以理解为加权求和。
- 其次,从形式上Attention可以理解为键值查询。
- 最后,从物理意义上Attention可以理解为相似性度量