本文介绍了一个自助结账系统,该系统的主要原件是一个视觉项目计数,可以在客户结账时识别选择的商品的类别和数量,从而完成自助结账。但是该系统的训练受到域适应问题的挑战,即训练数据是单个的物品,而测试图像则是物品的集合。为了解决这个问题,作者提出了一个data priming方法。首先使用一个pre-augmentation data priming,从训练图片中消除干扰的背景,并通过porn pruning 选择真实的图像,然后进行图像合成操作。然后在post-augmentation中,首先在训练集上训练整个网络,然后使用检测和计数联合学习从测试数据中选择可靠的图像对visual item tallying 网络进行微调。具体如下:
第一步我们先来处理数据,现在我们有裁剪好的训练集(如果不裁剪,在后面的合成部分会因为和mask的尺寸不匹配导致合成效果差)、测试集和验证集,以及他们各自对应的json标注文件。现在我们先开始对训练集数据的处理:首先,因为原始的训练集图片的背景会影响网络的功能,所以我们使用mask来提取前景目标,将其用于合成图像。代码如下:
# 边缘检测 img为原始图像# -------------------------edges = detector.detectEdges(np.float32(img) / 255)# -------------------------# edge process 前景置为1,背景置为0,提取出来前景# -------------------------object_box_mask = np.zeros_like(edges, dtype=np.uint8)object_box_mask[y:y + h, x:x + w] = 1edges[(1 - object_box_mask) == 1] = 0edges[(edges < (edges.mean() * 0.5)) & (edges < 0.1)] = 0#然后对mask图像进行细化,例如膨胀和腐蚀filled = ndimage.binary_fill_holes(edges).astype(np.uint8)filled = cv2.erode(filled, np.ones((32, 32), np.uint8))filled = cv2.dilate(filled, np.ones((32, 32), np.uint8))filled = cv2.erode(filled, np.ones((8, 8), np.uint8))#使边缘光滑,提取出来前景保存图像filled = cv2.medianBlur(filled, 17)save_image = np.zeros((origin_height, origin_width), np.uint8)save_image[crop_y1:crop_y2, crop_x1:crop_x2] = np.array(filled * 255, dtype=np.uint8)cv2.imwrite(os.path.join(output_dir, os.path.basename(path).split('.')[0] + '.png'), save_image)流程图如下所示, 我们保存的即为median blur之后的mask图。

有了mask图像之后,我们开始合成图像。
现在要做的就是使用mask把前景图从训练集中分割出来用于合成。但是在合成之前,我们需要先对训练集中不可用的图片进行消除操作,为此设置了一个公式:
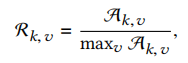
表示第k个类别中第v个视角拍摄的mask面积与第k类面积最大的mask的比值,若比值大于0.45则保留,否则抛弃。代码如下:
def sample_select_object_index(category, paths, ratio_annotations, threshold=0.45):high_threshold_paths = [path for path in paths if ratio_annotations[os.path.basename(path)] > threshold]index = random.randint(0, len(high_threshold_paths) - 1)path = high_threshold_paths[index]return path现在我们的训练集就都是有效的图片了,现在就开始合成。
# Crop according to json annotation# ---------------------------x, y, w, h = get_object_bbox(annotations[name])obj = obj.crop((x, y, x + w, y + h))mask = mask.crop((x, y, x + w, y + h))# ---------------------------# Random scale# ---------------------------scale = random.uniform(0.4, 0.7)w, h = int(w * scale), int(h * scale)obj = obj.resize((w, h), resample=Image.BILINEAR)mask = mask.resize((w, h), resample=Image.BILINEAR)# ---------------------------# Random rotate# ---------------------------angle = random.random() * 360obj = obj.rotate(angle, resample=Image.BILINEAR, expand=1)mask = mask.rotate(angle, resample=Image.BILINEAR, expand=1)# ---------------------------# Crop according to mask# ---------------------------where = np.where(np.array(mask)) #返回为true的元素的坐标位置信息y1, x1 = np.amin(where, axis=1)#每一行的最小值y2, x2 = np.amax(where, axis=1)obj = obj.crop((x1, y1, x2, y2))#左上右下mask = mask.crop((x1, y1, x2, y2))w, h = obj.width, obj.heightpad = 2pos_x, pos_y = generated_position(bg_width, bg_height, w, h, pad)start = time.time()threshold = 0.5#每个物品的遮挡率小于0.5while not check_iou(synthesize_annotations, box=(pos_x, pos_y, w, h), threshold=threshold):if (time.time() - start) > 3: # cannot find a valid position in 3 secondsstart = time.time()threshold += 0.1continuepos_x, pos_y = generated_position(bg_width, bg_height, w, h, pad)将物品粘贴到背景图上bg_img.paste(obj, box=(pos_x, pos_y), mask=mask)合成图片的步骤是首先生成一个粘贴的位置,然后使用mask把对应的前景图提取出来,粘贴到生成位置上,迭代几次形成合成图片。
现在我们有了合成图像后,就可以把他作为训练集,但是合成图像还是和真实图有些差别,为了消除这种误差,我们使用cycle-gan模型对合成图像进行渲染,使其更加真实。在渲染时,因为训练的时间特别慢,我训练了10轮就用了两个小时,因此我得到的结果不是特别好。我的做法是截取部分训练集和部分测试集作为输入,目的是训练集到测试集,然后得到预训练模型,使用预训练模型再对训练集进行渲染。

渲染完毕后,我们的训练集就准备好了,开始训练,该项目基于maskrcnn-benchmark详见maskrcnn主干网络,集成了检测器,rpn以及roi,可以进行扩展。贴上我的训练结果,训练结束后,会保存一个预训练模型(.pth)文件,我可以用整个模型来进行测试或者运行一个demo。
t
接下来我们使用这个预训练模型来进行测试生成Pseudo 文件
#计数器和被检测到到的物体的个数相同,该图片才会被选择
density = 0.0if has_density_map:ann = dataset.get_annotation(img_info['id'])density_map = prediction.get_field('density_map').numpy()density = density_map.sum()if round(density) == len(ann):##计数correct += 1mae += abs(density - len(ann))if generate_pseudo_labels and has_density_map:image_result = {'bbox': [],'width': image_width,'height': image_height,'id': img_info['id'],'file_name': img_info['file_name'],}for i in range(len(prediction)):score = scores[i]box = bboxes[i]label = labels[i]if score > 0.95:x, y, width, height = float(box[0]), float(box[1]), float(box[2] - box[0]), float(box[3] - box[1])image_result['bbox'].append((int(label), x, y, width, height))if len(image_result['bbox']) >= 3 and len(image_result['bbox']) == round(density):annotations.append(image_result)测试结束后,我们会得到被选择的图片,再使用这些数据对网主干网络和检测器进行微调。该网络结构图如下:

我写了一个demo使用预训练模型对图片进行预测,因为时间原因,训练轮数较少,有的物品没有被检测到。

此类问题牵扯到OSR问题,可以从osr的角度来对此项目进行优化。